Clear Sky Science · ru
Классификатор стекинга с улучшенной предобработкой для обобщённого обнаружения сердечно-сосудистых заболеваний в разнообразных наборах данных
Почему важно раннее обнаружение риска для сердца
Заболевания сердца и сосудов остаются главной причиной смерти в мире, при этом многие люди не имеют явных признаков до наступления кризиса. Врачи всё чаще обращаются к компьютерным программам, чтобы обнаруживать тонкие паттерны риска в данных пациентов задолго до появления симптомов. В этом исследовании изучается новый способ обучения таких программ, чтобы они сохраняли точность при работе с очень разными типами медицинских записей — ключевой шаг к инструментам, которые надёжно работают в различных больницах и сообществах.
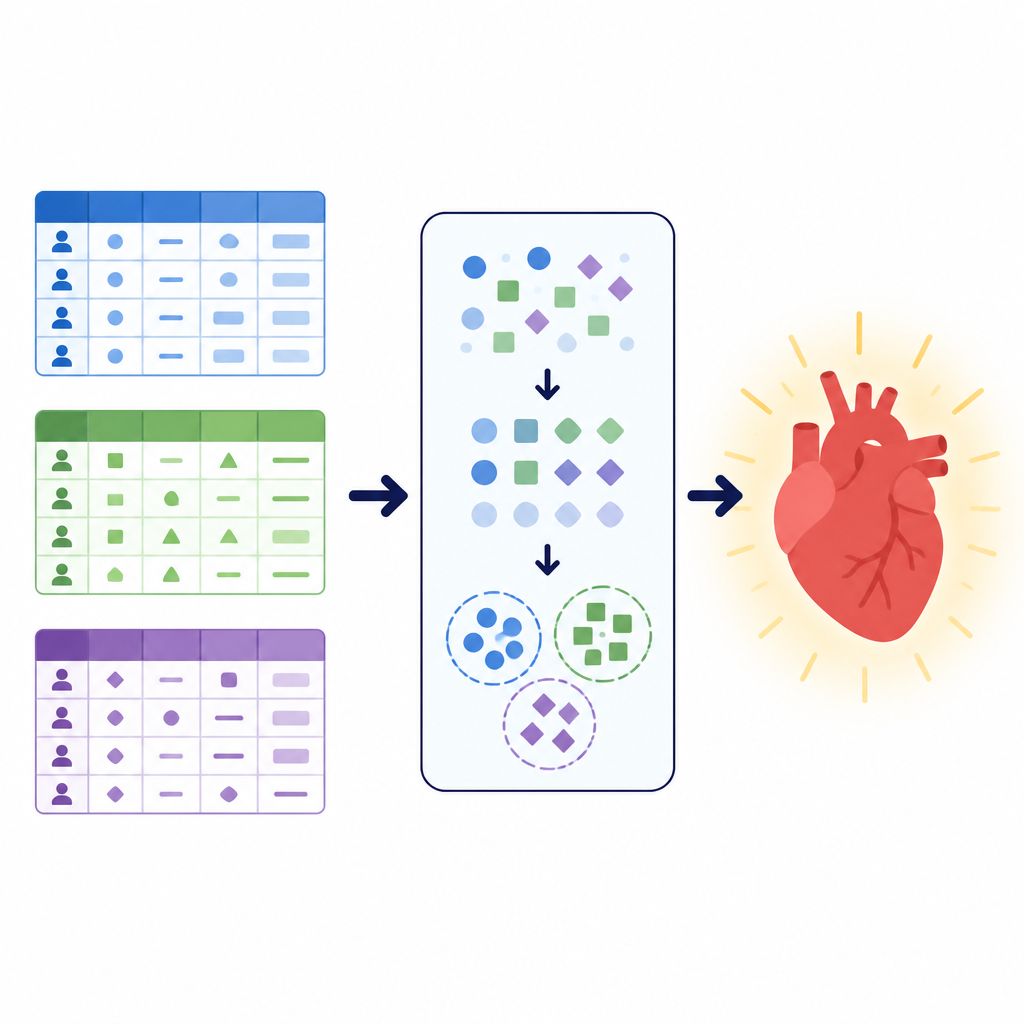
Разные данные — один медицинский вопрос
Авторы сосредоточились на простой, но важной задаче: определить, с большой ли вероятностью у пациента есть сердечно-сосудистое заболевание. Они использовали три больших набора данных, каждый из которых описывал пациентов по-разному. Один объединял результаты клинических тестов — такие как артериальное давление, уровень холестерина и электрокардиограммы при нагрузке. Другой сочетал базовые измерения вроде роста и веса с информацией об образе жизни, например курением и физической активностью. Третий локальный набор из больницы в Пакистане делал упор на опросные вопросы о общем состоянии здоровья, сне, хронических заболеваниях и курении или использовании электронных сигарет, наряду с несколькими клиническими проверками. В совокупности эти коллекции покрывали более 260 000 записей пациентов и демонстрировали, как реальные медицинские данные могут различаться по структуре, чистоте и соотношению больных и здоровых случаев.
