Clear Sky Science · ar
مصنف تجميعي معزز بالمعالجة المسبقة لاكتشاف الأمراض القلبية الوعائية بطريقة عامة عبر مجموعات بيانات متنوعة
لماذا يهم الكشف المبكر عن مخاطر القلب
تظل أمراض القلب والأوعية الدموية القاتل الرئيسي في العالم، ومع ذلك كثير من الأشخاص لا تظهر عليهم علامات إنذار قبل حدوث أزمة. يلجأ الأطباء بشكل متزايد إلى برامج حاسوبية لاكتشاف أنماط مخاطر دقيقة في بيانات المرضى قبل ظهور الأعراض بفترة طويلة. تستكشف هذه الدراسة طريقة جديدة لتدريب مثل هذه البرامج بحيث تظل دقيقة عندما تواجه أنواعًا مختلفة تمامًا من السجلات الطبية، وهي خطوة أساسية نحو أدوات تعمل بشكل موثوق في مستشفيات ومجتمعات متعددة.
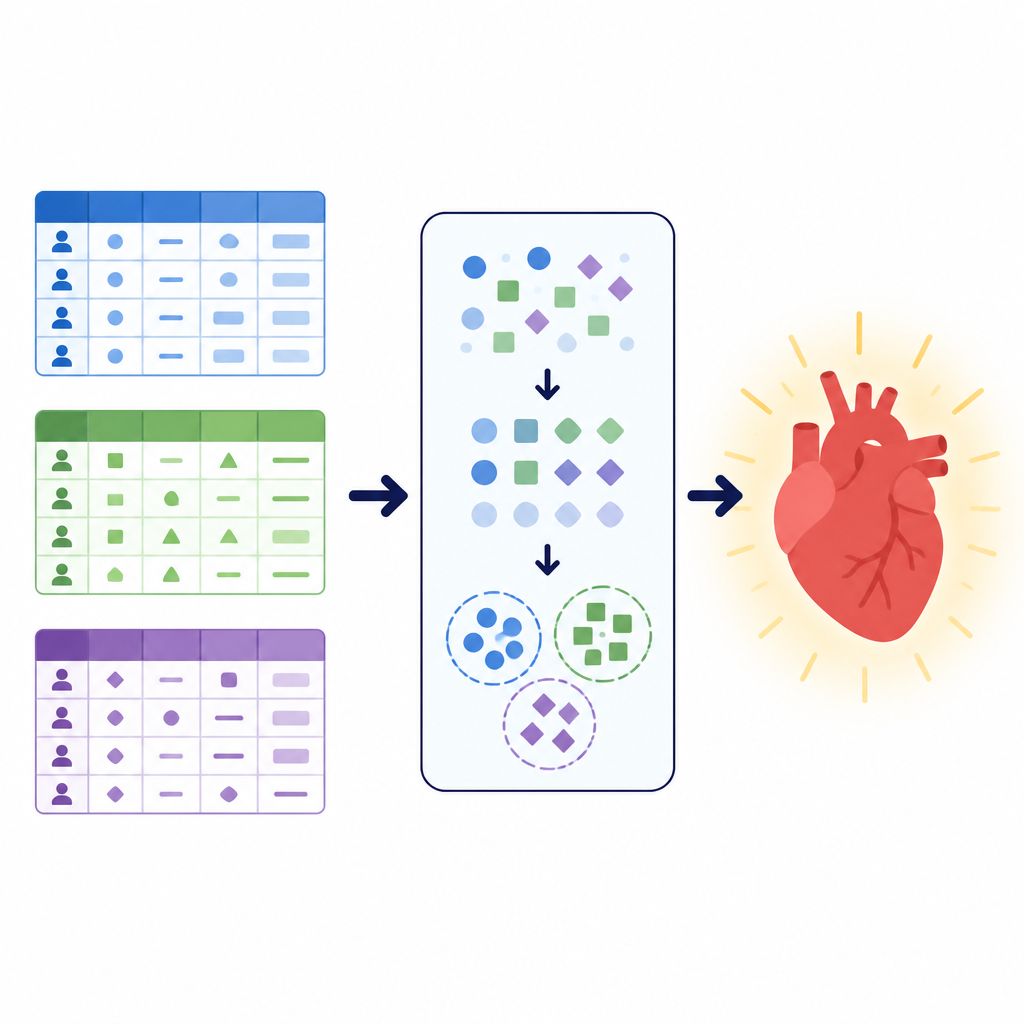
بيانات مختلفة، نفس السؤال الصحي
ركز الباحثون على مهمة بسيطة لكنها حيوية: تقرير ما إذا كان المريض من المرجح أن يكون مصابًا بمرض قلبي وعائي أم لا. عملوا مع ثلاث مجموعات بيانات كبيرة، كل واحدة تصف المرضى بطريقة مختلفة. جمعت إحدى المجموعات نتائج فحوصات عيادية مثل ضغط الدم والكوليسترول وتصوير القلب الكهربائي أثناء التمرين. ضمّت أخرى قياسات أساسية مثل الطول والوزن بالإضافة إلى معلومات نمط الحياة مثل التدخين والنشاط. ركزت مجموعة محلية ثالثة من مستشفى في باكستان على أسئلة استطلاعية عن الصحة العامة والنوم والأمراض المزمنة واستخدام السجائر أو السجائر الإلكترونية، إلى جانب بعض الفحوصات السريرية. معًا غطت هذه المجموعات أكثر من 260,000 سجل مريض وأظهرت كيف يمكن أن تختلف بيانات الصحة الواقعية في البنية والنقاء وتوازن الحالات المريضة والسليمة.
