Clear Sky Science · de
Ein vorverarbeitungs-verbesserter Stacking-Klassifikator zur generalisierten Erkennung von Herz-Kreislauf-Erkrankungen über verschiedene Datensätze
Warum frühe Erkennung des Herzrisikos wichtig ist
Herz- und Gefäßerkrankungen bleiben die weltweit tödlichste Erkrankungsgruppe, doch viele Menschen zeigen keine Warnzeichen, bis eine Krise eintritt. Ärztinnen und Ärzte greifen zunehmend auf Computerprogramme zurück, um subtile Risikomuster in Patientendaten lange vor dem Auftreten von Symptomen zu erkennen. Diese Studie untersucht einen neuen Weg, solche Programme zu trainieren, damit sie auch dann genau bleiben, wenn sie mit sehr unterschiedlichen Arten von medizinischen Aufzeichnungen konfrontiert werden — ein wichtiger Schritt hin zu Werkzeugen, die in vielen Krankenhäusern und Gemeinschaften zuverlässig funktionieren.
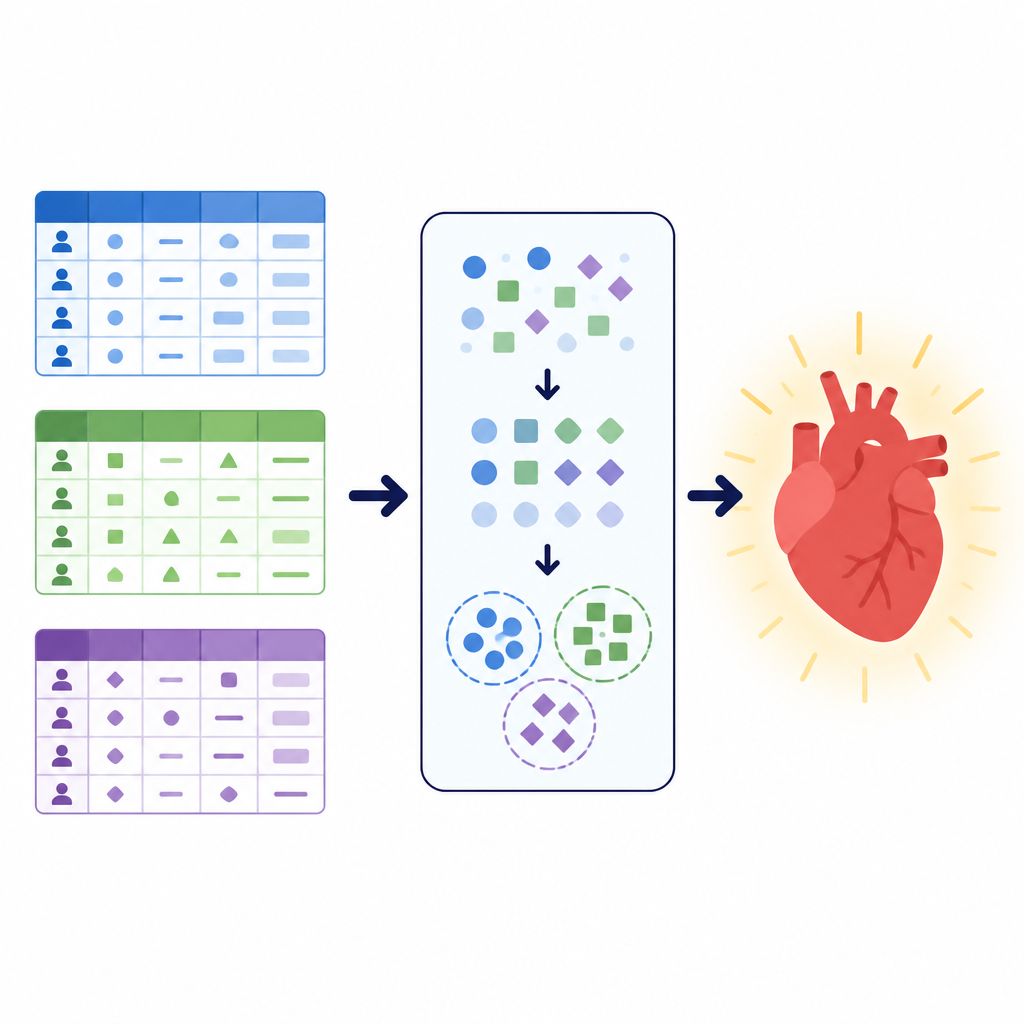
Unterschiedliche Daten, dieselbe Gesundheitsfrage
Die Forschenden konzentrierten sich auf eine einfache, aber zentrale Aufgabe: zu entscheiden, ob bei einer Person wahrscheinlich eine Herz-Kreislauf-Erkrankung vorliegt oder nicht. Sie arbeiteten mit drei großen Datensätzen, die jeweils Patienten auf verschiedene Weise beschreiben. Einer kombinierte klinische Testergebnisse wie Blutdruck, Cholesterin und Belastungs-EKG. Ein anderer mischte Basismaße wie Körpergröße und Gewicht mit Lebensstilinformationen wie Rauchen und Aktivität. Ein dritter lokaler Datensatz aus einem Krankenhaus in Pakistan legte den Schwerpunkt auf fragebogenartige Angaben zu allgemeiner Gesundheit, Schlaf, chronischen Erkrankungen sowie Rauchen oder E-Zigaretten-Nutzung, ergänzt durch einige klinische Kontrollen. Zusammen umfassten diese Sammlungen mehr als 260.000 Patientenakten und illustrierten, wie unterschiedlich Gesundheitsdaten aus der Praxis in Struktur, Sauberkeit und Verhältnis kranker zu gesunden Fällen sein können.
