Clear Sky Science · pt
Um classificador em empilhamento aprimorado por pré-processamento para detecção generalizada de doenças cardiovasculares em conjuntos de dados diversos
Por que a detecção precoce do risco cardíaco importa
Doenças do coração e dos vasos sanguíneos continuam sendo a maior causa de morte no mundo, porém muitas pessoas não apresentam sinais de alerta até ocorrer uma crise. Médicos recorrem cada vez mais a programas de computador para identificar padrões sutis de risco em dados de pacientes muito antes de surgirem sintomas. Este estudo explora uma nova forma de treinar esses programas para que mantenham precisão quando confrontados com tipos muito diferentes de registros médicos, um passo fundamental rumo a ferramentas que funcionem de forma confiável em diversos hospitais e comunidades.
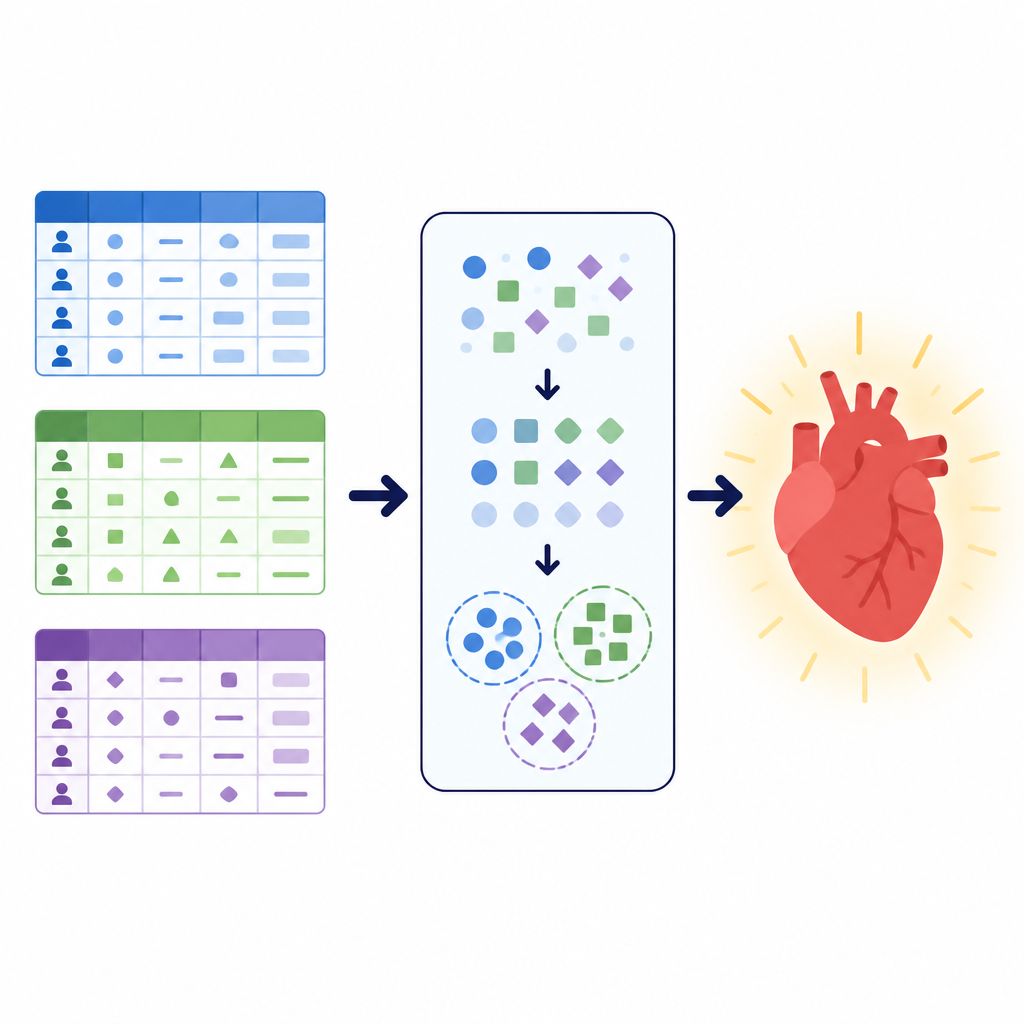
Dados diferentes, mesma questão de saúde
Os pesquisadores se concentraram em uma tarefa simples, mas vital: decidir se um paciente tem probabilidade de ter doença cardiovascular ou não. Trabalharam com três grandes conjuntos de dados, cada um descrevendo pacientes de forma distinta. Um combinava resultados de exames clínicos como pressão arterial, colesterol e eletrocardiograma de esforço. Outro misturava medidas básicas como altura e peso com informações de estilo de vida, como tabagismo e atividade física. Um terceiro conjunto local de um hospital no Paquistão enfatizava perguntas tipo pesquisa sobre saúde geral, sono, condições crônicas e uso de cigarro ou cigarro eletrônico, junto com alguns exames clínicos. Juntas, essas coleções cobriram mais de 260.000 prontuários e ilustraram como dados de saúde do mundo real podem variar em estrutura, limpeza e balanceamento entre casos doentes e saudáveis.
