Clear Sky Science · en
A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets
Why early heart risk detection matters
Heart and blood vessel diseases remain the world’s top killer, yet many people have no warning signs until a crisis occurs. Doctors increasingly turn to computer programs to spot subtle risk patterns in patient data long before symptoms appear. This study explores a new way to train such programs so they stay accurate when faced with very different types of medical records, a key step toward tools that work reliably in many hospitals and communities.
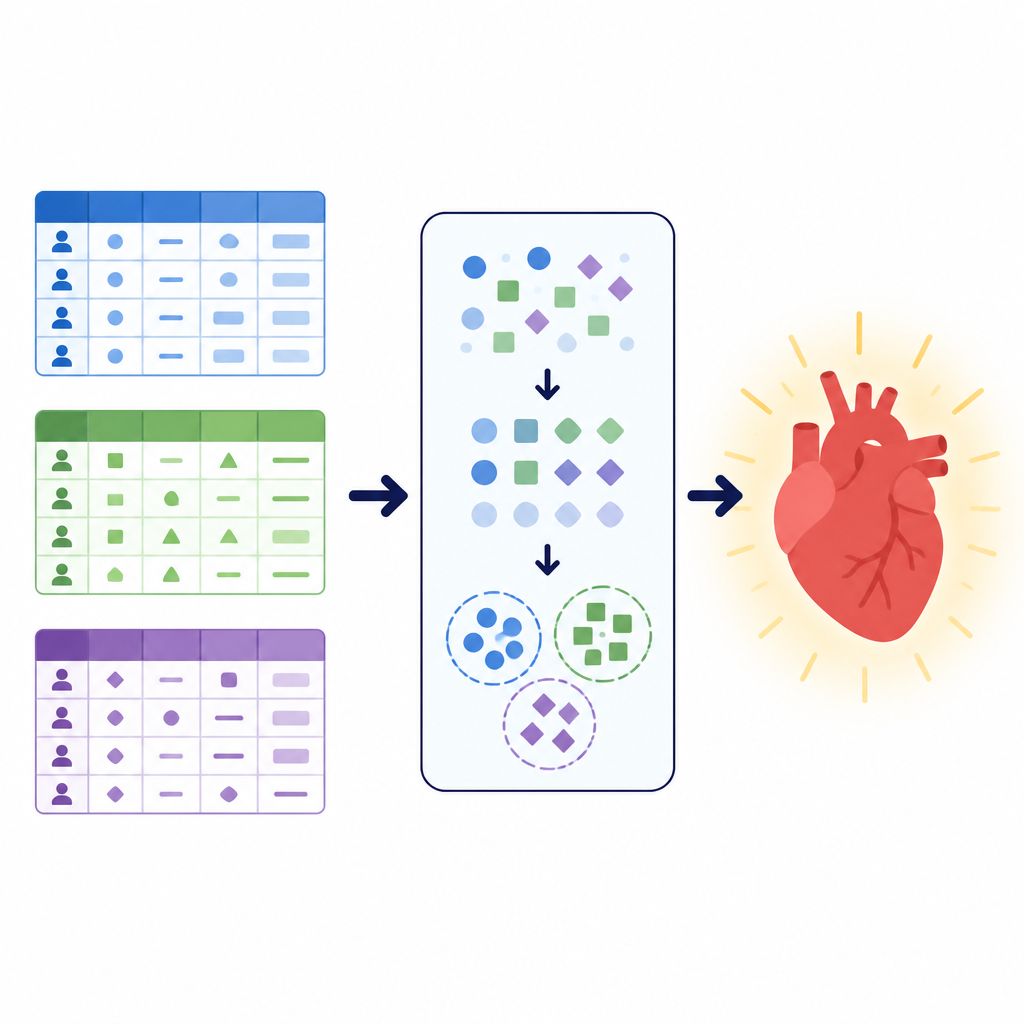
Different data, same health question
The researchers focused on a simple but vital task: deciding whether a patient is likely to have cardiovascular disease or not. They worked with three large datasets, each describing patients in a different way. One combined clinic test results such as blood pressure, cholesterol, and exercise electrocardiograms. Another mixed basic measurements like height and weight with lifestyle information such as smoking and activity. A third local dataset from a hospital in Pakistan emphasized survey style questions about general health, sleep, chronic conditions, and smoking or e cigarette use, alongside a few clinical checks. Together these collections covered more than 260,000 patient records and illustrated how real world health data can vary in structure, cleanliness, and balance between sick and healthy cases.
Cleaning and reshaping patient information
Before training any models, the team designed a careful preprocessing pipeline to clean and reshape the data. They removed duplicate entries, discarded records with missing values in the local dataset, and trimmed extreme outliers in blood pressure and body size from the larger public dataset. They converted age from days to years and then grouped patients into age bands to make patterns easier to learn across datasets that originally stored age differently. New combined features such as body mass index and mean arterial blood pressure were calculated and placed into simple categories to reduce complexity. All categorical answers, such as smoking status or chest pain type, were converted into numeric codes only after the data had been split into training and test sets, preventing hidden information from leaking between them.
Finding hidden patient groups with clustering
To give the models an extra sense of structure, the authors used a technique called clustering. Instead of asking whether someone has disease, clustering searches for natural groupings in the data without using the diagnosis label. Here, the team applied a method suited for categorical information to divide each dataset into a small number of clusters and then added the cluster assignment as a new feature. This extra signal captures patterns like common combinations of symptoms or lifestyle factors that may not be obvious from the original variables alone. By learning from both the original features and these discovered groups, the later prediction models could focus on more organized versions of the patient populations.
