Clear Sky Science · it
Un classificatore stacking potenziato da preprocessing per la rilevazione generalizzata delle malattie cardiovascolari su set di dati diversi
Perché la rilevazione precoce del rischio cardiaco è importante
Le malattie del cuore e dei vasi rimangono il principale killer a livello mondiale, eppure molte persone non mostrano segnali di avvertimento fino a una crisi. I medici si affidano sempre più a programmi informatici per individuare schemi di rischio sottili nei dati dei pazienti molto prima della comparsa dei sintomi. Questo studio esplora un nuovo modo di addestrare tali programmi affinché rimangano accurati quando affrontano tipi di cartelle cliniche molto diversi, un passaggio chiave verso strumenti che funzionino in modo affidabile in vari ospedali e comunità.
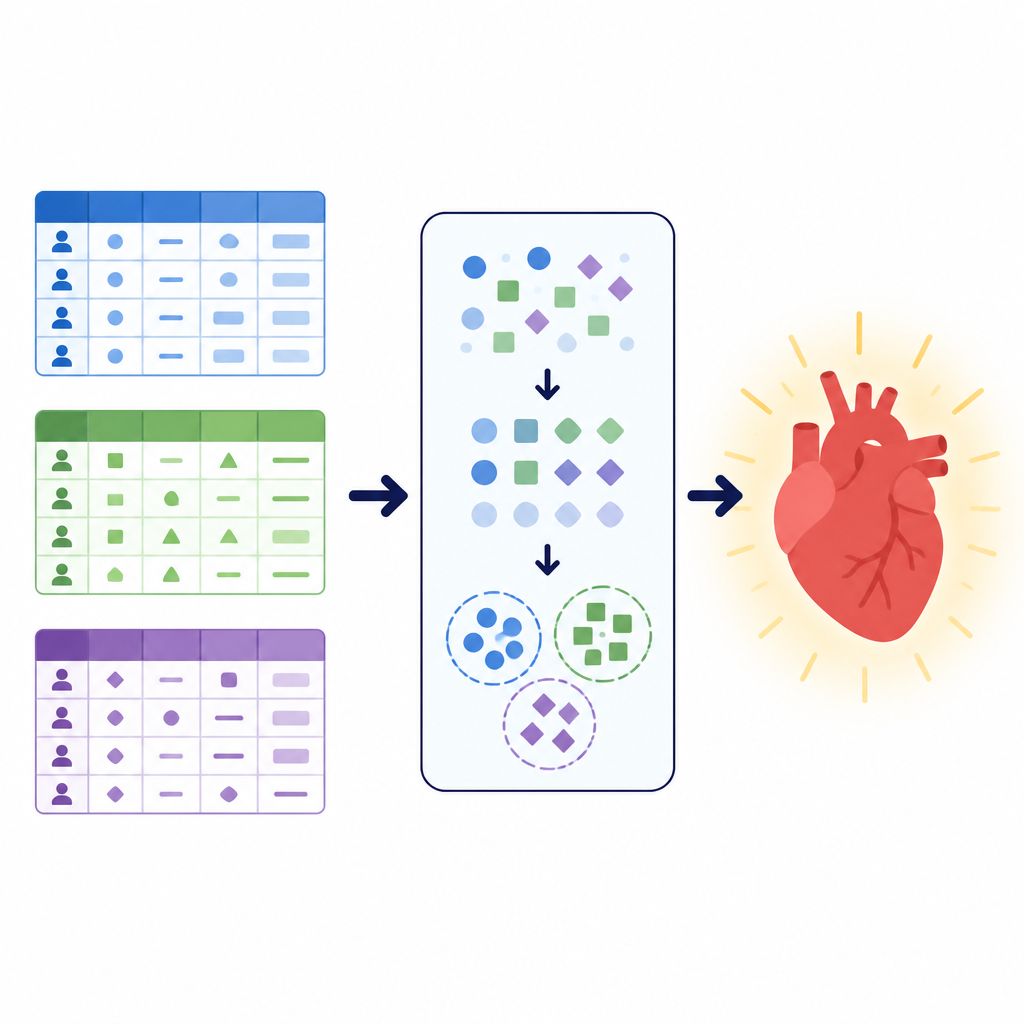
Dati diversi, stessa domanda di salute
I ricercatori si sono concentrati su un compito semplice ma vitale: decidere se un paziente sia probabile che abbia una malattia cardiovascolare o no. Hanno lavorato con tre ampi set di dati, ciascuno descrivendo i pazienti in modo diverso. Uno combinava risultati di test clinici come pressione sanguigna, colesterolo ed elettrocardiogrammi da esercizio. Un altro univa misure di base come altezza e peso con informazioni sullo stile di vita quali fumo e attività fisica. Un terzo set locale, proveniente da un ospedale in Pakistan, enfatizzava domande in stile sondaggio su salute generale, sonno, condizioni croniche e uso di sigarette o sigarette elettroniche, insieme a pochi controlli clinici. Insieme queste raccolte coprivano più di 260.000 cartelle paziente e illustravano come i dati sanitari reali possano variare per struttura, pulizia e bilanciamento tra casi malati e sani.
