Clear Sky Science · zh
一种通过预处理增强的堆叠分类器,用于在多样化数据集上实现广义心血管疾病检测
为何提前检测心脏风险至关重要
心脏和血管疾病仍然是全球首要杀手,然而许多人在危机发生前并无明显预警信号。医生越来越多地依赖计算机程序来从患者数据中识别细微的风险模式,以便在症状出现很久之前进行干预。本研究探讨了一种新的训练方法,使这些程序在面对类型迥异的病历时仍能保持准确——这是让工具在不同医院和社区中可靠运行的关键一步。
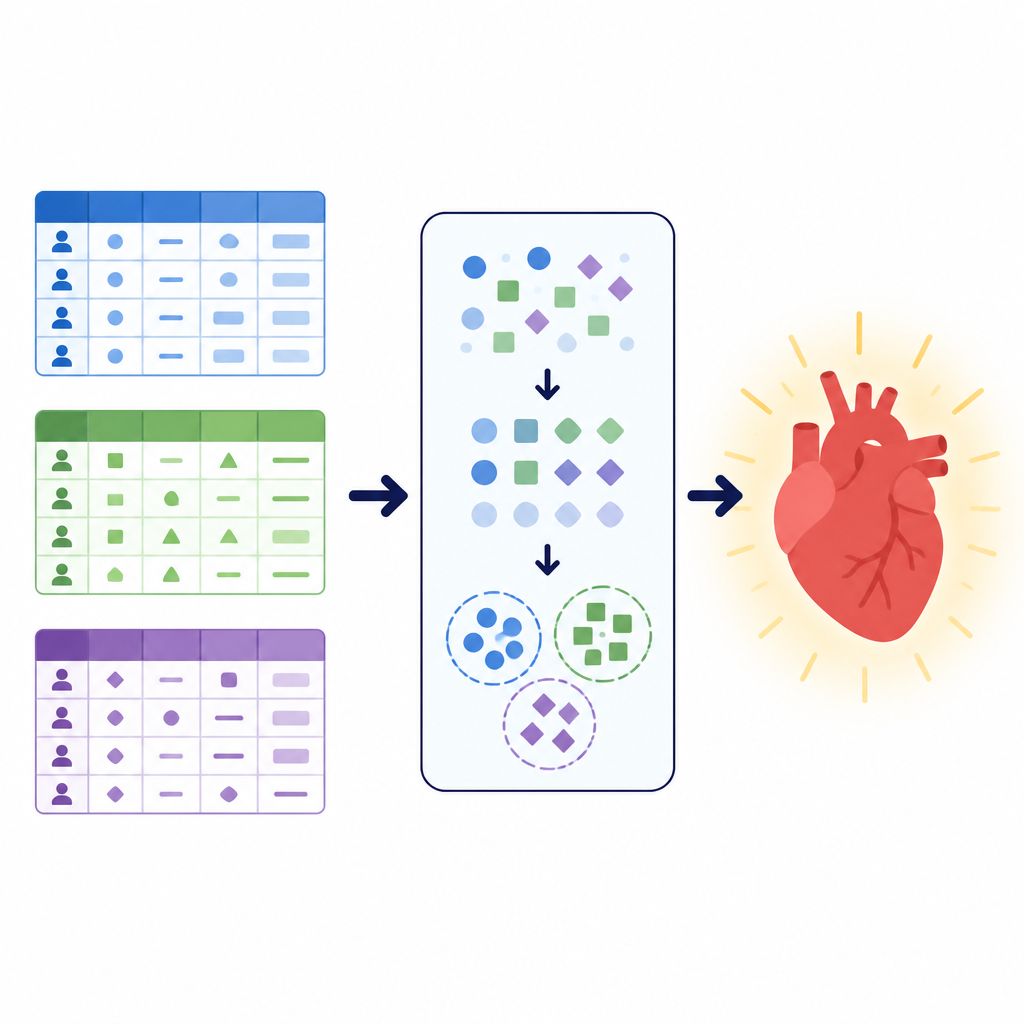
不同的数据,同样的健康问题
研究者聚焦于一项简单但重要的任务:判断患者是否可能患有心血管疾病。他们使用了三份大型数据集,每份都用不同方式描述患者。一份汇集了门诊检测结果,如血压、胆固醇和运动心电图;另一份将身高体重等基础测量与吸烟和活动等生活方式信息混合;第三份来自巴基斯坦一家医院的本地数据侧重于类似调查问卷的问题,包含一般健康、睡眠、慢性病以及吸烟或电子烟使用等信息,并辅以少量临床检查。这些数据集合计覆盖了超过26万条患者记录,展现了真实世界健康数据在结构、清洁度以及病患与健康个体比例上的差异。
清理与重塑患者信息
在训练任何模型之前,团队设计了一个仔细的预处理流程来清理并重塑数据。他们去除了重复条目,对本地数据集中存在缺失值的记录予以删除,并对公开大型数据集中血压与体型的极端离群值进行了修剪。将年龄从天数转换为年,并将患者分入年龄段,以便在原始以不同方式存储年龄的数据集中更容易学习模式。计算了新的组合特征,如体质指数和平均动脉压,并将其放入简单类别以降低复杂性。所有类别型回答(例如吸烟状态或胸痛类型)仅在数据分割为训练集与测试集之后才转换为数值编码,防止隐含信息在两者之间泄露。
通过聚类发现隐藏的患者群体
为了赋予模型额外的结构信息,作者使用了一种称为聚类的技术。聚类并不使用诊断标签,而是寻找数据中的自然分组。在此,团队应用了一种适用于类别型信息的方法,将每个数据集划分为少量聚类,并将聚类分配作为新特征加入。这一额外信号捕捉了诸如症状或生活方式常见组合等模式,可能并不明显于原始变量。通过同时学习原始特征和这些发现的群体,后续的预测模型能够在更有组织的患者群体上聚焦。