Очистка и преобразование данных пациентов
Перед обучением моделей команда разработала тщательный конвейер предобработки для очистки и преобразования данных. Были удалены дубликаты, в локальном наборе исключили записи с пропущенными значениями, а в большем публичном наборе отсекли экстремальные выбросы по артериальному давлению и параметрам телосложения. Возраст преобразовали из дней в годы и затем сгруппировали в возрастные категории, чтобы облегчить выявление закономерностей в наборах, где возраст хранился по-разному. Были рассчитаны новые комбинированные признаки, такие как индекс массы тела и среднее артериальное давление, и приведены к простым категориям для снижения сложности. Все категориальные ответы, например статус курения или тип боли в груди, переводили в числовые коды только после разделения данных на обучающую и тестовую выборки, что предотвратило утечку скрытой информации между ними.
Поиск скрытых групп пациентов с помощью кластеризации
Чтобы дать моделям дополнительную структуру, авторы использовали метод кластеризации. Вместо того чтобы напрямую опираться на метку диагноза, кластеризация ищет естественные группы в данных без её участия. В этой работе команда применила метод, подходящий для категориальной информации, чтобы разделить каждый набор на небольшое число кластеров и затем добавила принадлежность к кластеру как новый признак. Этот дополнительный сигнал фиксирует сочетания симптомов или факторов образа жизни, которые могут быть неочевидны из исходных переменных. Обучаясь как на оригинальных признаках, так и на этих найденных группах, последующие предсказательные модели могли опираться на более организованные представления популяции пациентов.
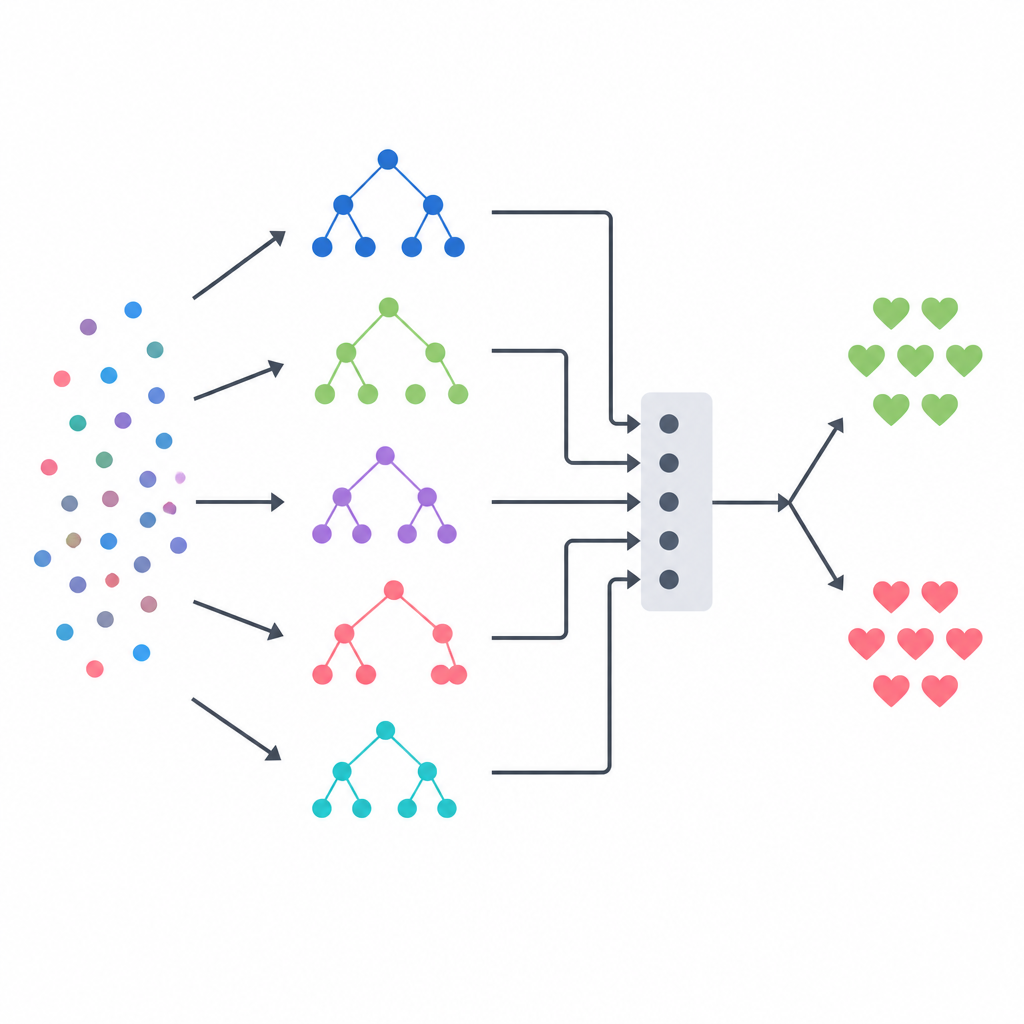
Смешивание нескольких моделей в одно решение
Ядром подхода является стекинг-ансамбль, который действует как панель разнообразных экспертов, управляемая финальным арбитром. Три основанные на деревьях модели — дерево решений, случайный лес и система чрезвычайно рандомизированных деревьев — каждая формирует свои оценки вероятности наличия заболевания для каждого пациента. Их выходы затем объединяются в небольшой сводный вектор, который передаётся логистической регрессии, обучающейся, сколько доверять каждому базовому методу в разных ситуациях. Чтобы не давать «арбитру» нечестных подсказок, команда формировала обучающие данные в строгой схеме перекрёстной проверки, при которой каждая базовая модель сначала предсказывает для пациентов, которых она ранее не видела. Такая конструкция направлена на сохранение сильных сторон каждого метода при снижении переобучения.
