Clear Sky Science · ja
多様なデータセット間で汎化する前処理強化型スタッキング分類器による心血管疾患検出
早期の心臓リスク検出が重要な理由
心血管系疾患は依然として世界で最も多い死因ですが、多くの人は危機が起きるまで警告兆候を示しません。医師たちは、症状が現れる前に患者データの微妙なリスクパターンを見つけるためにコンピュータプログラムに頼ることが増えています。本研究は、そのようなプログラムを非常に異なる形式の医療記録に直面しても正確さを保てるように訓練する新しい方法を探ります。これは、多様な病院や地域で信頼して使えるツールに向けた重要な一歩です。
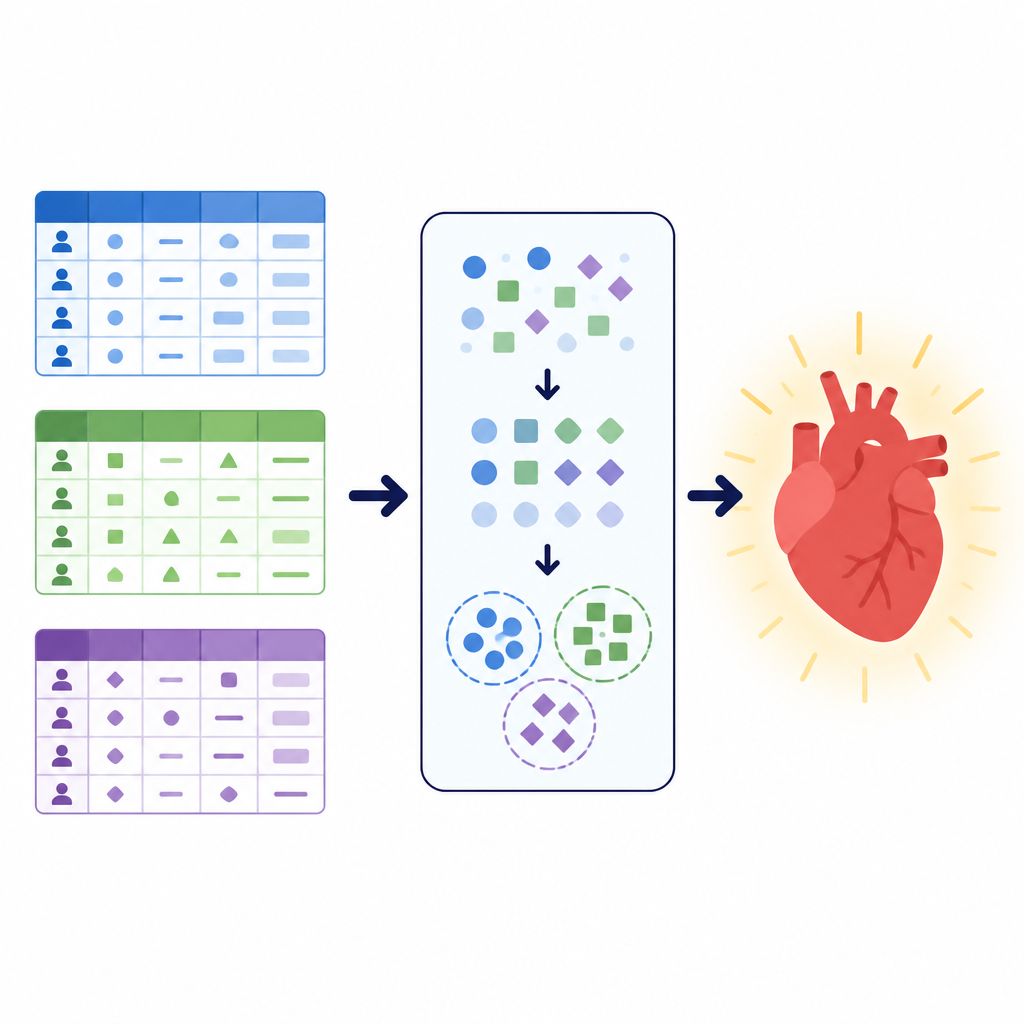
異なるデータ、同じ健康の問い
研究者たちは、シンプルだが重要な課題に注目しました:患者が心血管疾患を有する可能性があるかどうかを判断することです。彼らは、それぞれ異なる記述方法を持つ三つの大規模データセットで作業しました。一つは血圧、コレステロール、運動負荷心電図などの診療所での検査結果を組み合わせたものです。別のデータは身長や体重のような基本的測定に喫煙や活動量といった生活習慣情報を混ぜたものでした。三つ目はパキスタンの病院によるローカルなデータで、一般的な健康、睡眠、慢性疾患、喫煙や電子タバコの使用に関する調査形式の質問と、いくつかの臨床検査を強調していました。これらを合わせると26万件を超える患者記録をカバーし、現実の健康データが構造、整合性、疾患と健常ケースの比率でいかに異なり得るかを示しています。
患者情報のクレンジングと再整形
モデルを訓練する前に、チームはデータをクリーンにし再整形するための慎重な前処理パイプラインを設計しました。重複エントリを削除し、ローカルデータセットでは欠損値がある記録を破棄し、大規模な公開データセットでは血圧や体格の極端な外れ値を切り取る処理を行いました。