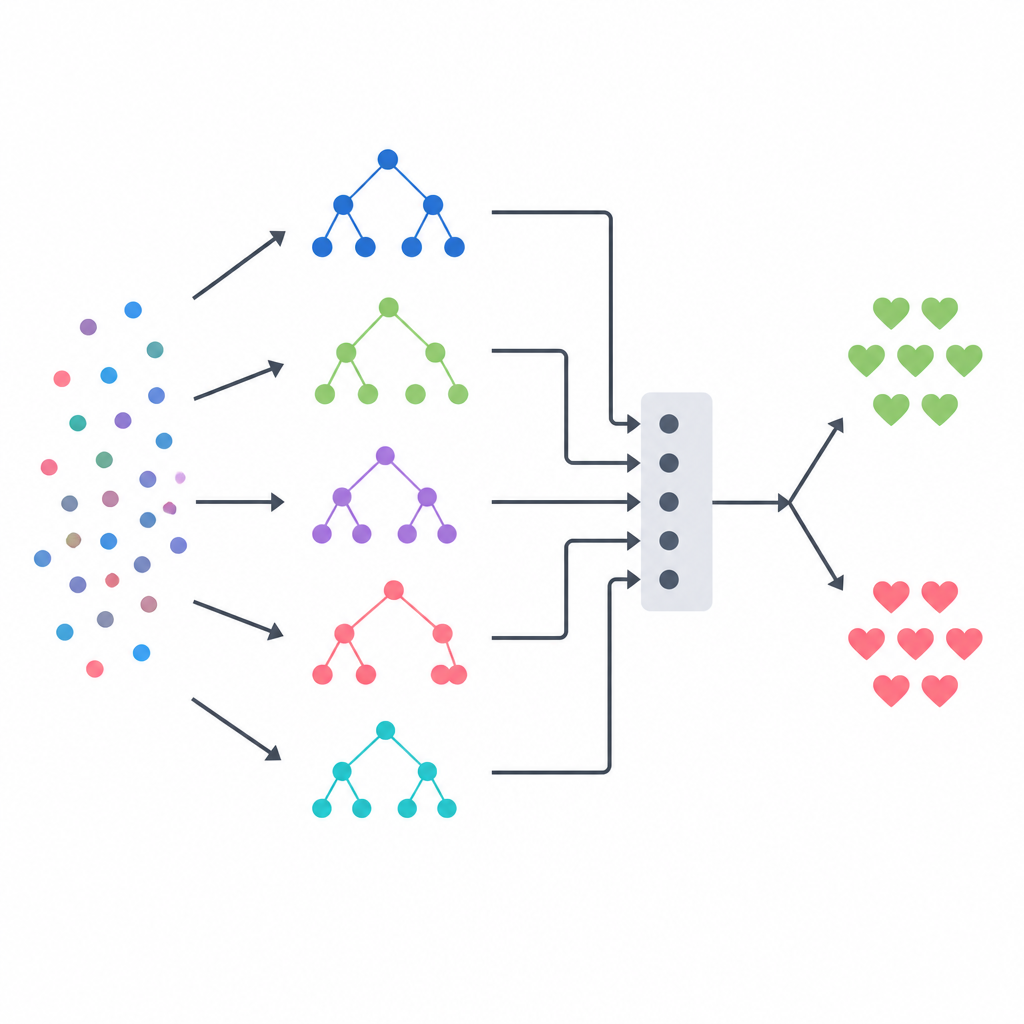
Blending several models into one decision
The core of the approach is a stacking ensemble, which acts like a panel of diverse experts guided by a final referee. Three tree based models a decision tree, a random forest, and an extremely randomized tree system each make their own probability estimates about disease for every patient. Their outputs are then combined into a small summary vector, which is passed to a logistic regression model that learns how much to trust each base model in different situations. To avoid giving this referee unfair hints, the team built its training data using a strict cross validation scheme, where each base model first predicts on patients it has not seen before. This design aims to capture the strengths of each method while reducing overfitting.
How well the method performed across datasets
The stacked model was tested against common machine learning methods, a popular boosting approach, and several deep learning architectures, including feedforward neural networks, convolutional networks, and a modern table oriented network known as TabNet. On the clinically rich but moderately sized Dataset I, stacking reached about 93 percent accuracy and outperformed all baselines. On the large and noisy Dataset II, most models clustered around 71 to 72 percent accuracy; here stacking matched the best performers and clearly surpassed the convolutional network. On the structured local Dataset III, almost all advanced models, including stacking, achieved about 99 percent accuracy, showing that the data itself was easy to separate once cleaned. Repeating the experiments with different random seeds produced narrow confidence intervals, and a statistical test confirmed that stacking’s gains over several rivals were unlikely to be due to chance.
What this means for future heart risk tools
For non specialists, the key message is that how we prepare and combine data driven models can matter as much as the choice of any single algorithm. By emphasizing careful cleaning, thoughtful feature design, protection against information leakage, and the blending of multiple complementary models, this study shows a practical path toward heart disease prediction systems that stay reliable when the patient population or data format changes. While more work is needed to test such systems across hospitals and to make them efficient and explainable for everyday use, the results suggest that well engineered ensembles could become sturdy decision aids to help clinicians identify cardiovascular risk earlier and more consistently.
Citation: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Keywords: cardiovascular disease prediction, machine learning, ensemble models, clinical data, risk detection