Clear Sky Science · es
Un clasificador apilado mejorado por preprocesamiento para la detección generalizada de enfermedades cardiovasculares en conjuntos de datos diversos
Por qué importa la detección temprana del riesgo cardíaco
Las enfermedades del corazón y de los vasos sanguíneos siguen siendo la principal causa de muerte en el mundo, y sin embargo muchas personas no muestran signos de advertencia hasta que ocurre una crisis. Los médicos recurren cada vez más a programas informáticos para detectar patrones sutiles de riesgo en los datos de los pacientes mucho antes de que aparezcan los síntomas. Este estudio explora una nueva forma de entrenar dichos programas para que mantengan la precisión cuando se enfrentan a tipos muy diferentes de registros médicos, un paso clave hacia herramientas que funcionen con fiabilidad en muchos hospitales y comunidades.
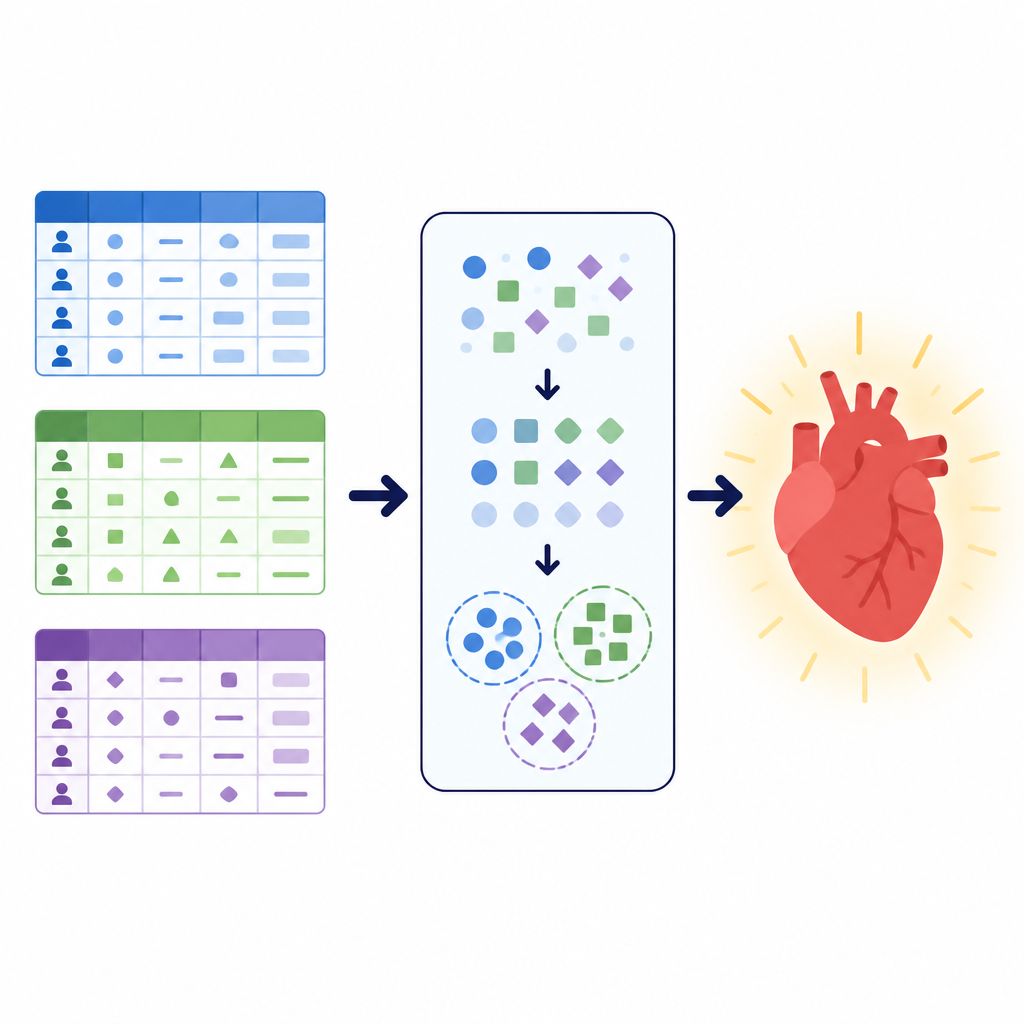
Datos diferentes, misma pregunta de salud
Los investigadores se centraron en una tarea sencilla pero vital: decidir si un paciente tiene probabilidades de padecer una enfermedad cardiovascular o no. Trabajaron con tres grandes conjuntos de datos, cada uno describiendo a los pacientes de manera distinta. Uno combinaba resultados de pruebas clínicas como presión arterial, colesterol y electrocardiogramas de esfuerzo. Otro mezclaba medidas básicas como altura y peso con información sobre el estilo de vida, como el tabaquismo y la actividad física. Un tercer conjunto local de un hospital en Pakistán enfatizaba preguntas de estilo encuesta sobre salud general, sueño, enfermedades crónicas y consumo de tabaco o cigarrillos electrónicos, junto con algunas comprobaciones clínicas. En conjunto, estas colecciones abarcaron más de 260.000 registros de pacientes e ilustraron cómo los datos sanitarios del mundo real pueden variar en estructura, limpieza y equilibrio entre casos enfermos y sanos.