تنظيف وإعادة تشكيل معلومات المرضى
قبل تدريب أي نماذج، صمّم الفريق خط معالجة مسبقة دقيق لتنظيف وإعادة تشكيل البيانات. أزالوا الإدخالات المكررة، واستبعدوا السجلات ذات القيم المفقودة في المجموعة المحلية، وقصّوا القيم المتطرفة الشديدة في ضغط الدم ومقاييس الجسم من مجموعة البيانات العامة الأكبر. حوّلوا العمر من أيام إلى سنوات ثم جمعوا المرضى في فئات عمرية لتسهيل تعلم الأنماط عبر مجموعات البيانات التي خزنت العمر بطرق مختلفة أصلاً. حُسبت ميزات مركبة جديدة مثل مؤشر كتلة الجسم ومتوسط ضغط الدم الشرياني ووُضعت في فئات بسيطة لتقليل التعقيد. تحولت جميع الإجابات الصنفية، مثل حالة التدخين أو نوع ألم الصدر، إلى رموز رقمية فقط بعد تقسيم البيانات إلى مجموعات تدريب واختبار، ما منع تسرب معلومات مخفية بينها.
اكتشاف مجموعات مرضى خفية باستخدام التجميع العنقودي
لمنح النماذج إحساسًا إضافيًا بالهيكلة، استخدم المؤلفون تقنية تُسمى التجميع العنقودي. بدلاً من سؤال ما إذا كان لدى شخص ما مرض، يبحث التجميع عن مجموعات طبيعية في البيانات دون استخدام تسمية التشخيص. هنا طبّق الفريق طريقة مناسبة للمعلومات الصنفية لتقسيم كل مجموعة بيانات إلى عدد قليل من العناقيد ثم أضافوا تخصيص العنقود كميزة جديدة. تلتقط هذه الإشارة الإضافية أنماطًا مثل تراكيب الأعراض أو عوامل نمط الحياة الشائعة التي قد لا تكون واضحة من المتغيرات الأصلية وحدها. من خلال التعلم من كل من الميزات الأصلية وهذه المجموعات المكتشفة، يمكن لنماذج التنبؤ اللاحقة التركيز على نسخ منظمة أكثر من تجمعات المرضى.
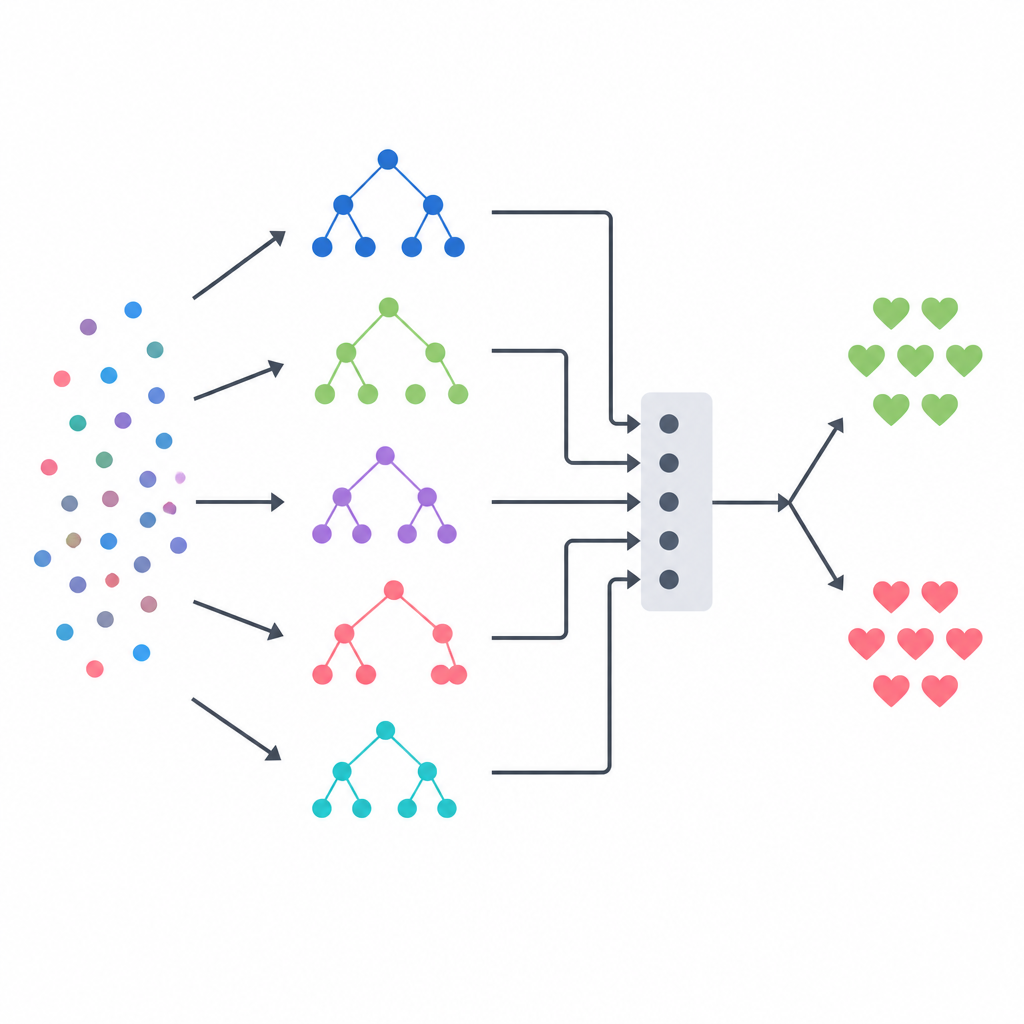
دمج عدة نماذج لاتخاذ قرار واحد
الركيزة الأساسية للطريقة هي تجميع متعدد المستويات (stacking)، الذي يعمل مثل لجنة من خبراء متنوعين يحكمهم مُحكّم نهائي. يقوم ثلاثة نماذج مبنية على الأشجار — شجرة قرار، وغابة عشوائية، ونظام أشجار عشوائية متطرفة — كل منها بإصدار تقديرات احتمالية للإصابة لدى كل مريض. تُجمع مخرجاتهم في متجه ملخّص صغير يُمرّر إلى نموذج انحدار لوجستي يتعلم مقدار الثقة الواجب منحها لكل نموذج أساسي في مواقف مختلفة. لتفادي إعطاء هذا المحكّم لمحات غير عادلة، بنى الفريق بيانات التدريب باستخدام مخطط تحقق متقاطع صارم، حيث يتنبأ كل نموذج أساسي أولًا على مرضى لم يرهم من قبل. يهدف هذا التصميم إلى التقاط نقاط قوة كل طريقة مع تقليل الإفراط في التكيّف.