Patienteninformationen bereinigen und umformen
Bevor Modelle trainiert wurden, entwarf das Team eine sorgfältige Vorverarbeitungspipeline, um die Daten zu bereinigen und umzuformen. Sie entfernten doppelte Einträge, verworfen Datensätze mit fehlenden Werten im lokalen Datensatz und schränkten extreme Ausreißer bei Blutdruck und Körpermaßen im größeren öffentlichen Datensatz ein. Das Alter wurde von Tagen in Jahre umgerechnet und anschließend in Altersgruppen eingeteilt, um Muster über Datensätze hinweg besser erfassbar zu machen, die das Alter ursprünglich unterschiedlich gespeichert hatten. Neue kombinierte Merkmale wie Body-Mass-Index und mittlerer arterieller Blutdruck wurden berechnet und in einfache Kategorien eingeteilt, um die Komplexität zu reduzieren. Alle kategorischen Antworten, etwa Raucherstatus oder Brustschmerztyp, wurden erst nach der Aufteilung in Trainings- und Testmengen in numerische Codes überführt, wodurch das unerwünschte Durchsickern von Informationen zwischen diesen Mengen verhindert wurde.
Verborgene Patientengruppen mit Clustering finden
Um den Modellen zusätzlich Struktur zu geben, nutzten die Autorinnen und Autoren eine Technik namens Clustering. Anstatt zu fragen, ob jemand krank ist, sucht Clustering nach natürlichen Gruppierungen in den Daten, ohne das Diagnose-Label zu verwenden. Hier wendete das Team ein für kategoriale Informationen geeignetes Verfahren an, teilte jeden Datensatz in eine kleine Anzahl von Clustern und fügte die Clusterzugehörigkeit als neues Merkmal hinzu. Dieses zusätzliche Signal fängt Muster ein, etwa häufige Kombinationen von Symptomen oder Lebensstilfaktoren, die aus den ursprünglichen Variablen allein nicht sofort ersichtlich sind. Indem die späteren Vorhersagemodelle sowohl von den Originalmerkmalen als auch von diesen entdeckten Gruppen lernen, konnten sie sich auf organisatorischere Versionen der Patientenpopulationen konzentrieren.
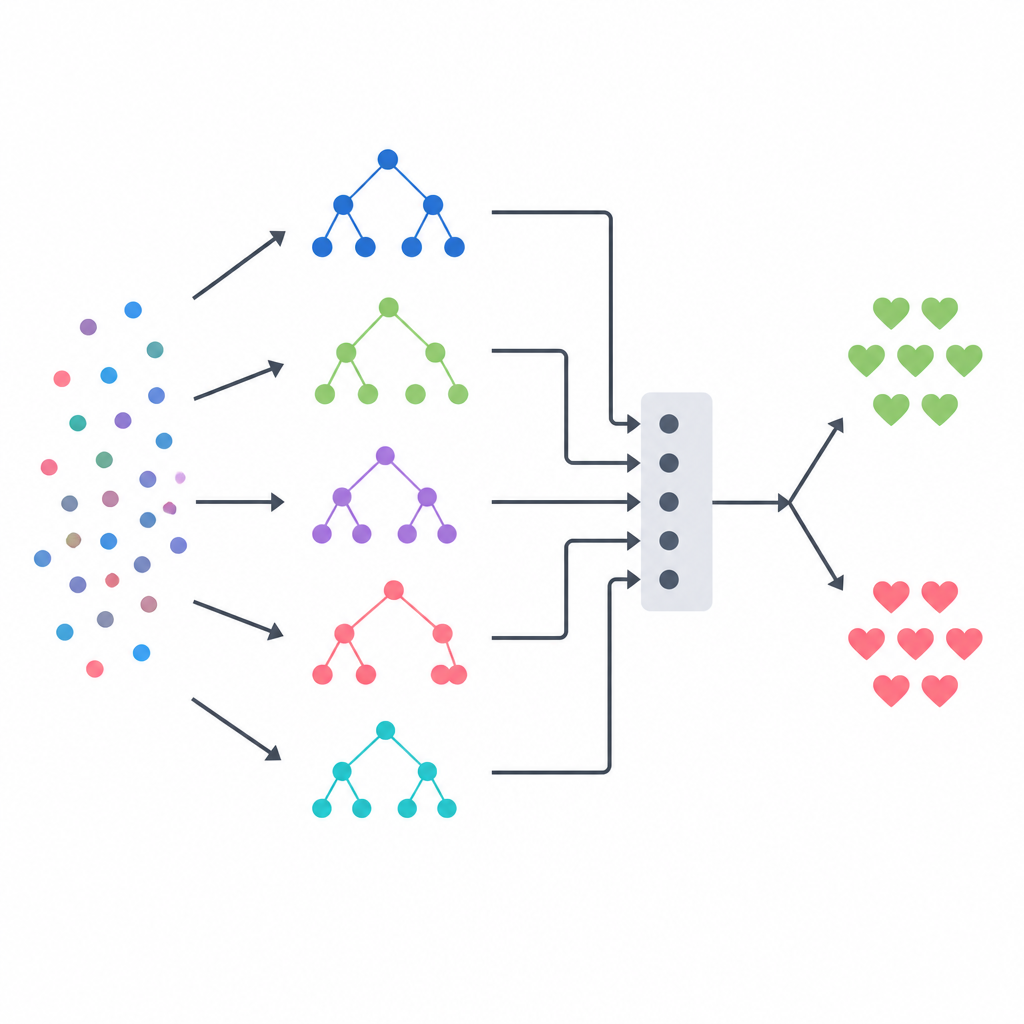
Mehrere Modelle zu einer Entscheidung verschmelzen
Kern der Vorgehensweise ist ein Stacking-Ensemble, das wie ein Gremium unterschiedlicher Expertinnen und Experten wirkt, geleitet von einem abschließenden Schiedsrichter. Drei baumbasierte Modelle — ein Entscheidungsbaum, ein Random Forest und ein extrem randomisiertes Baumsystem — geben jeweils eigene Wahrscheinlichkeitsabschätzungen für eine Erkrankung bei jedem Patienten ab. Ihre Ausgaben werden anschließend zu einem kleinen Zusammenfassungsvektor kombiniert, der an ein logistisches Regressionsmodell übergeben wird, das lernt, wie sehr jedem Basis-Modell in unterschiedlichen Situationen vertraut werden sollte. Um dem Schiedsrichter keine unfairen Hinweise zu geben, erstellte das Team seine Trainingsdaten mit einem strengen Cross-Validation-Schema, bei dem jedes Basismodell zunächst Vorhersagen für Patienten trifft, die es zuvor nicht gesehen hat. Dieses Design zielt darauf ab, die Stärken der einzelnen Verfahren zu nutzen und Überanpassung zu reduzieren.
