Clear Sky Science · he
מיון מצטבר משופר ע"י עיבוד מקדים לזיהוי כללי של מחלות לב וכלי דם על פני מאגרי נתונים מגוונים
מדוע גילוי מוקדם של סיכון לב חשוב
מחלות לב וכלי דם נותרו ההורג הראשי בעולם, ועדיין רבים אינם מראים סימני אזהרה עד משבר פתאומי. רופאים פונים יותר ויותר לתוכנות מחשב כדי לזהות דפוסי סיכון עדינים בנתוני מטופלים הרבה לפני הופעת תסמינים. מחקר זה בוחן דרך חדשה לאמן תוכנות כאלה כך שיישארו מדויקות כאשר הן מתמודדות עם סוגים שונים מאוד של רשומות רפואיות — צעד מרכזי לקראת כלים שעובדים באופן אמין בבתי חולים וקהילות מגוונים.
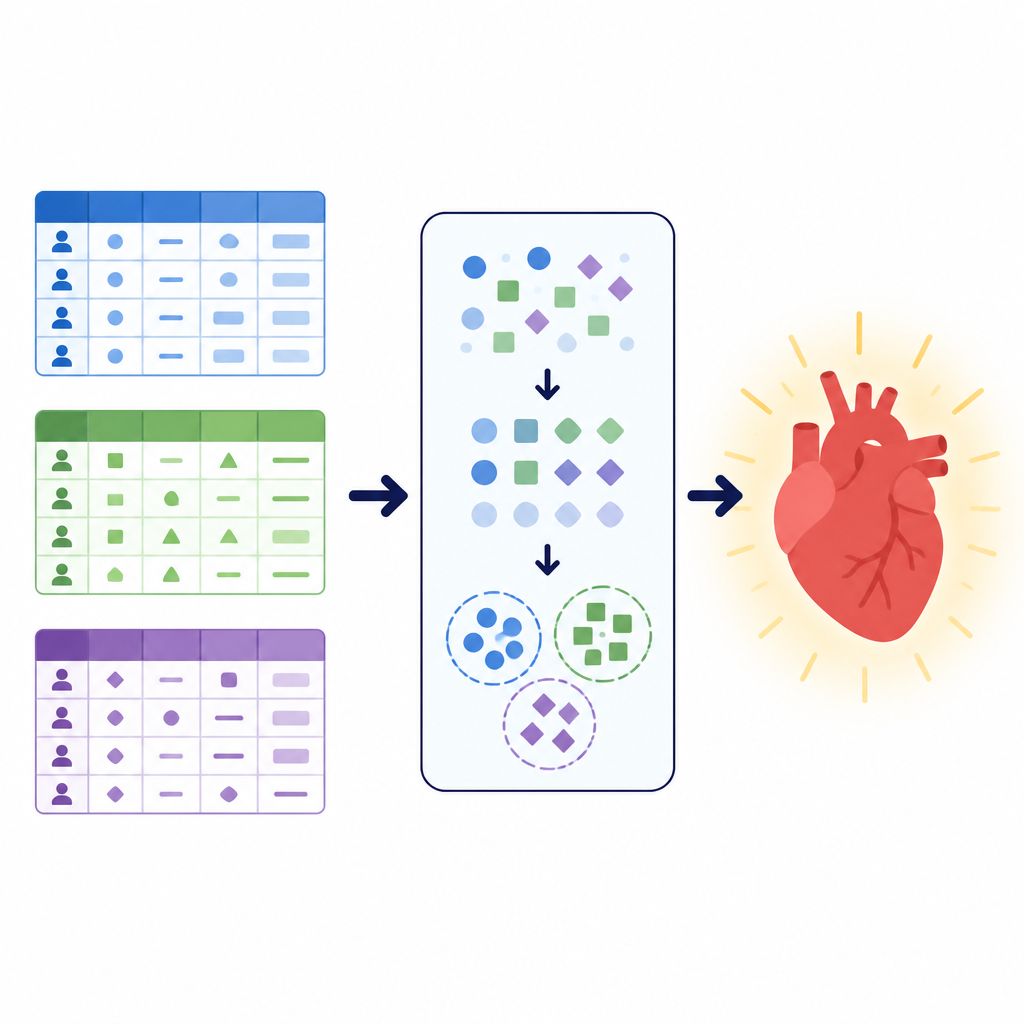
נתונים שונים, אותה שאלה בריאותית
החוקרים התרכזו במשימה פשוטה אך חיונית: להחליט האם מטופל צפוי לחלות במחלת לב וכלי דם או לא. הם עבדו עם שלושה מאגרי נתונים גדולים, שכל אחד מהם מתאר מטופלים באופן שונה. אחד כלל תוצאות בדיקות קליניות כגון לחץ דם, רמות שומנים ואלקטרוקרדיוגרמות לאחר מאמץ. אחר שילב מדידות בסיסיות כמו גובה ומשקל עם מידע על אורח חיים כגון עישון ופעילות גופנית. מאגר מקומי של בית חולים בפקיסטן הדגיש שאלוני סקר על בריאות כללית, שינה, מחלות כרוניות ושימוש בעישון או בסיגריות אלקטרוניות לצד כמה בדיקות קליניות. יחד כיסו אוספים אלה יותר מ-260,000 רשומות מטופלים והמחישו כיצד נתוני בריאות בעולם האמיתי יכולים להשתנות במבנה, בניקיון ובאיזון בין מקרים חולים ובריאים.
