Clear Sky Science · fr
Une approche conjointe de prédiction de spans-entités avec méta-apprentissage génératif et cross-lingue pour la RDN à faibles ressources en japonais
Apprendre aux ordinateurs à repérer les noms dans le texte japonais
L'information en ligne regorge de noms de personnes, de lieux, d'entreprises et de dates, et des logiciels capables d'identifier automatiquement ces indices « qui, où et quand » sont essentiels pour les moteurs de recherche, la finance, la médecine, et plus encore. Mais alors que l'anglais dispose d'abondantes données pour entraîner de tels systèmes, le japonais présente un défi particulier : il n'y a pas d'espaces entre les mots et son écriture est complexe. Cette étude présente une nouvelle méthode, appelée MAML‑ProtoNet++, qui aide les ordinateurs à reconnaître les entités nommées en japonais même lorsque seulement une poignée d'exemples annotés est disponible.
Pourquoi le japonais est particulièrement délicat
Dans de nombreuses langues européennes, les espaces séparent les mots, de sorte que les algorithmes peuvent plus facilement deviner où un terme se termine et où un autre commence. Les phrases japonaises, en revanche, sont écrites comme des flux continus de caractères. Les noms peuvent être longs, composés de plusieurs éléments, et changer de forme selon le contexte. Les réseaux neuronaux traditionnels, même les modèles multilingues puissants, ont du mal à décider où commence et où finit une entité et quel type elle est. Ils dépendent également fortement de grands jeux de données annotés, qui sont rares pour le japonais. En conséquence, les systèmes existants découpent souvent une même organisation en deux parties, manquent des relations à longue distance dans une phrase ou transfèrent mal l'entraînement basé sur l'anglais au texte japonais.
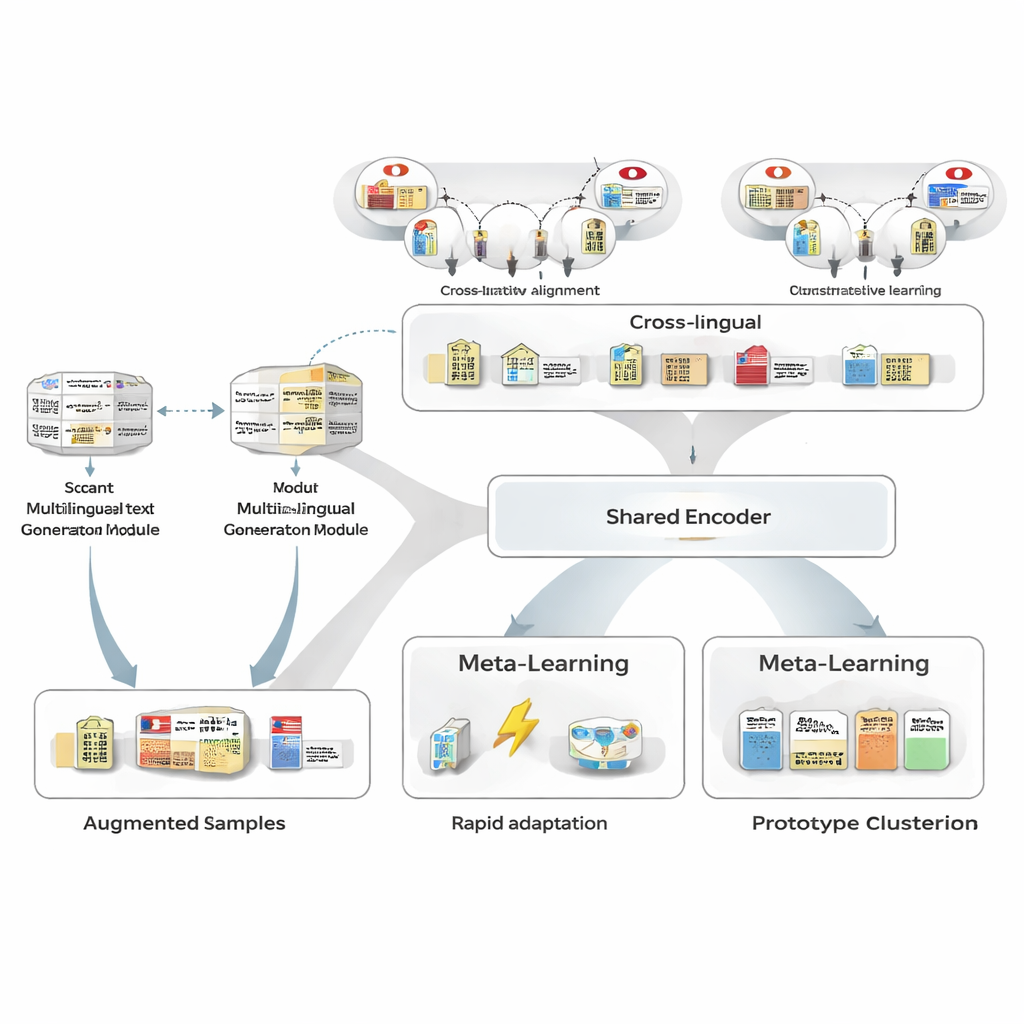
Générer davantage d'exemples sans multiplier les annotations humaines
Pour pallier le manque de données d'entraînement, les auteurs utilisent d'abord un générateur de texte multilingue pour réécrire les quelques phrases japonaises annotées dont ils disposent. Le générateur produit de nouvelles versions qui conservent les mêmes entités et types mais varient la formulation : reformuler des phrases, remplacer des mentions d'entités par des mentions similaires ou modifier le contexte environnant. Un