Clear Sky Science · nl
Een preprocessing-versterkte stacking-classifier voor gegeneraliseerde detectie van hart- en vaatziekten over diverse datasets
Waarom vroege detectie van hartrisico belangrijk is
Ziekten van hart en bloedvaten blijven ’s werelds belangrijkste doodsoorzaak, terwijl veel mensen geen waarschuwingssignalen hebben totdat er een crisis optreedt. Artsen wenden zich steeds vaker tot computermethoden om subtiele risicopatronen in patiëntgegevens te vinden lang voordat symptomen zichtbaar worden. Deze studie onderzoekt een nieuwe manier om dergelijke systemen te trainen zodat ze nauwkeurig blijven wanneer ze geconfronteerd worden met zeer verschillende typen medische dossiers — een cruciale stap naar hulpmiddelen die betrouwbaar werken in uiteenlopende ziekenhuizen en gemeenschappen.
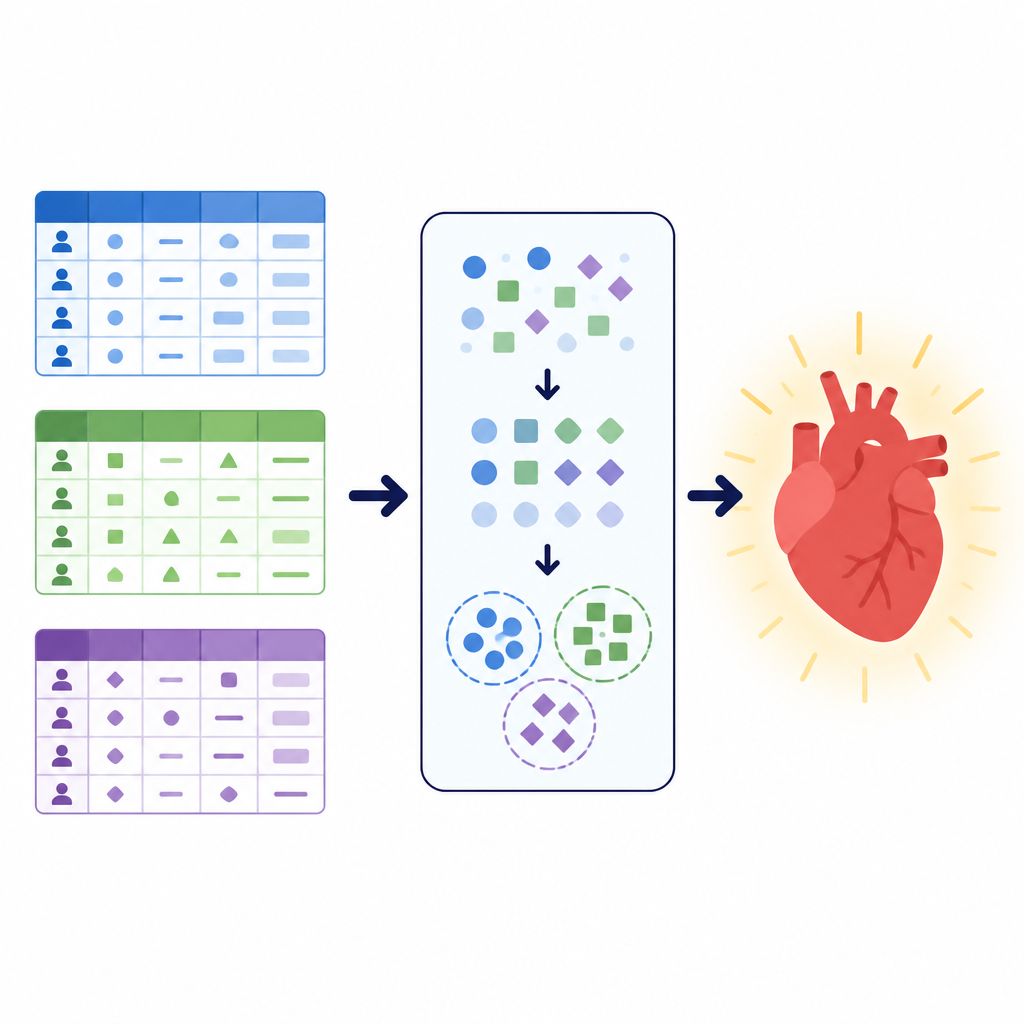
Verschillende data, dezelfde gezondheidsvraag
De onderzoekers richtten zich op een eenvoudige maar essentiële taak: bepalen of een patiënt waarschijnlijk hart- en vaatziekten heeft of niet. Ze werkten met drie grote datasets, elk met een andere beschrijving van patiënten. De ene combineerde klinische testresultaten zoals bloeddruk, cholesterol en inspanning-elektrocardiogrammen. Een andere mengde basismetingen zoals lengte en gewicht met leefstijlinformatie zoals roken en activiteit. Een derde, lokale dataset uit een ziekenhuis in Pakistan benadrukte enquêteachtige vragen over algemene gezondheid, slaap, chronische aandoeningen en roken of e-sigaretgebruik, naast enkele klinische controles. Samen omvatten deze verzamelingen meer dan 260.000 patiëntendossiers en lieten ze zien hoe gezondheidsdata in de praktijk kunnen variëren in structuur, kwaliteit en balans tussen zieke en gezonde gevallen.
