Clear Sky Science · tr
Çeşitli veri kümeleri arasında genelleştirilmiş kardiyovasküler hastalık tespiti için ön işleme ile güçlendirilmiş bir birleştirme sınıflandırıcısı
Erken kalp riski tespitinin önemi
Kalp ve damar hastalıkları dünya çapında en çok can alan hastalık olmaya devam ediyor, ancak birçok kişide kriz ortaya çıkana kadar uyarı işaretleri yok. Doktorlar, semptomlar ortaya çıkmadan çok önce hasta verilerindeki ince risk desenlerini tespit etmek için giderek daha fazla bilgisayar programlarına yöneliyor. Bu çalışma, böyle programları eğitmenin yeni bir yolunu araştırıyor; amaç, çok farklı tıbbi kayıt türleriyle karşılaşıldığında bile doğruluğunu koruyan modeller geliştirmek—bu, birçok hastane ve toplumda güvenilir şekilde çalışacak araçlara doğru atılan önemli bir adım.
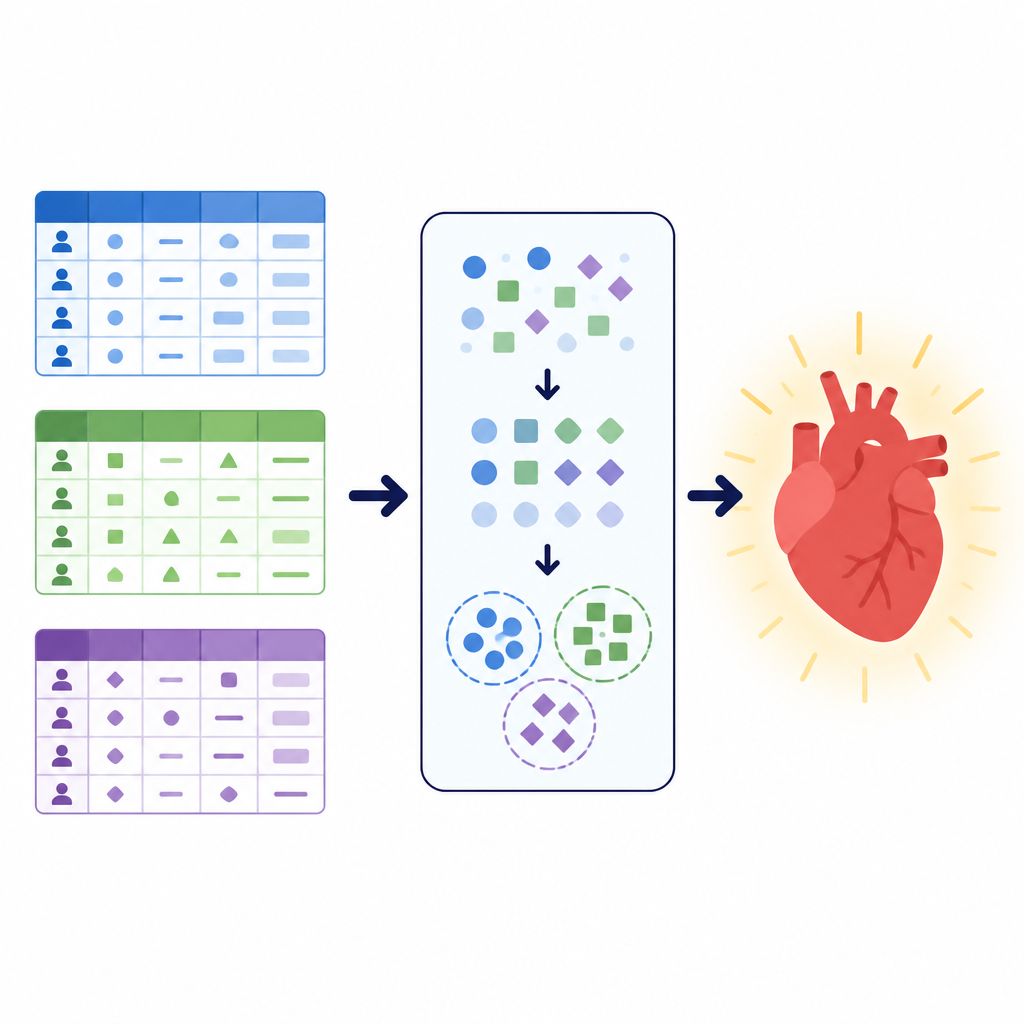
Farklı veriler, aynı sağlık sorusu
Araştırmacılar basit ama hayati bir göreve odaklandı: bir hastanın kardiyovasküler hastalığa sahip olup olmayacağını belirlemek. Üç büyük veri kümesi ile çalıştılar; her biri hastaları farklı biçimlerde tanımlıyordu. Birincisi kan basıncı, kolesterol ve egzersiz elektrokardiyogramları gibi klinik test sonuçlarını birleştiriyordu. İkincisi boy ve kilo gibi temel ölçümleri sigara ve aktivite gibi yaşam tarzı bilgileriyle karıştırıyordu. Üçüncü, Pakistan’daki bir hastaneden elde edilen yerel veri kümesi, genel sağlık, uyku, kronik durumlar ve sigara ya da elektronik sigara kullanımı hakkında anket tarzı soruları birkaç klinik kontrol ile vurguluyordu. Bu koleksiyonlar birlikte 260.000’den fazla hasta kaydını kapsıyor ve gerçek dünya sağlık verilerinin yapı, temizlik ve hasta- sağlıklı denge açısından nasıl değişebileceğini gösteriyordu.