pipeline de filtrage soigneux écarte ensuite les réécritures mauvaises à l'aide de trois tests : une vérification de confiance par un tagger distinct, un contrôle que les frontières et les types d'entité correspondent toujours à l'original, et un test de similarité sémantique qui évite les quasi-dupliqués. Les phrases synthétiques retenues élargissent la gamme de motifs que voit le modèle, améliorant sa robustesse tout en maintenant le bruit d'étiquetage très bas.
Emprunter de la force entre les langues
Ensuite, le cadre apprend à aligner les entités japonaises avec leurs homologues dans d'autres langues à l'aide d'une grande base de connaissances. Des paires telles que « Tokyo Metropolitan Government » en japonais et en chinois sont projetées dans un espace mathématique partagé afin que les entités correspondantes se rapprochent et que les non liées s'éloignent. Ce préentraînement contrastif ne cherche pas à encoder tout le savoir du domaine ; il donne plutôt au modèle une ossature agnostique à la langue pour que des concepts similaires paraissent similaires quelle que soit la langue. Plus tard, lors de l'entraînement spécifique à la tâche, la supervision japonaise peut remodeler cet espace, mais le prior cross-lingue facilite la généralisation à partir de peu d'exemples et augmente la similarité entre paires d'entités japonais‑anglais de niveaux modérés à très élevés.
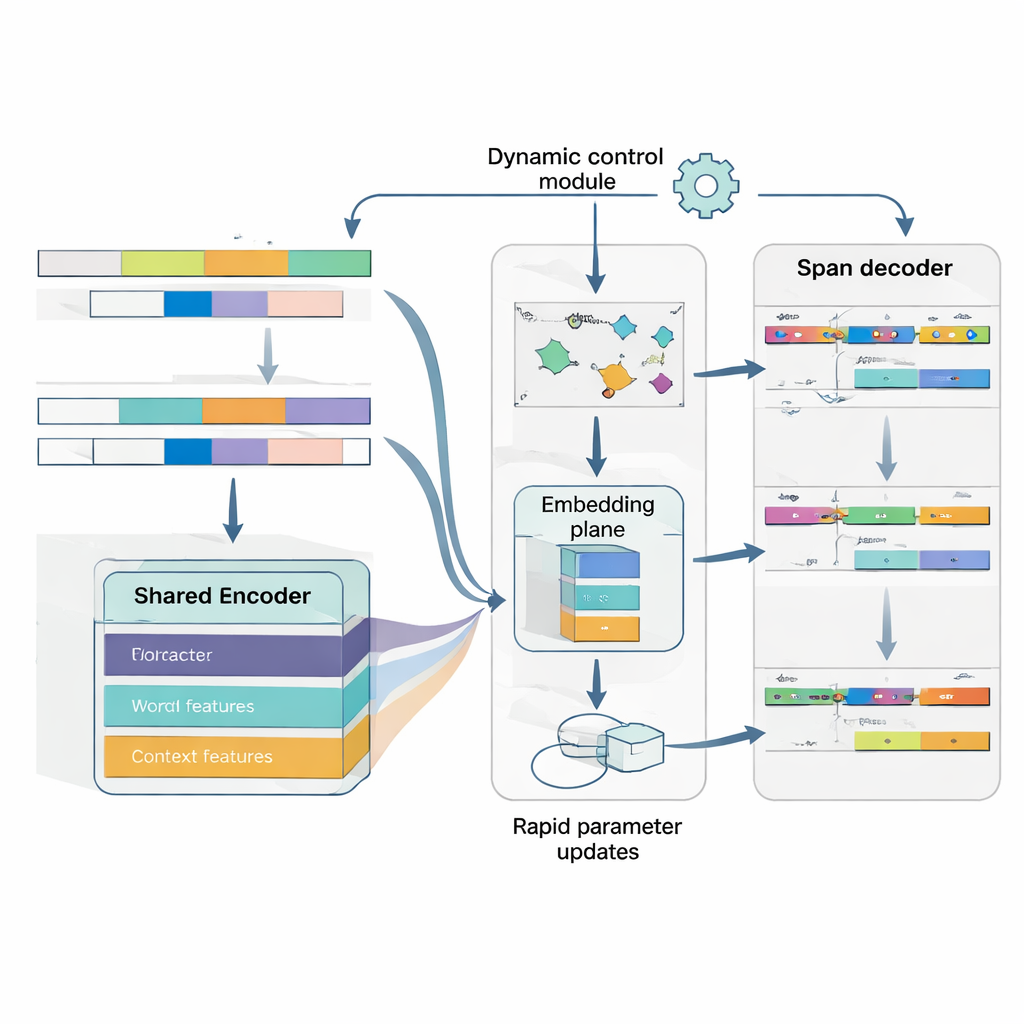
Apprendre à apprendre à partir de seulement quelques exemples
Le cœur de MAML‑ProtoNet++ est une stratégie de « learning to learn ». Plutôt que de s'entraîner une fois sur un énorme jeu de données, le modèle s'exerce sur de nombreuses petites tâches qui imitent de réels scénarios few-shot : donné un petit nombre de phrases annotées et un petit jeu de test, s'adapter rapidement. Deux idées bien connues sont combinées. D'une part, une composante d'adaptation rapide ajuste les paramètres du modèle par quelques pas de gradient afin qu'il puisse se calibrer sur chaque nouvelle tâche. D'autre part, une composante basée sur des prototypes construit un vecteur représentatif pour chaque type d'entité et classe les nouveaux spans selon leur distance à ces prototypes. Un réseau de contrôle séparé évalue la difficulté apparente d'une tâche — sur la base de ses quelques exemples annotés — et ajuste automatiquement les taux d'apprentissage, les échelles de distance et la confiance accordée aux différents niveaux de caractéristiques (caractères, mots ou contexte complet). Ce contrôle dynamique aide le système à rester stable et efficace même lorsque les tâches varient considérablement.