Opschonen en herschikken van patiëntinformatie
Voordat ze modellen trainden, ontwierp het team een zorgvuldige preprocessing-pijplijn om de data te schonen en te herschikken. Ze verwijderden dubbele vermeldingen, schrapten records met ontbrekende waarden in de lokale dataset en snoeiden extreme uitschieters in bloeddruk en lichaamsmaten uit de grotere publieke dataset. Ze zetten leeftijd om van dagen naar jaren en groepeerden patiënten vervolgens in leeftijdsbanden om patronen makkelijker te laten leren tussen datasets die leeftijd oorspronkelijk verschillend opsloegen. Nieuwe gecombineerde kenmerken zoals body mass index en het gemiddelde arteriële bloeddruk werden berekend en in eenvoudige categorieën geplaatst om complexiteit te verminderen. Alle categorische antwoorden, zoals rookstatus of type pijn op de borst, werden pas gecodeerd naar numerieke waarden nadat de data in trainings- en testsets was gesplitst, om te voorkomen dat er verborgen informatie tussen die sets zou lekken.
Verborgen patiëntgroepen vinden met clustering
Om de modellen een extra gevoel van structuur te geven, gebruikten de auteurs een techniek die clustering heet. In plaats van te vragen of iemand ziekte heeft, zoekt clustering naar natuurlijke groeperingen in de data zonder het diagnose-label te gebruiken. Hier paste het team een methode toe die geschikt is voor categorische informatie om elke dataset in een klein aantal clusters te verdelen en voegde vervolgens de cluster-toewijzing toe als een nieuw kenmerk. Dit extra signaal vangt patronen zoals veelvoorkomende combinaties van symptomen of leefstijlfactoren die niet direct duidelijk zijn uit de oorspronkelijke variabelen. Door te leren van zowel de oorspronkelijke kenmerken als deze ontdekte groepen, konden de latere voorspellingsmodellen zich richten op meer geordende versies van de patiëntpopulaties.
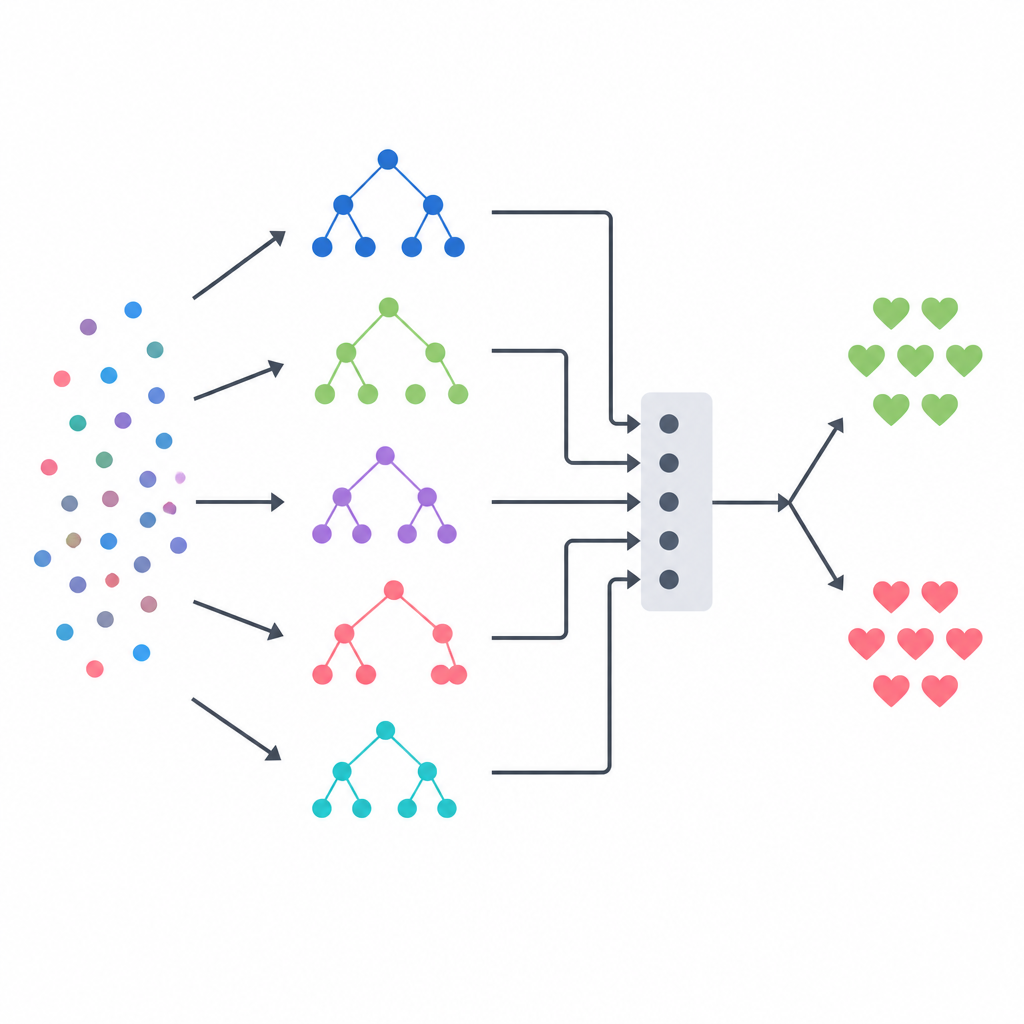
Verschillende modellen samenbrengen tot één beslissing
De kern van de aanpak is een stacking-ensemble, dat werkt als een panel van diverse experts geleid door een uiteindelijke scheidsrechter. Drie op bomen gebaseerde modellen — een decision tree, een random forest en een extreem gerandomiseerd boom-systeem — geven elk hun eigen kansschattingen voor ziekte voor iedere patiënt. Hun outputs worden vervolgens gecombineerd tot een klein samenvattend vector, dat wordt doorgegeven aan een logistieke regressie die leert hoeveel vertrouwen ze aan elk basismodel moet toekennen in verschillende situaties. Om te voorkomen dat deze scheidsrechter oneerlijke hints krijgt, bouwde het team de trainingsdata met een strikt cross-validation-schema, waarbij elk basismodel eerst voorspelt op patiënten die het nog niet eerder gezien heeft. Dit ontwerp is bedoeld om de sterke punten van elke methode te benutten en overfitting te verminderen.
