Clear Sky Science · sv
En förbehandlingsförstärkt stackingklassificerare för generell upptäckt av hjärt-kärlsjukdomar över olika dataset
Varför tidig upptäckt av hjärtrisk är viktig
Hjärt- och kärlsjukdomar är fortsatt världens främsta dödsorsak, ändå får många inga varningssignaler förrän en kris inträffar. Läkare vänder sig alltmer till datorprogram för att upptäcka subtila riskmönster i patientdata långt innan symtom visar sig. Denna studie utforskar ett nytt sätt att träna sådana program så att de förblir tillförlitliga när de möter mycket olika typer av journaldata — ett viktigt steg mot verktyg som fungerar konsekvent i många sjukhus och samhällen.
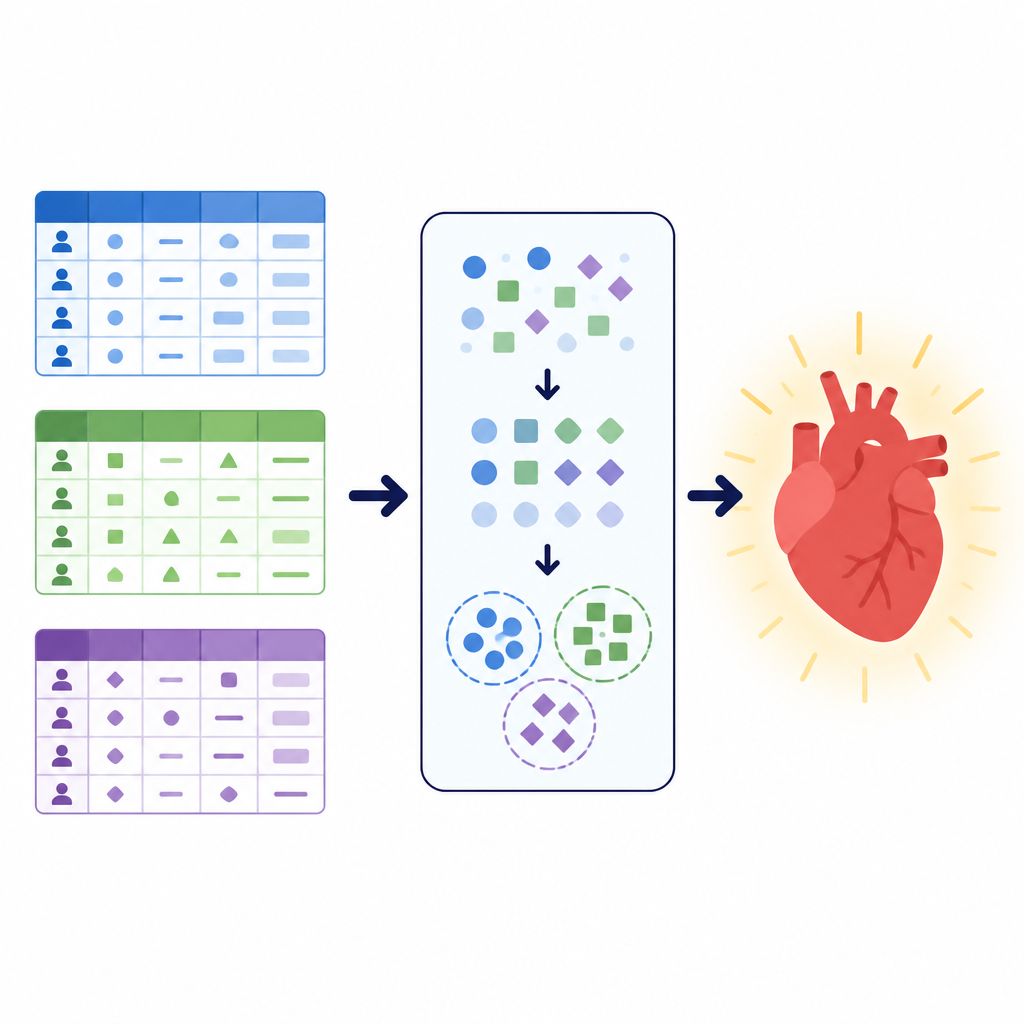
Olika data, samma hälsofråga
Forskarna fokuserade på en enkel men avgörande uppgift: att avgöra om en patient sannolikt har hjärt-kärlsjukdom eller inte. De arbetade med tre stora dataset, där vart och ett beskriver patienter på olika sätt. Ett kombinerade kliniska testresultat som blodtryck, kolesterol och arbets-EKG. Ett annat blandade grundläggande mått som längd och vikt med livsstilsinformation såsom rökning och fysisk aktivitet. Ett tredje lokalt dataset från ett sjukhus i Pakistan betonade enkätliknande frågor om allmän hälsa, sömn, kroniska tillstånd och rökning eller e-cigarettanvändning, tillsammans med några kliniska kontroller. Tillsammans täckte dessa samlingar mer än 260 000 patientregister och illustrerade hur verkliga hälso data kan variera i struktur, renhet och balans mellan sjuka och friska fall.