ניקוי ועיצוב מחדש של מידע המטופלים
לפני אימון המודלים, הצוות עיצב צינור עיבוד מקדים קפדני לניקוי ועיצוב מחדש של הנתונים. הם הסירו רשומות כפולות, פסלו רשומות עם ערכים חסרים במאגר המקומי וקיצצו ערכי קיצון בקבוצות לחץ דם ובמדידות גוף במאגר הציבורי הגדול יותר. הם המירו גיל מימים לשנים ולאחר מכן חלקו מטופלים לרצועות גיל על מנת להקל על למידת דפוסים בין מאגרים ששמרו גיל בפורמטים שונים. חישבו תכונות משולבות חדשות כגון מדד מסת גוף ולחץ דם עורקי ממוצע ומיקמו אותן בקטגוריות פשוטות להפחתת המורכבות. כל תשובות הקטגוריות, כגון סטטוס עישון או סוג כאב בחזה, הומרו לקודים מספריים רק לאחר שהנתונים חולקו לערכות אימון ובדיקה, כדי למנוע דליפה של מידע נסתר ביניהן.
איתור קבוצות מטופלים חבויות בעזרת אשכולות
כדי לתת למודלים תחושת מבנה נוספת, המחברים השתמשו בטכניקה הקרויה אשכולות. במקום לשאול האם לאדם יש מחלה, אשכולות מחפש חלוקות טבעיות בנתונים ללא שימוש בתווית האבחנה. כאן הצוות יישם שיטה המתאימה למידע קטגורי לחלק כל מאגר למספר קטן של אשכולות ואז הוסיף את השיוך לאשכול כתכונה חדשה. אות נוספת זו לוכדת דפוסים כגון שילובים נפוצים של תסמינים או גורמי אורח חיים שאינם בולטים מהמשתנים המקוריים לבדם. על ידי למידה מהתכונות המקוריות ומהקבוצות שהתגלו, המודלים החזוים המאוחרים יכלו להתמקד בגרסאות מסודרות יותר של אוכלוסיות המטופלים.
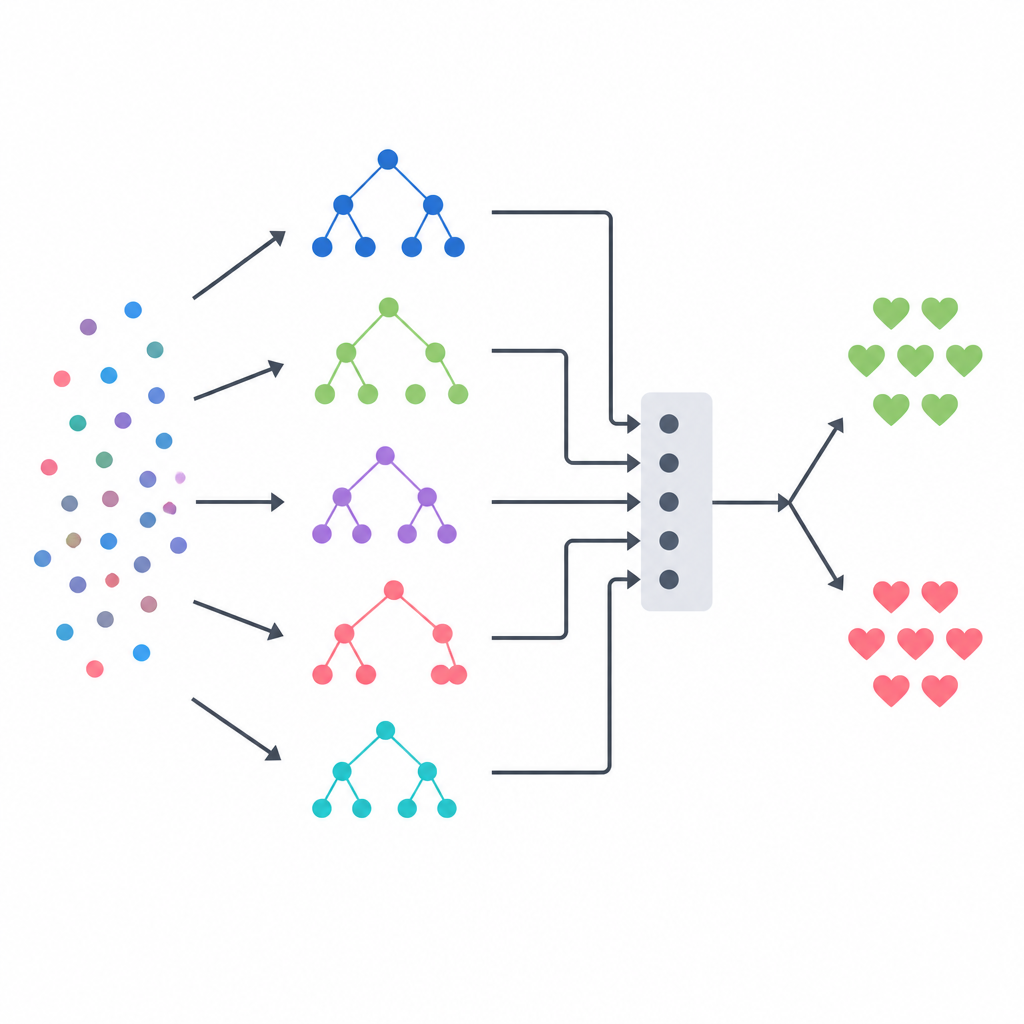
שילוב כמה מודלים להחלטה אחת
הגרעין של הגישה הוא אנסמבל בצורת stacking, הפועל כמו פאנל של מומחים מגוונים המונחה על ידי שופט סופי. שלושה מודלים מבוססי עצים — עץ החלטה, יער אקראי ומערכת עצים אקראיים במיוחד — כל אחד מהם נותן הערכות הסתברות למלל המחלה עבור כל מטופל. הפלטים שלהם משולבים לווקטור סיכום קטן, המועבר למודל רגרסיה לוגיסטית שלומד כמה לסמוך על כל מודל בסיסי במצבים שונים. כדי למנוע מתן רמזים בלתי הוגנים לשופט זה, הצוות בנה את נתוני האימון בעזרת סכמת ולידציה מצולבת מחמירה, שבה כל מודל בסיסי תחילה חוזה על מטופלים שהוא לא ראה קודם. העיצוב הזה שואף ללכוד את חוזקות כל שיטה תוך הקטנת הסיכוי להתאמה מופרזת.