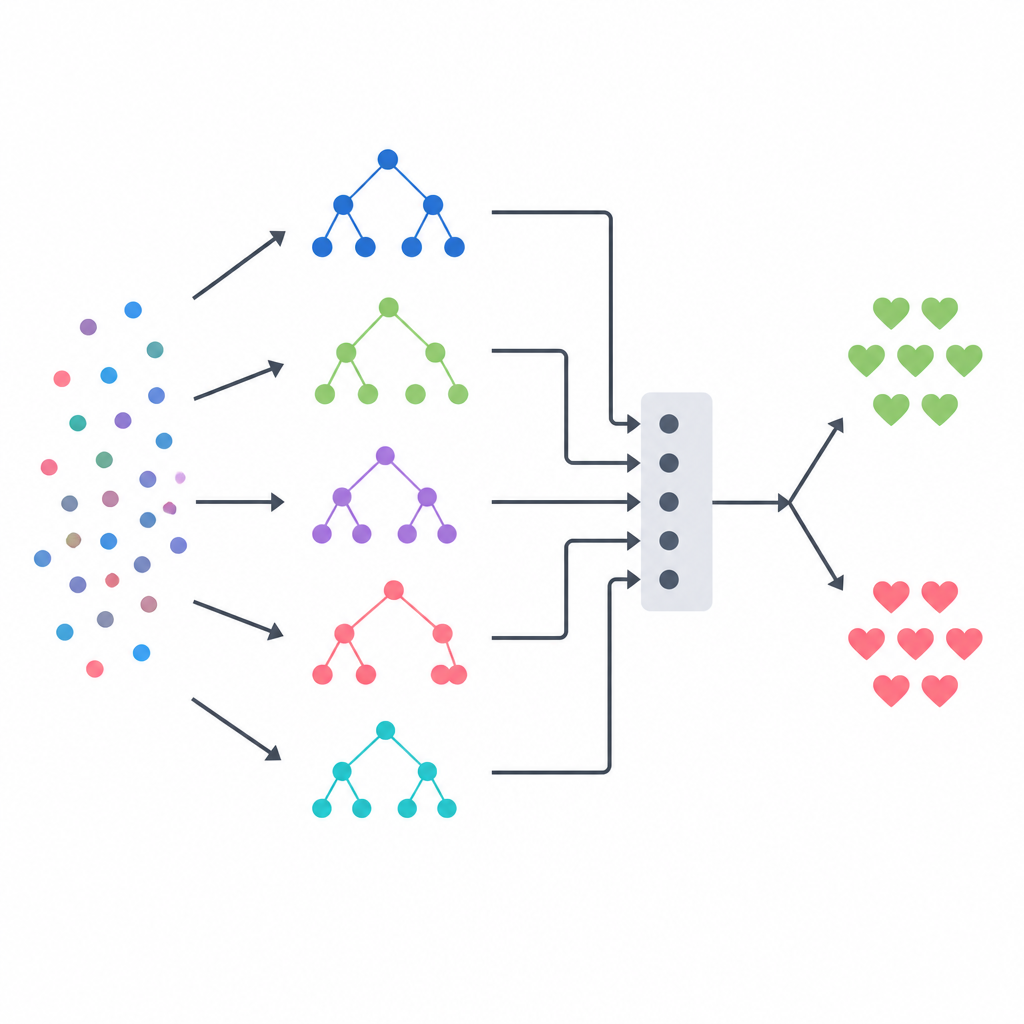
将多个模型融合为一个决策
方法的核心是一种堆叠集成(stacking),它像由多位背景不同的专家组成的小组,由最终裁判做出决策。三种基于树的方法——决策树、随机森林和极度随机树系统——分别为每位患者输出疾病概率估计。它们的输出被合并为一个小的汇总向量,传入一个逻辑回归模型,该模型学习在不同情形下应多大程度信任每个基础模型。为避免给这个“裁判”提供不公平的提示,团队采用了严格的交叉验证方案构建训练数据,使每个基础模型首先在其未见过的患者上进行预测。该设计旨在捕捉各方法的优势,同时减少过拟合。
该方法在各数据集上的表现如何
堆叠模型与常见的机器学习方法、一种流行的提升方法以及若干深度学习架构进行了比较,包括前馈神经网络、卷积网络和一种现代的表格数据导向网络TabNet。在临床信息丰富但规模中等的数据集 I 上,堆叠模型达到了约93%的准确率,并优于所有基线方法。在大型且噪声较多的数据集 II 上,大多数模型的准确率集中在71%到72%;此处堆叠模型与最佳表现者匹配,并显著优于卷积网络。在结构化的本地数据集 III 上,几乎所有高级模型(包括堆叠)都取得了约99%的准确率,表明在清洗后该数据本身易于区分。通过不同随机种子重复实验产生了窄的置信区间,统计检验也确认堆叠相较多个竞争方法的提升不太可能是偶然所得。
这对未来心脏风险工具意味着什么
对于非专业读者,核心信息是:我们如何准备数据并组合数据驱动模型,往往与选择某一特定算法同样重要。通过强调细致的清理、周到的特征设计、防止信息泄露以及多种互补模型的融合,本研究展示了一条切实可行的路径,使心脏病预测系统在患者群体或数据格式变化时保持可靠。尽管仍需在更多医院中测试这些系统并使其高效且具可解释性以便日常使用,结果表明,设计良好的集成模型有望成为帮助临床医生更早、更一致识别心血管风险的稳健决策辅助工具。
引用: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
关键词: 心血管疾病预测, 机器学习, 集成模型, 临床数据, 风险检测