Rengöring och omformning av patientinformation
Innan några modeller tränades utformade teamet en noggrann förbehandlingspipeline för att rengöra och omforma data. De tog bort dubbletter, kastade poster med saknade värden i det lokala datasetet och beskärde extrema avvikare i blodtryck och kroppsstorlek från det större publika datasetet. De konverterade ålder från dagar till år och grupperade sedan patienter i åldersband för att göra mönster lättare att lära över dataset som ursprungligen lagrade ålder olika. Nya kombinerade funktioner såsom kroppsmassindex och medelartärblodtryck beräknades och placerades i enkla kategorier för att minska komplexiteten. Alla kategoriska svar, som rökningsstatus eller bröstsmärttyp, konverterades till numeriska koder först efter att data delats i tränings- och testset, för att förhindra att dold information läckte mellan dem.
Hitta dolda patientgrupper med klustring
För att ge modellerna en extra känsla av struktur använde författarna en teknik som kallas klustring. Istället för att fråga om någon har sjukdomen söker klustring efter naturliga grupperingarna i data utan att använda diagnosetiketten. Här tillämpade teamet en metod lämplig för kategorisk information för att dela varje dataset i ett litet antal kluster och lade sedan till klustertillhörigheten som en ny funktion. Denna extra signal fångar mönster som vanliga kombinationer av symtom eller livsstilsfaktorer som kanske inte är uppenbara från de ursprungliga variablerna ensam. Genom att lära sig från både de ursprungliga funktionerna och dessa upptäckta grupper kunde de senare prediktionsmodellerna fokusera på mer organiserade versioner av patientpopulationerna.
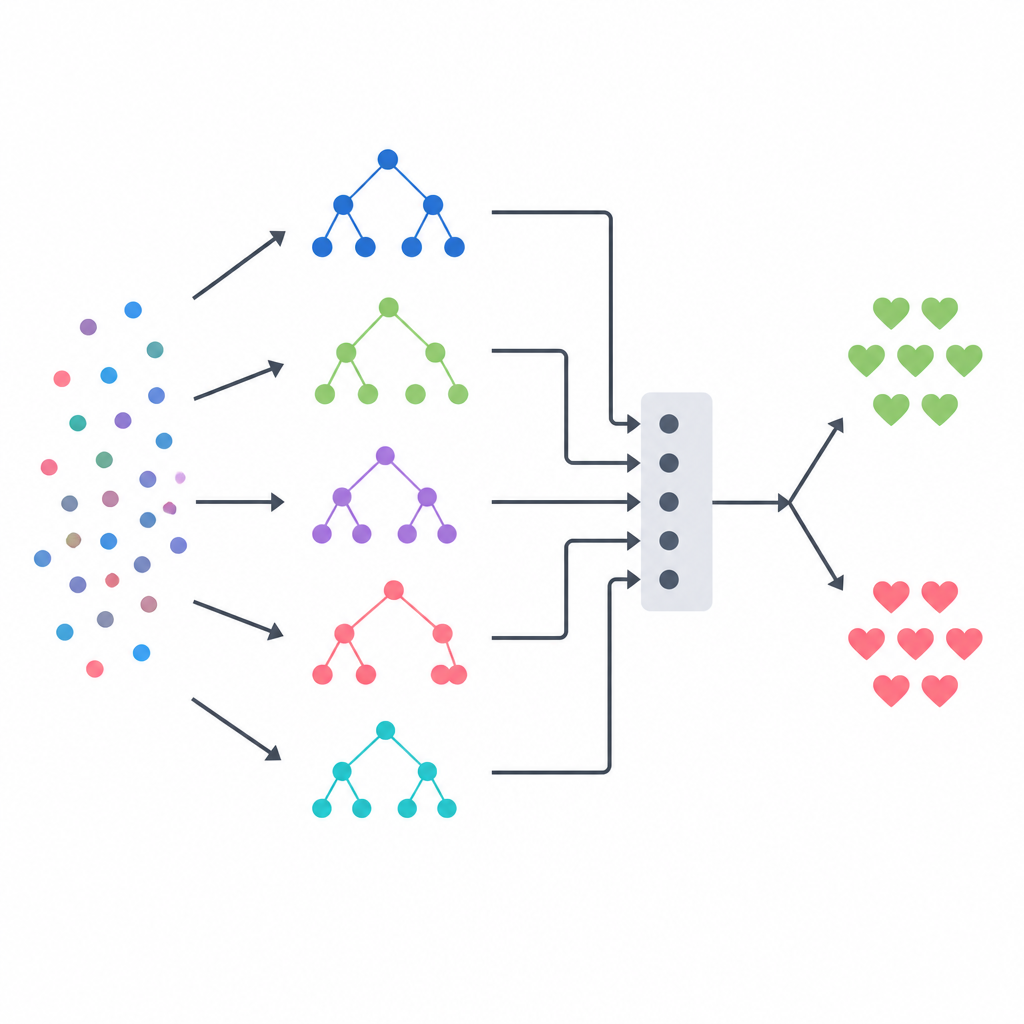
Att blanda flera modeller till ett beslut
Kärnan i tillvägagångssättet är en stacking-ensemble, som fungerar som en panel av olika experter ledda av en slutlig domare. Tre träd-baserade modeller — ett beslutsträd, en random forest och ett extremt randomiserat trädsystem — gör var för sig sina sannolikhetsskattningar för sjukdom för varje patient. Deras utdata kombineras sedan till en liten sammanfattningsvektor, som skickas till en logistisk regressionsmodell som lär sig hur mycket den ska lita på varje basmodell i olika situationer. För att undvika att ge denna domare orättvisa vinkar byggde teamet sitt träningsdata med ett strikt korsvalideringsschema, där varje basmodell först predikterar på patienter den inte sett tidigare. Denna design syftar till att fånga styrkorna hos varje metod samtidigt som överanpassning minskas.
