Clear Sky Science · zh
揭示用于自然语言处理的深度神经网络的先进迁移学习策略
为何更智能的语言工具至关重要
从电子邮件过滤到聊天机器人和翻译应用,许多当今的数字工具都依赖能读写人类语言的计算机。完全从头训练这些系统成本高且需要大量数据,因此研究者常常以大型、已训练的语言模型为起点,将其适配到新任务——这种做法称为迁移学习。本文系统性地考察了不同适配方式的表现,比较了七种策略在多类语言任务上的效果,旨在找出在准确性、速度和实际可行性之间最佳的折衷。
机器如何重用已有知识
研究首先解释了现代语言系统如何从海量文本中学习并将这些知识迁移到新任务上。像 BERT 及其更大的变体(在本文中称为 BERT-3)等知名模型先学习词语和句子的通用模式,随后会被调整以完成具体目标,例如对新闻主题进行分类、判断社交媒体帖子的语气,或在英语与法语之间进行翻译。作者将“全量微调”(即对模型的每个部分都进行调整)与将大模型作为冻结特征提取器并喂给更小、更简单模型的“基于特征”的方法进行了对比。他们还强调了改变数据呈现方式的策略,包括从简单样本开始、逐步过渡到更难样本的渐进训练。
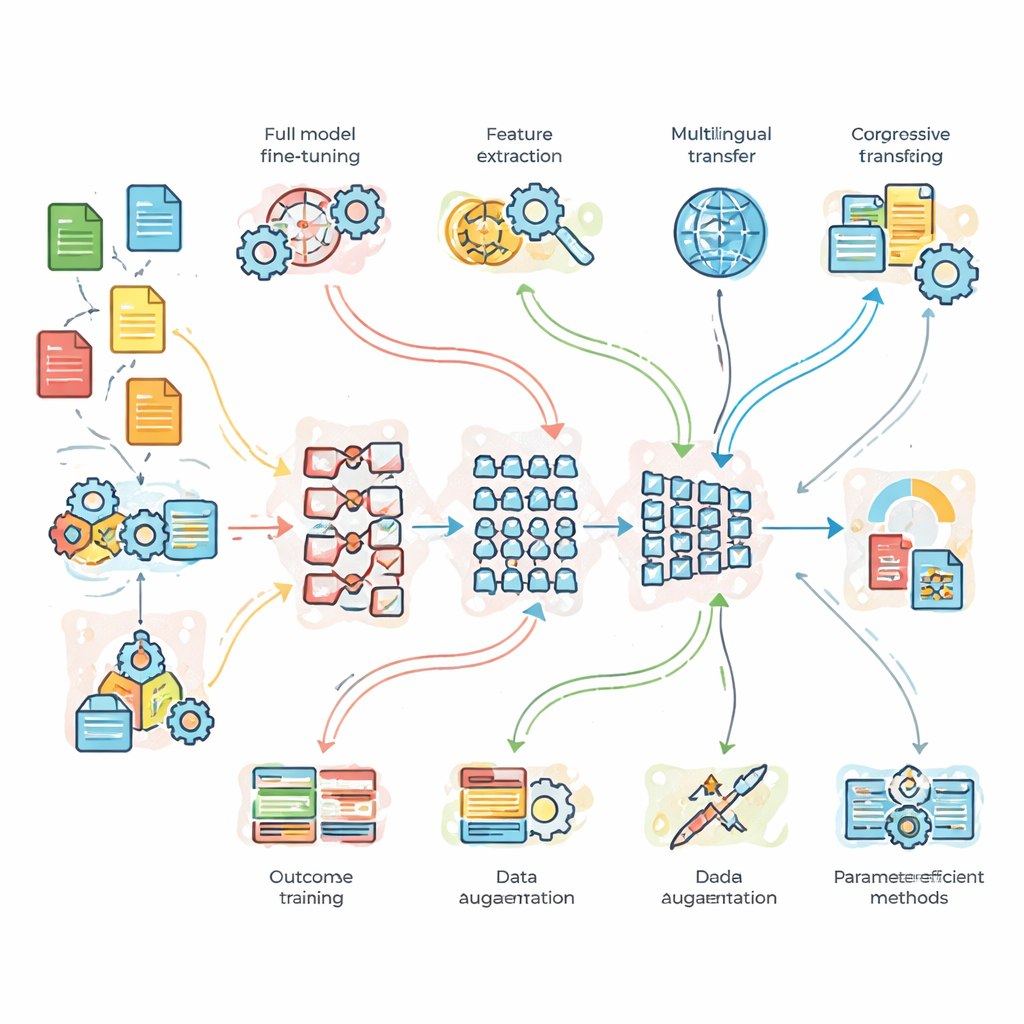
研究者在实践中测试了什么
为了超越理论,团队在三个基准问题上进行了受控实验。首先是数据充足且干净的新闻主题分类任务;其次是包含噪声和俚语的推文情感分析;第三是英语到法语的翻译。他们比较了一个轻量的自制基线网络、标准 BERT 和更深的 BERT-3 模型。在此基础上叠加了七种适配策略:全量微调、基于特征的迁移、渐进训练和领域自适应训练、多语种微调、数据增强(例如通过改写句子),以及两种现代的“参数高效”方法,这些方法仅调整模型内部很小一部分参数。这样的设置让他们不仅能问哪种模型最强,还能评估额外复杂性或更多数据何时真正带来收益。
哪些模型与策略脱颖而出
结果显示出明确模式:在更具挑战性的任务上,尤其是情感分析和翻译,更大的 BERT-3 模型持续优于标准 BERT 和轻量基线。然而,在简单的新闻分类任务上,简单模型仍然出人意料地具有竞争力,这强调了并非总是需要更大模型。在训练策略方面,渐进式和领域自适应微调在总体得分上表现最佳,尤其是在措辞更长或更复杂的难例上。数据增强也有助益,类似于通过对现有句子改写来获得额外训练数据。关键的是,两种参数高效方法——适配器层(adapter layers)和称为 LoRA 的方法——在仅更新不到五个百分点的模型参数的情况下,性能接近最佳,从而大幅降低了内存和计算需求。
为何数据量和语言多样性依然重要
研究还探讨了在使用迁移学习时需要多少带标签的数据。随着训练样本的增加,准确率稳步上升,但由于以预训练模型为起点,即便只有约 1,000 个样本的实验也能达到通常需要更多数据才能实现的表现。在更干净的基准上,收益在大约 20,000 个样本时开始趋于平缓,尽管更复杂、更嘈杂的数据集仍能从更大的训练集获益。多语种模型(在多种语言上共同训练)在某种语言的标注数据稀缺时非常有用,但当有大量英语样本可用时,它们可能略逊于单语言模型,这表明在广泛覆盖与细粒度专门化之间存在权衡。
这对未来语言技术意味着什么
对非本领域读者而言,主要结论是:没有单一的“最佳”配方来适配大型语言模型。像 BERT-3 这样更大的模型在理解和翻译等具有挑战性的任务上表现出色,而较小的网络在较简单的任务上可能完全足够。逐步引入任务或通过改写示例扩展训练集的方法通常能提高系统的稳健性,尤其是在数据受限时。或许最重要的是,仅调整小型附加组件的新技术能够以极低的成本获得接近顶级的准确率。综合来看,这些发现意味着未来可以更精确地根据不同公司、语言和应用的需求与资源来定制强大的语言工具,使先进的自然语言处理更可及、更高效。
引用: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
关键词: 迁移学习, 自然语言处理, 微调策略, 大型语言模型, 参数高效方法