Pulire e rimodellare le informazioni sui pazienti
Prima di addestrare qualsiasi modello, il team ha progettato una pipeline di preprocessing accurata per pulire e rimodellare i dati. Hanno rimosso voci duplicate, scartato record con valori mancanti nel set locale e ridotto outlier estremi nella pressione sanguigna e nelle dimensioni corporee nel più grande set pubblico. Hanno convertito l’età da giorni ad anni e poi raggruppato i pazienti in fasce d’età per rendere i pattern più facili da apprendere tra dataset che originariamente registravano l’età in modo diverso. Sono state calcolate nuove caratteristiche combinate come l’indice di massa corporea e la pressione arteriosa media, e collocate in categorie semplici per ridurre la complessità. Tutte le risposte categoriche, come lo stato di fumatore o il tipo di dolore toracico, sono state convertite in codici numerici solo dopo che i dati erano stati divisi in set di addestramento e test, evitando che informazioni nascoste trapelassero tra di essi.
Trovare gruppi nascosti di pazienti con il clustering
Per fornire ai modelli un senso aggiuntivo di struttura, gli autori hanno utilizzato una tecnica chiamata clustering. Invece di chiedersi se qualcuno abbia una malattia, il clustering ricerca raggruppamenti naturali nei dati senza usare l’etichetta di diagnosi. In questo caso, il team ha applicato un metodo adatto per informazioni categoriche per dividere ogni dataset in un piccolo numero di cluster e ha poi aggiunto l’assegnazione al cluster come nuova caratteristica. Questo segnale aggiuntivo cattura pattern come combinazioni comuni di sintomi o fattori dello stile di vita che potrebbero non essere evidenti dalle variabili originali. Imparando sia dalle caratteristiche originali sia da questi gruppi scoperti, i modelli predittivi successivi potevano concentrarsi su versioni più organizzate delle popolazioni di pazienti.
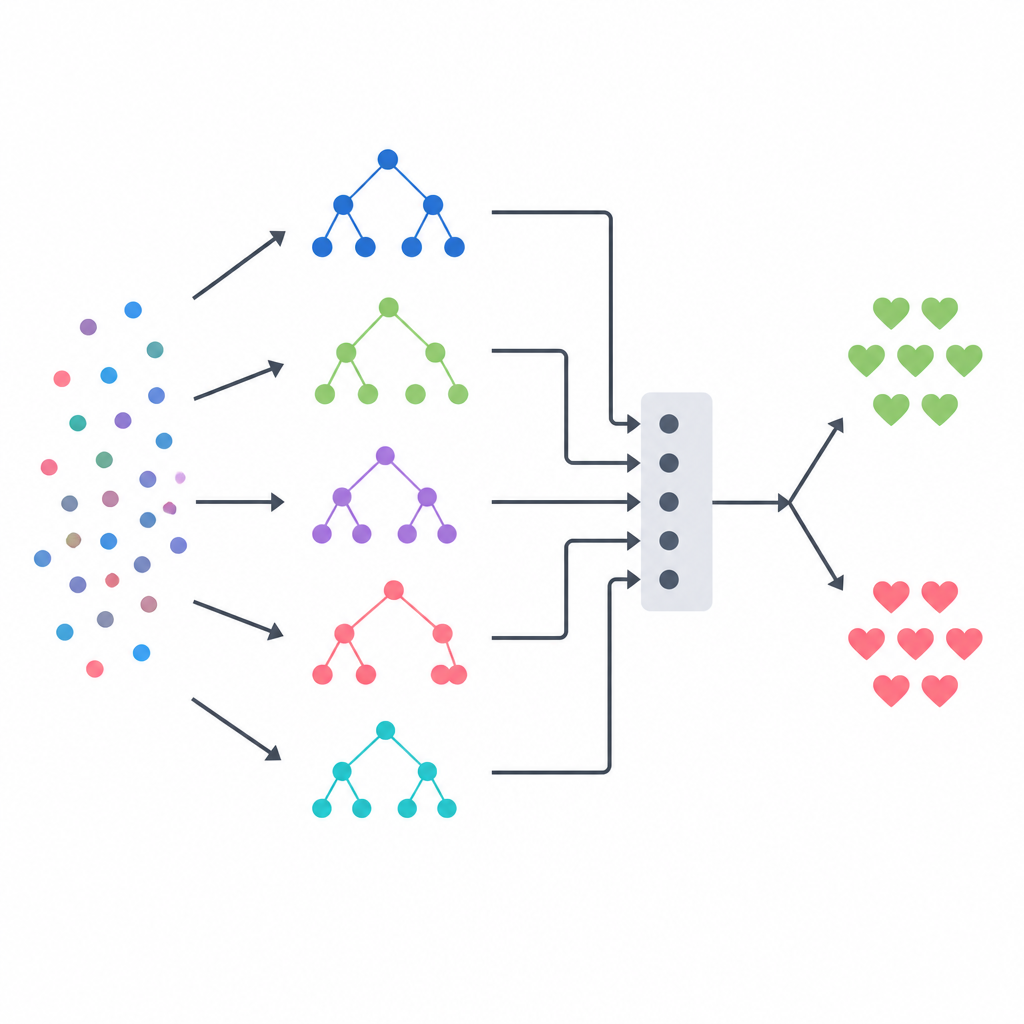
Combinare più modelli in una sola decisione
Il nucleo dell’approccio è un ensemble stacking, che funziona come un pannello di esperti diversi guidato da un arbitro finale. Tre modelli basati sugli alberi — un decision tree, una random forest e un sistema di alberi estremamente randomizzati — ciascuno fornisce la propria stima di probabilità di malattia per ogni paziente. Le loro uscite vengono poi combinate in un piccolo vettore riassuntivo, che viene passato a un modello di regressione logistica che impara quanto fidarsi di ciascun modello base in diverse situazioni. Per evitare di fornire indizi ingiusti a questo arbitro, il team ha costruito i dati di addestramento usando uno schema di cross validation rigoroso, in cui ogni modello base predice per primo su pazienti che non aveva ancora visto. Questo disegno mira a catturare i punti di forza di ogni metodo riducendo l’overfitting.
