Clear Sky Science · pl
Ulepszony wstępnie klasyfikator stackingowy do uogólnionej detekcji chorób sercowo-naczyniowych w różnych zbiorach danych
Dlaczego wczesne wykrywanie ryzyka sercowego ma znaczenie
Choroby serca i naczyń krwionośnych pozostają główną przyczyną zgonów na świecie, a wiele osób nie wykazuje objawów aż do wystąpienia kryzysu. Lekarze coraz częściej sięgają po programy komputerowe, aby wychwycić subtelne wzorce ryzyka w danych pacjentów na długo przed pojawieniem się objawów. W tym badaniu zbadano nowy sposób trenowania takich systemów, aby zachowały dokładność wobec bardzo różnych rodzajów dokumentacji medycznej — kluczowy krok w stronę narzędzi działających niezawodnie w wielu szpitalach i społecznościach.
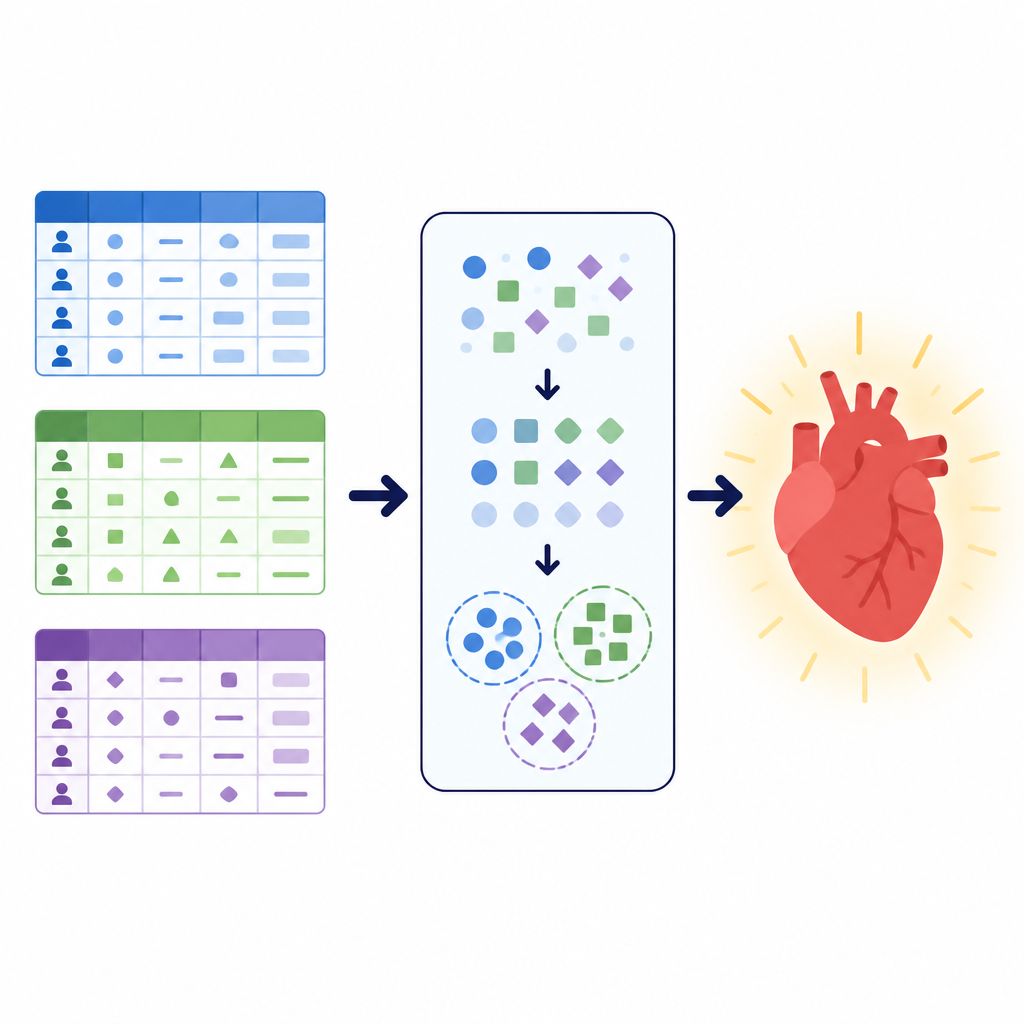
Różne dane, to samo pytanie o zdrowie
Badacze skupili się na prostym, lecz istotnym zadaniu: zdecydowaniu, czy pacjent prawdopodobnie ma chorobę sercowo-naczyniową, czy nie. Pracowali na trzech dużych zbiorach danych, z których każdy opisywał pacjentów w inny sposób. Jeden łączył wyniki badań klinicznych, takie jak ciśnienie krwi, cholesterol i wysiłkowe EKG. Inny mieszał podstawowe pomiary, jak wzrost i waga, z informacjami o stylu życia, takimi jak palenie czy aktywność. Trzeci, lokalny zbiór z szpitala w Pakistanie, kładł nacisk na ankietowe pytania o ogólny stan zdrowia, sen, choroby przewlekłe oraz palenie lub używanie e-papierosów, obok kilku badań klinicznych. Razem te zbiory obejmowały ponad 260 000 rekordów pacjentów i ilustrowały, jak dane zdrowotne z prawdziwego świata mogą różnić się strukturą, czystością i proporcjami między przypadkami chorych i zdrowych.
