Clear Sky Science · fr
Un classifieur empilé amélioré par un prétraitement pour la détection généralisée des maladies cardiovasculaires sur des jeux de données variés
Pourquoi la détection précoce du risque cardiaque est importante
Les maladies du cœur et des vaisseaux restent la première cause de mortalité dans le monde, et pourtant de nombreuses personnes n’ont aucun signe avant-coureur jusqu’à l’apparition d’une crise. Les médecins se tournent de plus en plus vers des programmes informatiques pour repérer des motifs de risque subtils dans les données des patients bien avant l’apparition des symptômes. Cette étude explore une nouvelle manière d’entraîner ces programmes afin qu’ils restent précis face à des types de dossiers médicaux très différents, une étape clé pour développer des outils fiables dans de nombreux hôpitaux et communautés.
Des données différentes, la même question de santé
Les auteurs se sont concentrés sur une tâche simple mais essentielle : décider si un patient est susceptible d’avoir une maladie cardiovasculaire ou non. Ils ont travaillé avec trois grands jeux de données, chacun décrivant les patients d’une manière distincte. L’un combinait des examens cliniques tels que la pression artérielle, le cholestérol et des électrocardiogrammes d’effort. Un autre mêlait des mesures de base comme la taille et le poids à des informations sur le mode de vie telles que le tabagisme et l’activité physique. Un troisième jeu de données local provenant d’un hôpital au Pakistan mettait l’accent sur des questions de type enquête portant sur la santé générale, le sommeil, les maladies chroniques et le tabagisme ou l’usage de cigarettes électroniques, accompagnées de quelques examens cliniques. Ensemble, ces collections couvraient plus de 260 000 dossiers patients et illustraient comment les données de santé réelles peuvent varier en structure, propreté et équilibre entre cas malades et sains.
Nettoyer et remodeler les informations patients
Avant d’entraîner les modèles, l’équipe a conçu une chaîne de prétraitement soigneuse pour nettoyer et restructurer les données. Ils ont supprimé les entrées en double, éliminé les dossiers avec des valeurs manquantes dans le jeu de données local et tronqué les valeurs aberrantes extrêmes de pression artérielle et de taille corporelle dans le grand jeu public. Ils ont converti l’âge de jours en années puis regroupé les patients en tranches d’âge pour faciliter l’apprentissage des motifs entre des jeux de données qui stockaient initialement l’âge différemment. De nouvelles caractéristiques combinées, telles que l’indice de masse corporelle et la pression artérielle moyenne, ont été calculées et classées en catégories simples pour réduire la complexité. Toutes les réponses catégorielles, comme le statut tabagique ou le type de douleur thoracique, ont été converties en codes numériques uniquement après la séparation des ensembles d’entraînement et de test, empêchant ainsi toute fuite d’information entre eux.
Découvrir des groupes de patients cachés par clustering
Pour donner aux modèles un sens supplémentaire de structure, les auteurs ont utilisé une technique appelée clustering. Plutôt que de demander si une personne est malade, le clustering recherche des groupements naturels dans les données sans utiliser l’étiquette de diagnostic. Ici, l’équipe a appliqué une méthode adaptée aux informations catégorielles pour diviser chaque jeu de données en un petit nombre de clusters, puis a ajouté l’affectation de cluster comme nouvelle caractéristique. Ce signal supplémentaire capture des motifs tels que des combinaisons fréquentes de symptômes ou de facteurs de mode de vie qui peuvent ne pas être évidents à partir des variables originales. En apprenant à la fois à partir des caractéristiques initiales et de ces groupes découverts, les modèles de prédiction ultérieurs pouvaient se concentrer sur des versions plus organisées des populations de patients.