Wie gut die Methode in den Datensätzen abschnitt
Das gestackte Modell wurde mit gängigen Methoden des maschinellen Lernens, einem populären Boosting-Ansatz und mehreren Deep-Learning-Architekturen verglichen, darunter Feedforward-Neuronale Netze, Faltungsnetze und ein modernes, tabellenorientiertes Netzwerk namens TabNet. Auf dem klinisch reichhaltigen, aber moderat großen Datensatz I erreichte Stacking etwa 93 Prozent Genauigkeit und übertraf alle Baselines. Im großen und lauten Datensatz II lagen die meisten Modelle bei etwa 71 bis 72 Prozent Genauigkeit; hier entsprach Stacking den besten Performern und übertraf deutlich das Faltungsnetz. Auf dem strukturierten lokalen Datensatz III erzielten fast alle fortgeschrittenen Modelle, einschließlich Stacking, etwa 99 Prozent Genauigkeit, was zeigt, dass die Daten selbst nach der Bereinigung leicht zu trennen waren. Wiederholte Experimente mit unterschiedlichen Zufallskeimen ergaben enge Konfidenzintervalle, und ein statistischer Test bestätigte, dass die Zuwächse durch Stacking gegenüber mehreren Konkurrenten wahrscheinlich nicht zufällig waren.
Was das für künftige Werkzeuge zur Erkennung des Herzrisikos bedeutet
Für Nichtfachleute lautet die Kernbotschaft, dass die Art und Weise, wie wir Daten vorbereiten und datengetriebene Modelle kombinieren, genauso wichtig sein kann wie die Wahl eines einzelnen Algorithmus. Indem die Studie sorgsame Bereinigung, durchdachtes Feature-Design, Schutz vor Informationsleckage und das Zusammenführen mehrerer komplementärer Modelle betont, zeigt sie einen praktischen Weg zu Systemen zur Vorhersage von Herzkrankheiten, die zuverlässig bleiben, wenn sich Populationen oder Datenformate ändern. Zwar bedarf es weiterer Arbeiten, um solche Systeme in verschiedenen Krankenhäusern zu testen sowie sie effizient und erklärbar für den Alltag zu machen, doch deuten die Ergebnisse darauf hin, dass gut konstruierte Ensembles robuste Entscheidungshilfen werden könnten, die Klinikerinnen und Kliniker dabei unterstützen, kardiovaskuläre Risiken früher und konsistenter zu identifizieren.
Zitation: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Schlüsselwörter: Vorhersage von Herz-Kreislauf-Erkrankungen, maschinelles Lernen, Ensemble-Modelle, klinische Daten, Risikodetektion