Limpeza e reformatação das informações do paciente
Antes de treinar qualquer modelo, a equipe projetou um pipeline de pré-processamento cuidadoso para limpar e reformular os dados. Removeram entradas duplicadas, descartaram registros com valores faltantes no conjunto local e apararam outliers extremos em pressão arterial e medidas corporais no grande conjunto público. Converteram idade de dias para anos e depois agruparam pacientes em faixas etárias para facilitar a aprendizagem de padrões entre conjuntos que originalmente armazenavam a idade de forma diferente. Novas características combinadas, como índice de massa corporal e pressão arterial média, foram calculadas e categorizadas de forma simples para reduzir a complexidade. Todas as respostas categóricas, como status de tabagismo ou tipo de dor torácica, foram convertidas em códigos numéricos somente após a divisão dos dados em conjuntos de treino e teste, evitando vazamento de informação entre eles.
Encontrando grupos ocultos de pacientes com clusterização
Para dar aos modelos um senso extra de estrutura, os autores utilizaram uma técnica chamada clusterização. Em vez de perguntar se alguém tem doença, a clusterização busca agrupamentos naturais nos dados sem usar o rótulo de diagnóstico. Aqui, a equipe aplicou um método adequado para informação categórica para dividir cada conjunto em um pequeno número de clusters e então adicionou a atribuição de cluster como uma nova característica. Esse sinal adicional captura padrões como combinações comuns de sintomas ou fatores de estilo de vida que podem não ser óbvios a partir das variáveis originais. Ao aprender tanto com as características originais quanto com esses grupos descobertos, os modelos de previsão posteriores puderam se concentrar em versões mais organizadas das populações de pacientes.
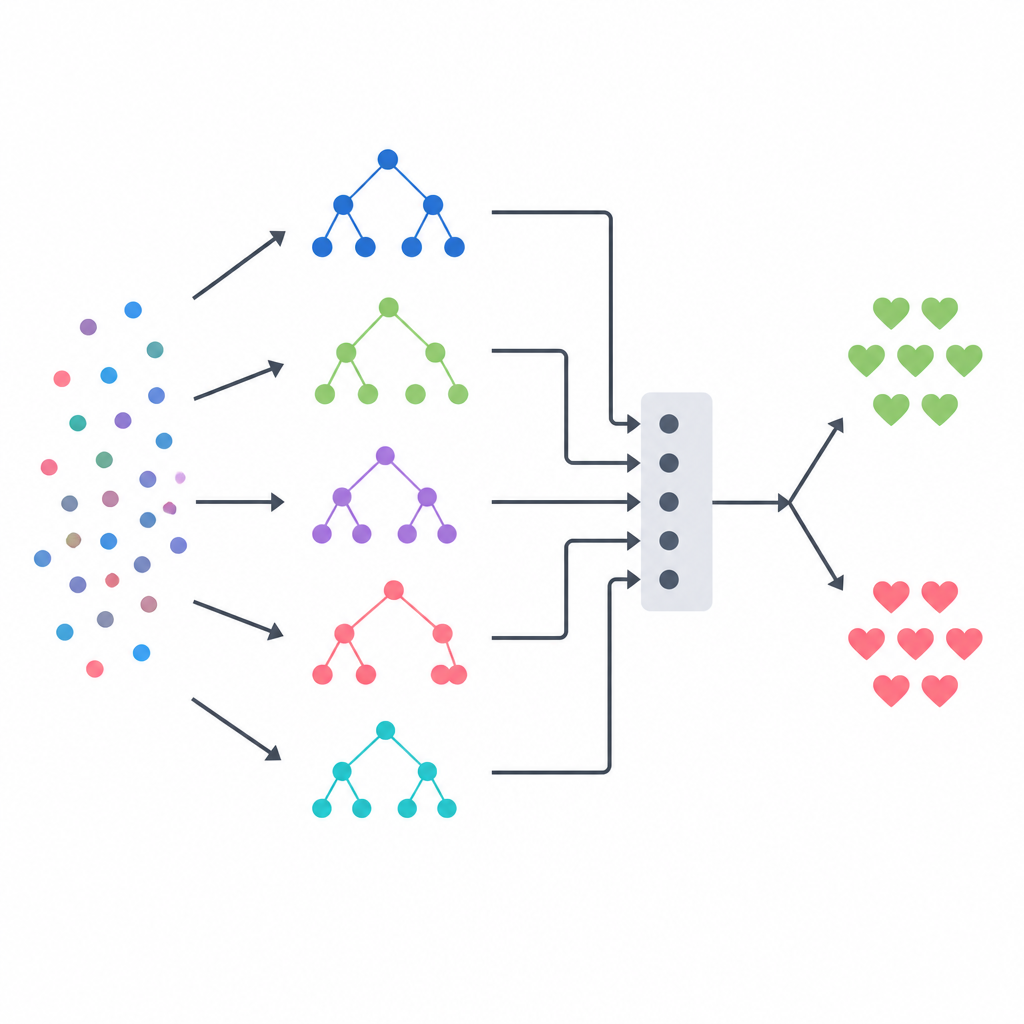
Mesclando vários modelos em uma decisão
O núcleo da abordagem é um ensemble em empilhamento (stacking), que atua como um painel de especialistas diversos orientado por um árbitro final. Três modelos base baseados em árvores — uma árvore de decisão, uma floresta aleatória e um sistema de árvores extremamente aleatorizadas — cada um produz suas próprias estimativas de probabilidade de doença para cada paciente. Suas saídas são então combinadas em um pequeno vetor resumo, que é passado para um modelo de regressão logística que aprende quanto confiar em cada modelo base em diferentes situações. Para evitar fornecer pistas indevidas a esse árbitro, a equipe construiu seus dados de treino usando um esquema rigoroso de validação cruzada, onde cada modelo base primeiro prevê pacientes que não havia visto antes. Esse desenho visa capturar os pontos fortes de cada método enquanto reduz o sobreajuste.