مدى أداء الطريقة عبر مجموعات البيانات
اختُبر النموذج المُجمّع مقابل طرق تعلم آلي شائعة، ونهج تعزيز شعبي، وعدة بنى تعلم عميق، بما في ذلك الشبكات العصبية الأمامية، والشبكات الالتفافية، وشبكة موجهة للجداول حديثة تُعرف باسم TabNet. على مجموعة البيانات السريرية الغنية ولكن متوسطة الحجم (المجموعة I)، بلغ دقّة التجميع نحو 93% وتفوّق على كل النماذج الأساسية. على مجموعة البيانات الكبيرة والمشحونة بالضوضاء (المجموعة II)، تراوحت دقّات معظم النماذج حوالي 71 إلى 72%؛ هنا لم يغب التجميع عن أفضل المؤدين وتفوّق بوضوح على الشبكة الالتفافية. على المجموعة المحلية المهيكلة (المجموعة III)، حققت تقريبًا كل النماذج المتقدمة، بما في ذلك التجميع، نحو 99% دقة، ما يدل على أن البيانات نفسها كانت سهلة الفصل بعد التنظيف. أعاد تكرار التجارب مع بذور عشوائية مختلفة إنتاج فواصل ثقة ضيقة، وأكد اختبار إحصائي أن مكاسب التجميع على عدة منافسين من غير المرجح أن تكون نتيجة الصدفة.
ماذا يعني هذا لأدوات تقييم مخاطر القلب المستقبلية
بالنسبة لغير المتخصصين، الرسالة الأساسية هي أن كيفية إعدادنا ودمجنا للنماذج المعتمدة على البيانات يمكن أن تكون مهمة بقدر أهمية اختيار أي خوارزمية منفردة. من خلال التركيز على التنظيف الدقيق، وتصميم الميزات المدروس، والحماية من تسرب المعلومات، ودمج عدة نماذج تكاملية، توضح هذه الدراسة مسارًا عمليًا نحو أنظمة توقع أمراض القلب التي تظل موثوقة عندما يتغير تجمع المرضى أو تنسيق البيانات. بينما لا يزال هناك المزيد من العمل لاختبار مثل هذه الأنظمة عبر المستشفيات وجعلها فعّالة وقابلة للتفسير للاستخدام اليومي، تشير النتائج إلى أن التجميعات المصممة جيدًا قد تصبح مساعدات قرار متينة لمساعدة الأطباء على تحديد المخاطر القلبية مبكرًا وبشكل أكثر اتساقًا.
الاستشهاد: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
الكلمات المفتاحية: التنبؤ بأمراض القلب والأوعية الدموية, التعلّم الآلي, نماذج التجميع, البيانات السريرية, كشف المخاطر