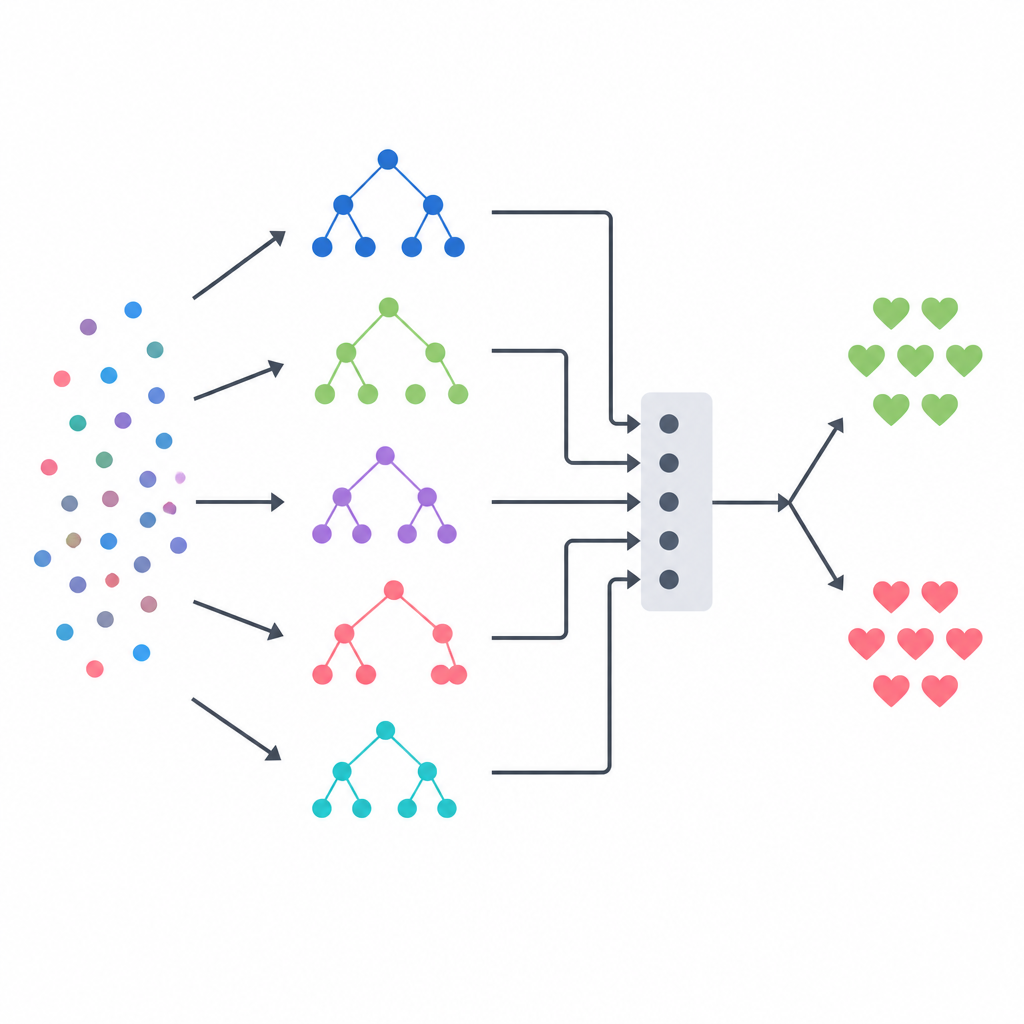
Assembler plusieurs modèles en une décision
Le cœur de l’approche est un empilement (stacking), qui agit comme un panel d’experts divers guidé par un arbitre final. Trois modèles à base d’arbres — un arbre de décision, une forêt aléatoire et un système d’arbres extrêmement randomisés — produisent chacun leurs propres estimations de probabilité de maladie pour chaque patient. Leurs sorties sont ensuite combinées en un petit vecteur résumé, qui est transmis à un modèle de régression logistique qui apprend combien faire confiance à chaque modèle de base selon les situations. Pour éviter de donner des indices injustes à cet arbitre, l’équipe a construit ses données d’entraînement en utilisant un schéma strict de validation croisée, où chaque modèle de base prédit d’abord sur des patients qu’il n’a pas vus auparavant. Ce dispositif vise à capter les forces de chaque méthode tout en réduisant le surapprentissage.
Performances de la méthode sur les différents jeux de données
Le modèle empilé a été comparé à des méthodes d’apprentissage automatique classiques, à une approche populaire de boosting et à plusieurs architectures d’apprentissage profond, y compris des réseaux neuronaux feedforward, des réseaux convolutionnels et un réseau moderne orienté tableaux connu sous le nom de TabNet. Sur le jeu de données cliniquement riche mais de taille modérée (Dataset I), l’empilement a atteint environ 93 % de précision et a surpassé toutes les références. Sur le grand et bruyant Dataset II, la plupart des modèles se situaient autour de 71 à 72 % de précision ; ici l’empilement a égalé les meilleurs performeurs et a clairement surpassé le réseau convolutionnel. Sur le jeu de données local structuré (Dataset III), presque tous les modèles avancés, y compris l’empilement, ont atteint environ 99 % de précision, montrant que les données elles‑mêmes étaient faciles à séparer une fois nettoyées. La répétition des expériences avec différentes graines aléatoires a produit des intervalles de confiance étroits, et un test statistique a confirmé que les gains de l’empilement sur plusieurs rivaux étaient peu susceptibles d’être dus au hasard.
Ce que cela signifie pour les futurs outils de risque cardiaque
Pour les non spécialistes, le message clé est que la manière dont nous préparons et combinons les modèles pilotés par les données peut compter autant que le choix d’un algorithme isolé. En mettant l’accent sur un nettoyage soigneux, une conception réfléchie des caractéristiques, la protection contre les fuites d’information et le mélange de plusieurs modèles complémentaires, cette étude montre une voie pratique vers des systèmes de prédiction des maladies cardiaques qui restent fiables lorsque la population de patients ou le format des données change. Bien que des travaux supplémentaires soient nécessaires pour tester ces systèmes entre hôpitaux et pour les rendre efficaces et explicables pour un usage quotidien, les résultats suggèrent que des ensembles bien conçus pourraient devenir des aides à la décision robustes pour aider les cliniciens à identifier le risque cardiovasculaire plus tôt et de manière plus cohérente.
Citation: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Mots-clés: prédiction des maladies cardiovasculaires, apprentissage automatique, modèles d’ensemble, données cliniques, détection du risque