年齢は日数から年に変換し、元々年齢を異なる形式で保存していたデータセット間でも学習しやすくするために年齢帯にまとめました。ボディマス指数や平均動脈圧のような新たな複合特徴を計算し、複雑さを減らすために単純なカテゴリーに分類しました。喫煙状況や胸痛の種類などのカテゴリカルな回答は、訓練セットとテストセットに分割した後でのみ数値コードに変換し、情報の漏洩を防ぎました。
クラスタリングで患者群の潜在構造を見つける
モデルに追加の構造を与えるために、著者らはクラスタリングと呼ばれる手法を用いました。クラスタリングは診断ラベルを用いずにデータ内の自然なグループを探します。ここではカテゴリ情報に適した手法を各データセットに適用し、少数のクラスタに分割してそのクラスタ割り当てを新しい特徴として追加しました。この追加の信号は、元の変数からは明らかでない症状や生活習慣の共通の組み合わせのようなパターンを捉えます。元の特徴とこれらの発見された群の両方から学習することで、後続の予測モデルはより整理された患者集団に注目できるようになります。
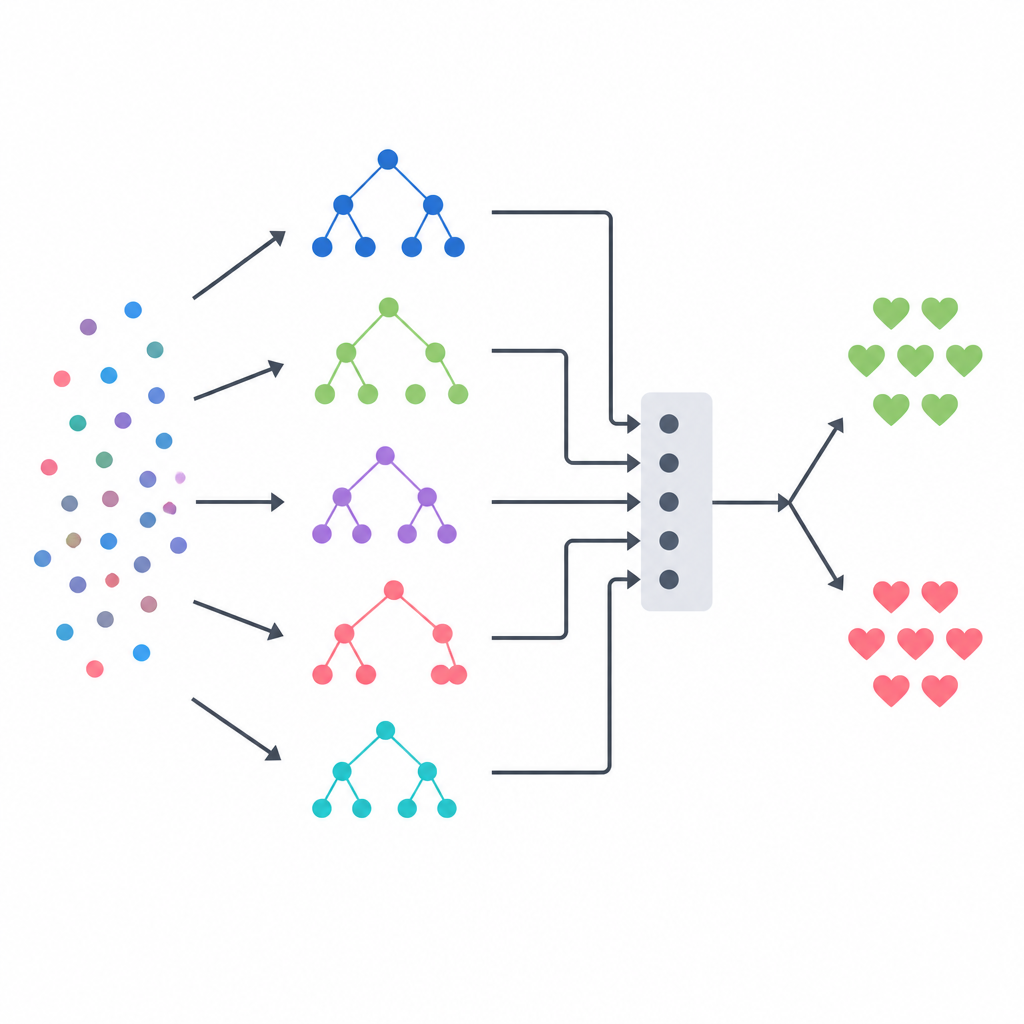
複数モデルを一つの判断に融合する
このアプローチの中核はスタッキング型アンサンブルで、複数の異なる専門家が最終審判に導かれるような仕組みです。決定木、ランダムフォレスト、極端にランダム化された木(extremely randomized tree)の3つの木ベースのモデルがそれぞれ患者ごとに疾患の確率推定を行います。これらの出力は小さな要約ベクトルにまとめられ、どの基礎モデルをどの状況でどれだけ信頼するかを学ぶロジスティック回帰モデルに渡されます。審判役に不公平な手掛かりを与えないように、チームは厳格な交差検証スキームを用いて訓練データを構築し、各基礎モデルがまず見たことのない患者に対して予測を行うようにしました。この設計は各手法の強みを取り込みつつ過学習を減らすことを目指しています。
各データセットでの手法の性能