Czyszczenie i przekształcanie danych pacjentów
Zanim przystąpiono do trenowania modeli, zespół zaprojektował staranny potok wstępnego przetwarzania w celu oczyszczenia i przekształcenia danych. Usunięto duplikaty, odrzucono rekordy z brakującymi wartościami w zbiorze lokalnym i obcięto skrajne odchylenia w wartościach ciśnienia krwi i wymiarów ciała w większym zbiorze publicznym. Wiek przeliczono z dni na lata, a następnie pogrupowano pacjentów w przedziały wiekowe, by ułatwić wychwytywanie wzorców w zbiorach, które początkowo przechowywały wiek w różny sposób. Obliczono nowe cechy złożone, takie jak wskaźnik masy ciała i średnie ciśnienie tętnicze, i przypisano je do prostych kategorii, aby zmniejszyć złożoność. Wszystkie odpowiedzi kategoryczne, np. status palenia czy rodzaj bólu w klatce piersiowej, zamieniono na kody numeryczne dopiero po podziale danych na zbiory treningowe i testowe, zapobiegając przeciekowi informacji między nimi.
Wykrywanie ukrytych grup pacjentów przez klastrowanie
Aby nadać modelom dodatkową strukturę, autorzy zastosowali technikę zwaną klastrowaniem. Zamiast pytać, czy ktoś ma chorobę, klastrowanie szuka naturalnych grup w danych bez użycia etykiety rozpoznania. W tym przypadku zespół użył metody odpowiedniej dla informacji kategorycznych, aby podzielić każdy zbiór na niewielką liczbę klastrów, a następnie dodał przypisanie do klastra jako nową cechę. Ten dodatkowy sygnał wychwytuje wzorce, takie jak częste kombinacje objawów lub czynników stylu życia, które mogą nie być oczywiste z oryginalnych zmiennych. Ucząc się zarówno z pierwotnych cech, jak i z tych odkrytych grup, późniejsze modele predykcyjne mogły skupić się na bardziej uporządkowanych wersjach populacji pacjentów.
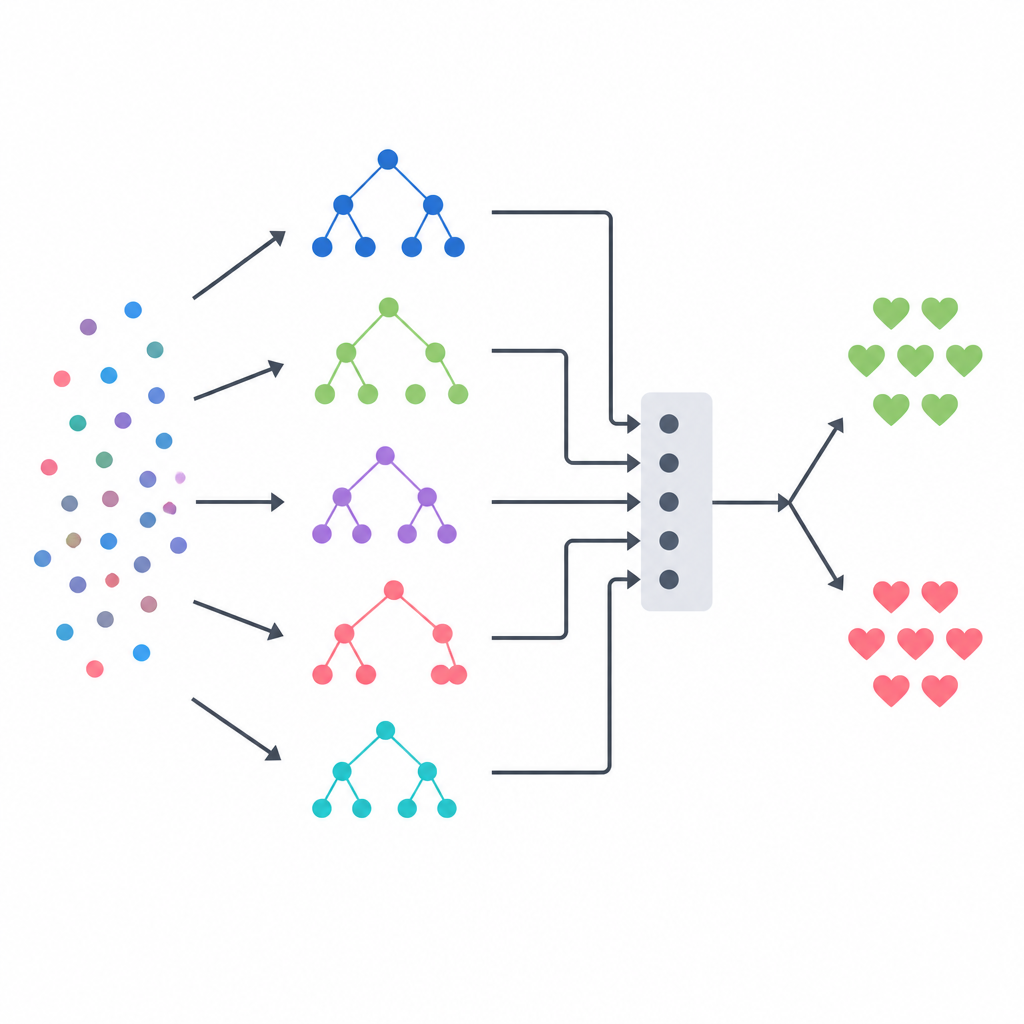
Łączenie kilku modeli w jedną decyzję
Rdzeniem podejścia jest ensemble stackingowy, który działa jak panel zróżnicowanych ekspertów kierowanych przez ostatecznego sędziego. Trzy modele oparte na drzewach — drzewo decyzyjne, las losowy i system silnie zrandomizowanych drzew — każdy z nich generuje własne estymaty prawdopodobieństwa choroby dla każdego pacjenta. Ich wyjścia są następnie łączone w mały wektor podsumowujący, który trafia do regresji logistycznej uczącej się, ile ufać każdemu z modeli bazowych w różnych sytuacjach. Aby nie dać temu sędziemu niesprawiedliwych wskazówek, zespół zbudował dane treningowe używając ścisłego schematu walidacji krzyżowej, w którym każdy model bazowy najpierw przewiduje dla pacjentów, których wcześniej nie widział. Ten projekt ma na celu uchwycenie mocnych stron każdej metody przy jednoczesnym zmniejszeniu przeuczenia.