Desempenho do método entre os conjuntos de dados
O modelo empilhado foi testado contra métodos comuns de aprendizado de máquina, uma abordagem popular de boosting e várias arquiteturas de deep learning, incluindo redes neurais feedforward, redes convolucionais e uma rede moderna orientada a tabelas conhecida como TabNet. No Conjunto de Dados I, clinicamente rico mas de tamanho moderado, o stacking alcançou cerca de 93% de acurácia e superou todas as linhas de base. No grande e ruidoso Conjunto de Dados II, a maioria dos modelos ficou em torno de 71 a 72% de acurácia; aqui o stacking igualou os melhores desempenhos e superou claramente a rede convolucional. No estruturado Conjunto de Dados III local, quase todos os modelos avançados, incluindo o stacking, atingiram cerca de 99% de acurácia, mostrando que os dados em si eram fáceis de separar após a limpeza. Repetir os experimentos com diferentes sementes aleatórias produziu intervalos de confiança estreitos, e um teste estatístico confirmou que os ganhos do stacking sobre vários rivais eram improváveis de se dever ao acaso.
O que isso significa para futuras ferramentas de risco cardíaco
Para não especialistas, a mensagem chave é que a forma como preparamos e combinamos modelos orientados a dados pode importar tanto quanto a escolha de qualquer algoritmo isolado. Ao enfatizar limpeza cuidadosa, design criterioso de características, proteção contra vazamento de informação e a combinação de múltiplos modelos complementares, este estudo mostra um caminho prático rumo a sistemas de previsão de doenças cardíacas que se mantêm confiáveis quando a população de pacientes ou o formato dos dados muda. Embora sejam necessários mais estudos para testar tais sistemas entre hospitais e torná-los eficientes e explicáveis para uso cotidiano, os resultados sugerem que ensembles bem projetados podem se tornar auxiliares de decisão robustos para ajudar clínicos a identificar o risco cardiovascular mais cedo e de forma mais consistente.
Citação: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Palavras-chave: previsão de doenças cardiovasculares, aprendizado de máquina, modelos ensemble, dados clínicos, detecção de risco