スタックモデルは一般的な機械学習手法、人気のブースティング法、およびフィードフォワードニューラルネットワーク、畳み込みネットワーク、TabNetとして知られる近代的な表形式ネットワークを含むいくつかの深層学習アーキテクチャと比較して評価されました。臨床情報が豊富だが中程度の規模のデータセットIでは、スタッキングは約93%の精度を達成し、すべてのベースラインを上回りました。大規模でノイズの多いデータセットIIでは、ほとんどのモデルが71〜72%付近に集まり、ここではスタッキングは最良の成績と同等であり、畳み込みネットワークを明確に上回りました。構造化されたローカルデータセットIIIでは、スタッキングを含むほとんどの高度なモデルが約99%の精度を達成し、データ自体がクレンジング後にほぼ容易に分類できることを示しました。異なるランダムシードで実験を繰り返しても信頼区間は狭く、統計検定によりスタッキングが複数の競合手法より優れているという差が偶然による可能性は低いことが確認されました。
今後の心臓リスクツールにとっての意味
非専門家向けの重要なメッセージは、データの準備と複数のデータ駆動モデルの組み合わせが、個々のアルゴリズムの選択と同じくらい重要になり得るという点です。慎重なクレンジング、練られた特徴設計、情報漏洩への対策、そして複数の補完的モデルの融合を重視することで、本研究は患者集団やデータ形式が変わっても信頼性を保てる心疾患予測システムへの実践的な道筋を示しています。こうしたシステムを病院間でさらに検証し、日常利用に向けて効率的かつ説明可能にするための作業は残っていますが、よく設計されたアンサンブルは臨床医が心血管リスクをより早く、より一貫して特定するのに役立つ堅牢な意思決定支援となり得ることが示唆されます。
引用: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
キーワード: 心血管疾患予測, 機械学習, アンサンブルモデル, 臨床データ, リスク検出