Jak metoda sprawdziła się w różnych zbiorach
Model stackingowy porównano z powszechnymi metodami uczenia maszynowego, popularnym podejściem boostingowym oraz kilkoma architekturami głębokiego uczenia, w tym sieciami feedforward, sieciami konwolucyjnymi i nowoczesną siecią tabelaryczną znaną jako TabNet. W klinicznie bogatym, ale umiarkowanie dużym Zbiorze I stacking osiągnął około 93 procent dokładności i przewyższył wszystkie metody odniesienia. W dużym i zaszumionym Zbiorze II większość modeli oscylowała wokół 71–72 procent dokładności; tutaj stacking dorównał najlepszym wykonawcom i wyraźnie przewyższył sieć konwolucyjną. W uporządkowanym, lokalnym Zbiorze III prawie wszystkie zaawansowane modele, w tym stacking, osiągnęły około 99 procent dokładności, co pokazuje, że dane same w sobie były łatwe do rozdzielenia po oczyszczeniu. Powtórzenia eksperymentów z różnymi ziarnami losowości dawały wąskie przedziały ufności, a test statystyczny potwierdził, że zyski stackingu względem kilku rywali są mało prawdopodobne do przypisania przypadkowi.
Co to oznacza dla przyszłych narzędzi oceny ryzyka sercowego
Dla osób niebędących specjalistami kluczowy komunikat jest taki, że sposób przygotowania i łączenia modeli opartych na danych może mieć równie duże znaczenie jak wybór pojedynczego algorytmu. Podkreślając staranne czyszczenie, przemyślany projekt cech, zabezpieczenia przed przeciekiem informacji oraz łączenie wielu komplementarnych modeli, to badanie pokazuje praktyczną drogę do systemów przewidywania chorób sercowo-naczyniowych, które pozostają niezawodne przy zmianie populacji pacjentów lub formatu danych. Choć potrzebne są dalsze testy takich systemów w różnych szpitalach oraz prace nad ich efektywnością i wyjaśnialnością do codziennego użytku, wyniki sugerują, że dobrze zaprojektowane zespoły modeli mogą stać się solidnymi narzędziami wspomagającymi decyzje, pomagając klinicystom wcześniej i bardziej konsekwentnie identyfikować ryzyko sercowe.
Cytowanie: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Słowa kluczowe: predykcja chorób sercowo-naczyniowych, uczenie maszynowe, modele zespołowe, dane kliniczne, wykrywanie ryzyka