Hoe goed de methode presteerde over datasets heen
Het gestackte model werd getest tegen gangbare machine learning-methoden, een populair boosting-algoritme en verschillende deep learning-architecturen, waaronder feedforward-neurale netwerken, convolutionele netwerken en een moderne tabelgerichte netwerkarchitectuur bekend als TabNet. Op de klinisch rijke maar matig grote Dataset I bereikte stacking ongeveer 93 procent nauwkeurigheid en overtrof het alle baselines. Op de grote en lawaaierige Dataset II clusteren de meeste modellen rond 71 tot 72 procent nauwkeurigheid; hier evenaarde stacking de best presterende modellen en overtrof duidelijk het convolutionele netwerk. Op de gestructureerde lokale Dataset III bereikten bijna alle geavanceerde modellen, inclusief stacking, ongeveer 99 procent nauwkeurigheid, wat aangeeft dat de data zelf gemakkelijk te scheiden was zodra ze waren opgeschoond. Herhaalde experimenten met verschillende willekeurige zaden leverden smalle betrouwbaarheidsintervallen op, en een statistische test bevestigde dat de winst van stacking ten opzichte van meerdere rivalen onwaarschijnlijk toe te schrijven was aan toeval.
Wat dit betekent voor toekomstige hulpmiddelen voor hartrisico
Voor niet-specialisten is de kernboodschap dat hoe we data voorbereiden en datagestuurde modellen combineren even belangrijk kan zijn als de keuze van een individueel algoritme. Door nadruk te leggen op zorgvuldige schoonmaak, doordachte featureontwerpen, bescherming tegen informatielekkage en het samenvoegen van meerdere complementaire modellen, laat deze studie een praktische weg zien naar voorspelsystemen voor hartziekten die betrouwbaar blijven wanneer de patiëntenpopulatie of het dataformaat verandert. Hoewel meer werk nodig is om zulke systemen in verschillende ziekenhuizen te testen en ze efficiënt en uitlegbaar te maken voor dagelijks gebruik, suggereren de resultaten dat goed geconstrueerde ensembles robuuste besluitvormingshulpmiddelen kunnen worden om clinici te helpen cardiovasculair risico eerder en consistenter te identificeren.
Bronvermelding: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Trefwoorden: voorspelling van hart- en vaatziekten, machine learning, ensemblemodellen, klinische data, risicodetectie