Limpiar y remodelar la información del paciente
Antes de entrenar cualquier modelo, el equipo diseñó una canalización de preprocesamiento cuidadosa para limpiar y remodelar los datos. Eliminó entradas duplicadas, descartó registros con valores faltantes en el conjunto de datos local y recortó valores extremos atípicos en la presión arterial y el tamaño corporal del conjunto público más grande. Convirtieron la edad de días a años y luego agruparon a los pacientes en bandas de edad para facilitar que los patrones se aprendieran entre conjuntos que originalmente almacenaban la edad de forma distinta. Se calcularon nuevas características combinadas, como el índice de masa corporal y la presión arterial media, y se colocaron en categorías simples para reducir la complejidad. Todas las respuestas categóricas, como el estado de fumador o el tipo de dolor torácico, se convirtieron en códigos numéricos solo después de que los datos se hubieran dividido en conjuntos de entrenamiento y de prueba, evitando que información oculta se filtrara entre ellos.
Encontrar grupos ocultos de pacientes mediante clustering
Para dar a los modelos una sensación adicional de estructura, los autores utilizaron una técnica llamada clustering. En lugar de preguntar si alguien tiene la enfermedad, el clustering busca agrupaciones naturales en los datos sin usar la etiqueta de diagnóstico. Aquí, el equipo aplicó un método adecuado para información categórica para dividir cada conjunto de datos en un pequeño número de clústeres y luego añadió la asignación de clúster como una nueva característica. Esta señal adicional captura patrones como combinaciones comunes de síntomas o factores de estilo de vida que pueden no ser obvios a partir de las variables originales. Al aprender tanto de las características originales como de estos grupos descubiertos, los modelos de predicción posteriores pudieron centrarse en versiones más organizadas de las poblaciones de pacientes.
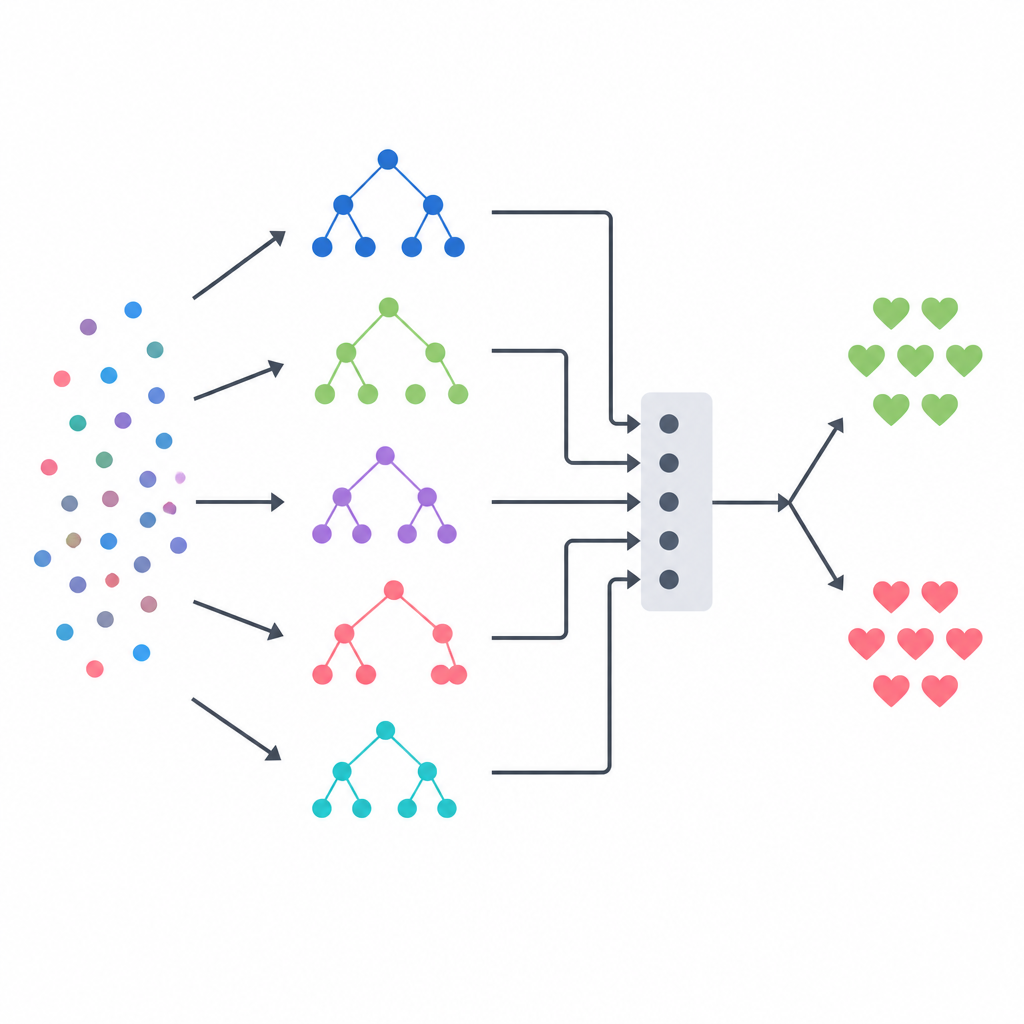
Combinar varios modelos en una decisión
El núcleo del enfoque es un ensemble por apilamiento (stacking), que actúa como un panel de expertos diversos guiado por un árbitro final. Tres modelos basados en árboles —un árbol de decisión, un bosque aleatorio y un sistema de árboles extremadamente aleatorizados— hacen cada uno sus propias estimaciones de probabilidad de enfermedad para cada paciente. Sus salidas se combinan en un pequeño vector resumen, que se pasa a un modelo de regresión logística que aprende cuánto confiar en cada modelo base en distintas situaciones. Para evitar dar pistas injustas a este árbitro, el equipo construyó sus datos de entrenamiento usando un esquema estricto de validación cruzada, donde cada modelo base primero predice sobre pacientes que no ha visto antes. Este diseño busca capturar las fortalezas de cada método a la vez que reduce el sobreajuste.