Hasta bilgilerinin temizlenmesi ve yeniden şekillendirilmesi
Herhangi bir model eğitmeden önce ekip, veriyi temizlemek ve yeniden şekillendirmek için dikkatli bir ön işleme hattı tasarladı. Yinelenen girdiler kaldırıldı, yerel veri kümesinde eksik değer içeren kayıtlar elendi ve daha büyük halka açık veri kümesindeki kan basıncı ve vücut ölçümlerindeki aşırı uçlar kırpıldı. Yaş günlerden yıla dönüştürüldü ve daha sonra orijinalde farklı şekilde saklanan veri kümeleri arasında desenleri öğrenmeyi kolaylaştırmak için yaş bantlarına gruplanmış. Vücut kitle indeksi ve ortalama arteriyel kan basıncı gibi yeni birleşik özellikler hesaplandı ve karmaşıklığı azaltmak için basit kategorilere yerleştirildi. Sigara durumu veya göğüs ağrısı türü gibi tüm kategorik yanıtlar, veri eğitim ve test kümelerine ayrıldıktan sonra sayısal kodlara dönüştürüldü; bu, gizli bilgi sızıntısını önledi.
Kümeleme ile gizli hasta gruplarını bulmak
Modellere ekstra yapı hissi vermek için yazarlar kümeleme adı verilen bir teknik kullandı. Birinin hastalığı olup olmadığını sormak yerine kümeleme, tanı etiketi kullanmadan veride doğal gruplamalar arar. Burada ekip, kategorik bilgiye uygun bir yöntem uygulayıp her veri kümesini az sayıda kümeye böldü ve ardından küme atamasını yeni bir özellik olarak ekledi. Bu ek sinyal, orijinal değişkenlerden açıkça görünmeyebilecek belirti veya yaşam tarzı faktörlerinin ortak bileşimleri gibi desenleri yakalar. Hem orijinal özelliklerden hem de keşfedilen bu gruplardan öğrenerek, sonraki tahmin modelleri hasta popülasyonlarının daha düzenli versiyonlarına odaklanabildi.
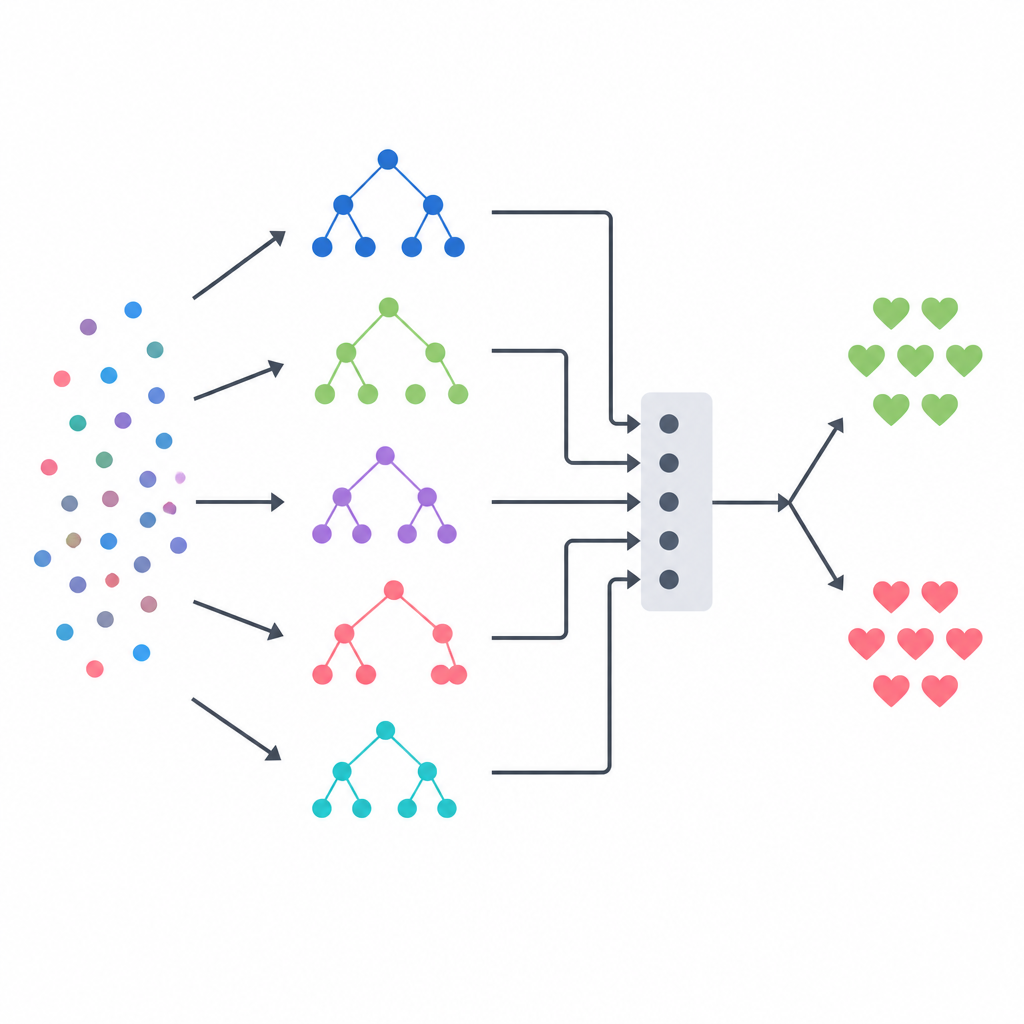
Birkaç modeli tek bir karara karıştırmak
Yaklaşımın çekirdeği, son hakemin yönlendirdiği çeşitli uzmanlardan oluşan bir panel gibi davranan bir stacking ansamblidir. Bir karar ağacı, bir rastgele orman ve aşırı rastgeleleştirilmiş bir ağaç sistemi olmak üzere üç ağaç tabanlı model her hasta için hastalık olasılığı tahminleri yapar. Bunların çıktıları daha sonra küçük bir özet vektörüne dönüştürülür ve hangi temel modele farklı durumlarda ne kadar güvenileceğini öğrenen bir lojistik regresyon modeline verilir. Bu hakeme haksız ipuçları verilmemesi için ekip, her temel modelin daha önce görmediği hastalar üzerinde ilk olarak tahmin yaptığı katı bir çapraz doğrulama şeması kullanarak eğitim verilerini oluşturdu. Bu tasarım, her yöntemin güçlü yönlerini yakalamayı ve aşırı uyumu azaltmayı amaçlar.