כיצד השיטה הופיעה בביצועים על פני מאגרים
מודל ה-stacking נבדק מול שיטות למידת מכונה נפוצות, גישה פופולרית של boosting וכמה ארכיטקטורות למידה עמוקה, כולל רשתות עצביות Feedforward, רשתות קונבולוציוניות ורשת מודרנית המתמקדת בטבלאות הידועה בשם TabNet. במאגר הקליני העשיר אך בגודל בינוני (מאגר I), ה-stacking הגיע לכ-93 אחוזי דיוק והקדים את כל קווי הבסיס. במאגר הגדול והרועש (מאגר II), רוב המודלים התקבצו סביב 71–72 אחוז דיוק; כאן ה-stacking השווה לביצועים הטובים ביותר והצטיין על פני הרשת הקונבולוציונית. במאגר המקומי המבוסס היטב (מאגר III), כמעט כל המודלים המתקדמים, כולל ה-stacking, השיגו כ-99 אחוז דיוק, מה שמראה כי הנתונים עצמם היו קלים להפרדה לאחר ניקוי. חזרה על הניסויים עם זרעים אקראיים שונים יצרה מרווחי ביטחון צרים, ובדיקה סטטיסטית אישרה שרווחי ה-stacking מול מספר מתחרים אינם סיכוייים בלבד.
מה משמעות הדבר לכלי עתידי לזיהוי סיכון לב
עבור הלא-מומחים, המסר המרכזי הוא שדרך ההכנה והשילוב של מודלים מבוססי נתונים יכולה להיות חשובה לא פחות מבחירת האלגוריתם הבודד. על ידי הדגשת ניקוי קפדני, עיצוב תכונות מושכל, הגנה מפני דליפת מידע ושילוב של מודלים משלימים מרובים, מחקר זה מראה מסלול מעשי למערכות חיזוי מחלות לב שישארו אמינות כאשר אוכלוסיית המטופלים או פורמט הנתונים משתנים. בעוד נדרשת עבודה נוספת כדי לבדוק מערכות כאלה בבתי חולים שונים ולגרום להן להיות יעילות וברורות לשימוש יומיומי, התוצאות מרמזות שמערכי אנשברי מהונדסים היטב יכולים להפוך לסיוע החלטתי יציב שיעזור לרופאים לזהות סיכון לב מוקדם ובהתמדה רבה יותר.
ציטוט: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
מילות מפתח: חיזוי מחלות לב וכלי דם, למידת מכונה, מודלים מצורפים, נתונים קליניים, זיהוי סיכון