Cómo funcionó el método en los distintos conjuntos de datos
El modelo apilado se comparó con métodos comunes de aprendizaje automático, un enfoque de boosting popular y varias arquitecturas de aprendizaje profundo, incluidas redes neuronales feedforward, redes convolucionales y una red moderna orientada a tablas conocida como TabNet. En el Dataset I, clínicamente rico pero de tamaño moderado, el stacking alcanzó alrededor del 93 por ciento de precisión y superó a todos los puntos de referencia. En el grande y ruidoso Dataset II, la mayoría de los modelos se agruparon alrededor del 71 al 72 por ciento de precisión; aquí el stacking igualó a los mejores y claramente superó a la red convolucional. En el estructurado Dataset III local, casi todos los modelos avanzados, incluido el stacking, alcanzaron aproximadamente el 99 por ciento de precisión, lo que muestra que los datos en sí eran fáciles de separar una vez limpiados. Repetir los experimentos con diferentes semillas aleatorias produjo intervalos de confianza estrechos, y una prueba estadística confirmó que las ganancias del stacking sobre varios rivales eran poco probables por azar.
Qué significa esto para futuras herramientas de riesgo cardíaco
Para los no especialistas, el mensaje clave es que la forma en que preparamos y combinamos modelos basados en datos puede importar tanto como la elección de un algoritmo individual. Al enfatizar la limpieza cuidadosa, el diseño reflexivo de características, la protección contra la filtración de información y la combinación de múltiples modelos complementarios, este estudio muestra una vía práctica hacia sistemas de predicción de enfermedades cardíacas que se mantienen fiables cuando cambia la población de pacientes o el formato de los datos. Aunque se necesita más trabajo para probar dichos sistemas entre hospitales y para hacerlos eficientes y explicables para el uso cotidiano, los resultados sugieren que los ensembles bien diseñados podrían convertirse en ayudas de decisión robustas para ayudar a los clínicos a identificar el riesgo cardiovascular de forma más temprana y consistente.
Cita: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Palabras clave: predicción de enfermedades cardiovasculares, aprendizaje automático, modelos ensemble, datos clínicos, detección de riesgo