Yöntemin veri kümeleri arasındaki performansı
Stacking modeli, yaygın makine öğrenimi yöntemleri, popüler bir boosting yaklaşımı ve feedforward sinir ağları, konvolüsyonel ağlar ve TabNet olarak bilinen modern tablo odaklı bir ağ dahil olmak üzere birkaç derin öğrenme mimarisine karşı test edildi. Klinik açıdan zengin ama orta boyuttaki Veri Kümesi I üzerinde stacking yaklaşık yüzde 93 doğruluğa ulaştı ve tüm temellerin üzerinde performans gösterdi. Büyük ve gürültülü Veri Kümesi II’de çoğu model yaklaşık yüzde 71–72 doğruluk etrafında kümelendi; burada stacking en iyi performans gösterenlerle eşleşti ve konvolüsyonel ağı belirgin şekilde geride bıraktı. Yapılandırılmış yerel Veri Kümesi III’te neredeyse tüm gelişmiş modeller, stacking dahil, yaklaşık yüzde 99 doğruluk elde etti; bu, verinin temizlendikten sonra ayrımının kolay olduğunu gösteriyor. Denemelerin farklı rastgele tohumlarla tekrarlanması dar güven aralıkları üretti ve istatistiksel bir test stacking’in birkaç rakip üzerindeki kazançlarının tesadüfe dayalı olma olasılığının düşük olduğunu doğruladı.
Gelecekteki kalp risk araçları için anlamı
Uzman olmayanlar için ana mesaj, veriyi nasıl hazırladığımızın ve veri odaklı modelleri nasıl birleştirdiğimizin tek bir algoritma seçiminden en az onun kadar önemli olabileceğidir. Dikkatli temizleme, düşünülmüş özellik tasarımı, bilgi sızıntısına karşı koruma ve birbiriyle tamamlayıcı birden fazla modelin birleştirilmesine önem vererek, bu çalışma hasta popülasyonu veya veri formatı değiştiğinde bile güvenilir kalan kalp hastalığı tahmin sistemlerine yönelik pratik bir yol gösteriyor. Bu tür sistemleri hastaneler arasında test etmek, günlük kullanım için verimli ve açıklanabilir hale getirmek için daha fazla çalışma gerekse de, iyi mühendislik yapılmış ansambl yöntemlerinin klinisyenlerin kardiyovasküler riski daha erken ve daha tutarlı şekilde tespit etmelerine yardımcı olacak sağlam karar destekleri haline gelebileceğini gösteriyor.
Atıf: Ashraf, A., Masih, A., Saddiqa, A. et al. A preprocessing-enhanced stacking classifier for generalized cardiovascular disease detection across diverse datasets. Sci Rep 16, 16206 (2026). https://doi.org/10.1038/s41598-026-41042-z
Anahtar kelimeler: kardiyovasküler hastalık tahmini, makine öğrenimi, ansambl modeller, klinik veri, risk tespiti