Hur väl metoden presterade över dataset
Den stackade modellen testades mot vanliga maskininlärningsmetoder, en populär boostingmetod och flera djupa inlärningsarkitekturer, inklusive feedforward-nätverk, konvolutionella nätverk och ett modernt tabellorienterat nätverk känt som TabNet. På det kliniskt rika men måttligt stora Dataset I nådde stacking cirka 93 procent noggrannhet och överträffade alla baslinjer. På det stora och bullriga Dataset II samlades de flesta modeller runt 71–72 procents noggrannhet; här matchade stacking de bästa presterande och överträffade tydligt det konvolutionella nätverket. På det strukturerade lokala Dataset III uppnådde nästan alla avancerade modeller, inklusive stacking, cirka 99 procents noggrannhet, vilket visar att datan i sig var lätt att separera när den väl var renad. Upprepade experiment med olika slumpfrön gav smala konfidensintervall, och ett statistiskt test bekräftade att stackings förbättringar över flera rivaler sannolikt inte berodde på slump.
Vad detta betyder för framtida verktyg för hjärtrisk
För icke-specialister är huvudbudskapet att hur vi förbereder och kombinerar datadrivna modeller kan vara lika viktigt som valet av en enskild algoritm. Genom att betona noggrann rengöring, genomtänkt funktionsdesign, skydd mot informationsläckage och sammansmältning av flera kompletterande modeller visar denna studie en praktisk väg mot system för prediktion av hjärtsjukdom som förblir tillförlitliga när patientpopulationen eller dataformatet förändras. Även om mer arbete behövs för att testa sådana system över sjukhus och för att göra dem effektiva och förklarliga i vardagligt bruk, tyder resultaten på att välkonstruerade ensemblemetoder kan bli robusta beslutsstöd som hjälper kliniker att identifiera hjärt-kärlsrisk tidigare och mer konsekvent.
Citering: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Nyckelord: prediktion av hjärt-kärlsjukdom, maskininlärning, ensemblemodeller, kliniska data, riskupptäckt