Quanto ha performato il metodo sui diversi dataset
Il modello stacked è stato confrontato con metodi comuni di machine learning, un popolare approccio di boosting e varie architetture di deep learning, incluse reti neurali feedforward, reti convoluzionali e una moderna rete orientata alle tabelle nota come TabNet. Sul Dataset I, clinicamente ricco ma di dimensioni moderate, lo stacking ha raggiunto circa il 93% di accuratezza e ha superato tutti i baseline. Sul grande e rumoroso Dataset II, la maggior parte dei modelli si è attestata intorno al 71–72% di accuratezza; qui lo stacking ha eguagliato i migliori performer e ha chiaramente sorpassato la rete convoluzionale. Sul Dataset III locale e strutturato, quasi tutti i modelli avanzati, incluso lo stacking, hanno raggiunto circa il 99% di accuratezza, dimostrando che i dati stessi erano facili da separare una volta puliti. Ripetere gli esperimenti con diversi semi casuali ha prodotto intervalli di confidenza stretti, e un test statistico ha confermato che i guadagni dello stacking rispetto a diversi rivali erano improbabili dovuti al caso.
Cosa significa questo per i futuri strumenti di valutazione del rischio cardiaco
Per i non specialisti, il messaggio chiave è che il modo in cui prepariamo e combiniamo i modelli guidati dai dati può contare tanto quanto la scelta di un singolo algoritmo. Sottolineando una pulizia attenta, una progettazione accurata delle caratteristiche, la protezione contro la fuga di informazioni e la combinazione di più modelli complementari, questo studio mostra una strada pratica verso sistemi di previsione delle malattie cardiache che rimangono affidabili quando la popolazione di pazienti o il formato dei dati cambia. Sebbene siano necessari ulteriori lavori per testare tali sistemi tra ospedali e per renderli efficienti e interpretabili nell’uso quotidiano, i risultati suggeriscono che ensemble ben ingegnerizzati potrebbero diventare solidi ausili decisionali per aiutare i clinici a identificare il rischio cardiovascolare prima e in modo più coerente.
Citazione: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Parole chiave: predizione delle malattie cardiovascolari, apprendimento automatico, modelli ensemble, dati clinici, rilevazione del rischio