Comprendre à la fois où se trouve une entité et ce qu'elle est
Enfin, le modèle traite la détection des frontières et l'affectation des types comme un seul problème coordonné plutôt que deux étapes séparées. Il prédit d'abord les positions de début probables des entités dans une phrase, puis, conditionné sur ces débuts, il prédit des positions de fin plausibles, et enfin il classe les spans ainsi obtenus en types d'entités. Plusieurs spans superposés peuvent être considérés, mais des règles de notation favorisent les plus cohérents. En modélisant explicitement la dépendance entre début, fin et catégorie, le système devient meilleur pour gérer les entités imbriquées ou ambiguës — un obstacle courant en japonais. Une fonction de perte conjointe entraîne ces trois décisions ensemble, améliorant à la fois la précision des frontières et les étiquettes finales.
Que signifient ces résultats en pratique
Testé sur plusieurs benchmarks japonais simulant la situation de seulement cinq exemples annotés par type d'entité, MAML‑ProtoNet++ surpasse des baselines solides, y compris l'ajustement standard, des méthodes méta-apprenantes antérieures et l'entraînement contrastif seul. Il atteint un score F1 macro d'environ 0,77 dans le cadre le plus difficile et obtient une précision notable sur les positions exactes de début et de fin des entités. L'approche se transfère également bien à de nouveaux domaines, tels que le biomédical et les textes d'actualité, sans réentraînement majeur. Pour le lecteur non spécialiste, la conclusion est que les auteurs ont construit un système compact et efficace capable d'apprendre à repérer les noms et autres termes clés dans le texte japonais à partir de très peu d'exemples, en générant intelligemment des exemples supplémentaires, en empruntant des indices cross-lingues et en ajustant son apprentissage à la volée.
Citation: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Mots-clés: reconnaissance d'entités nommées en japonais, apprentissage en few-shot, TAL cross-lingue, méta-apprentissage, augmentation de données