Насколько хорошо метод показал себя на разных наборах данных
Стекированная модель сравнивалась с обычными методами машинного обучения, популярным бустинговым подходом и несколькими архитектурами глубокого обучения, включая полносвязные нейронные сети, сверточные сети и современную сетевую архитектуру для табличных данных, известную как TabNet. На клинически насыщенном, но умеренно маленьком Наборе данных I стекинг достиг примерно 93% точности и превзошёл все базовые методы. На большом и шумном Наборе данных II большинство моделей показали точность около 71–72%; здесь стекинг сравнялся с лучшими участниками и заметно превзошёл сверточную сеть. На структурированном локальном Наборе данных III почти все продвинутые модели, включая стекинг, показали около 99% точности, что указывает на то, что после очистки данные было легко разделять. Повторение экспериментов с разными случайными начальными состояниями дало узкие доверительные интервалы, а статистический тест подтвердил, что преимущества стекинга над несколькими соперниками вряд ли объясняются случайностью.
Что это значит для будущих инструментов оценки сердечного риска
Для неспециалистов главный вывод состоит в том, что то, как мы готовим данные и комбинируем модели, может быть не менее важно, чем выбор конкретного алгоритма. Подчёркивая тщательную очистку, продуманную конструировку признаков, защиту от утечки информации и сочетание нескольких взаимодополняющих моделей, исследование демонстрирует практический путь к системам прогнозирования сердечных заболеваний, которые остаются надёжными при изменении популяции пациентов или формата данных. Хотя требуется дополнительная проверка таких систем в разных больницах, а также работа над их эффективностью и объяснимостью для повседневного использования, результаты указывают на то, что грамотно сконструированные ансамбли могут стать надёжными помощниками врачей в более ранней и последовательной идентификации сердечно-сосудистого риска.
Цитирование: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Ключевые слова: прогнозирование сердечно-сосудистых заболеваний, машинное обучение, ансамблевые модели, клинические данные, выявление риска