Clear Sky Science · fr
Découvrir des stratégies avancées de transfert d’apprentissage pour les réseaux neuronaux profonds en traitement du langage naturel
Pourquoi des outils linguistiques plus intelligents comptent
Des filtres anti-spam aux chatbots en passant par les applications de traduction, nombre des outils numériques d’aujourd’hui reposent sur des ordinateurs capables de lire et d’écrire le langage humain. Entraîner ces systèmes à partir de zéro coûte cher et demande beaucoup de données, aussi les chercheurs partent-ils souvent de grands modèles linguistiques déjà entraînés pour les adapter à de nouvelles tâches — une pratique appelée transfert d’apprentissage. Cet article examine de manière systématique les différentes façons d’effectuer cette adaptation, comparant sept stratégies sur plusieurs types de tâches linguistiques afin de déterminer lesquelles offrent le meilleur compromis entre précision, rapidité et applicabilité en conditions réelles.
Comment les machines réutilisent ce qu’elles savent déjà
L’étude commence par expliquer comment les systèmes modernes apprennent à partir d’énormes collections de textes puis réutilisent ces connaissances sur de nouvelles tâches. Des modèles bien connus comme BERT et son cousin plus grand (appelé BERT-3 dans ce travail) apprennent d’abord des schémas généraux de mots et de phrases. Ensuite, ils sont orientés vers des objectifs spécifiques, tels que classer des sujets d’actualité, juger le ton de messages sur les réseaux sociaux ou traduire de l’anglais vers le français. Les auteurs comparent le « fine-tuning complet », où chaque partie du modèle est ajustée pour la nouvelle tâche, aux approches « basées sur les caractéristiques » qui considèrent le grand modèle comme un extracteur de caractéristiques figé alimentant un modèle plus petit et plus simple. Ils mettent aussi en lumière des stratégies qui modifient la manière dont les données sont présentées au modèle, y compris l’entraînement progressif qui commence par des cas plus faciles pour aller vers des cas plus difficiles.
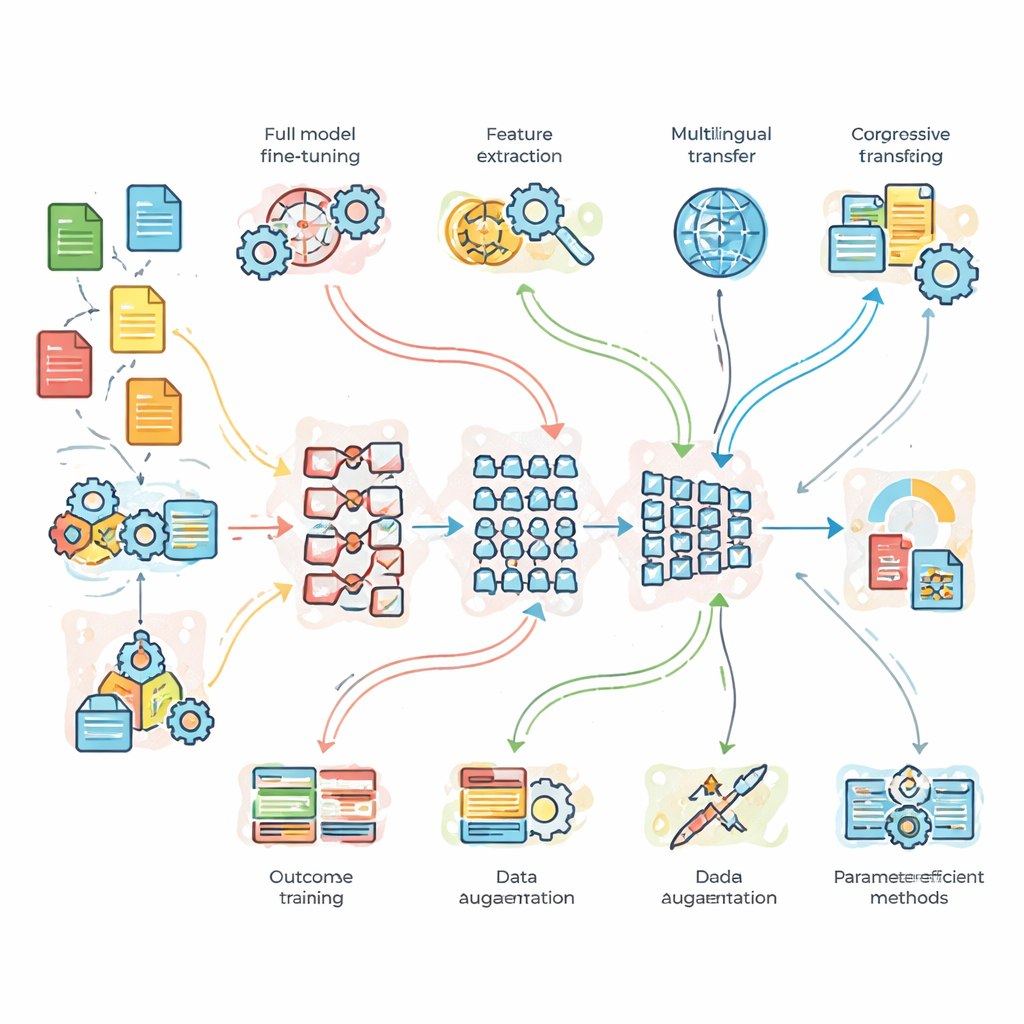
Ce que les chercheurs ont testé en pratique
Pour aller au-delà de la théorie, l’équipe a mené des expériences contrôlées sur trois problèmes de référence. D’abord, une tâche de classification de sujets d’actualité avec beaucoup de données propres ; ensuite, une analyse de sentiment sur des tweets bruyants, remplis d’argot ; et enfin, une traduction anglais–français. Ils ont comparé un réseau de base léger construit sur mesure, BERT standard et un modèle plus profond, BERT-3. Sur ces modèles, ils ont testé sept stratégies d’adaptation : fine-tuning complet, transfert basé sur les caractéristiques, entraînement progressif et adaptation au domaine, fine-tuning multilingue, augmentation de données (par exemple par paraphrase), et deux méthodes modernes « économes en paramètres » qui n’ajustent qu’une petite fraction des réglages internes du modèle. Cette configuration leur a permis de s’interroger non seulement sur le modèle le plus performant, mais aussi sur les circonstances où une complexité ou des données supplémentaires valent vraiment le coût.
Quels modèles et quelles stratégies dominent
Les résultats montrent un schéma clair : le modèle plus grand BERT-3 surpasse systématiquement à la fois BERT standard et le modèle de base léger sur les tâches les plus exigeantes, en particulier l’analyse de sentiment et la traduction. Toutefois, le modèle simple reste étonnamment compétitif pour la classification d’actualité plus triviale, soulignant que la taille n’est pas toujours nécessaire. Côté stratégie d’entraînement, le fine-tuning progressif et l’adaptation au domaine offrent les meilleurs scores globaux, surtout sur des exemples plus difficiles où la formulation est plus longue ou plus complexe. L’augmentation de données aide aussi, agissant comme l’ajout de données d’entraînement supplémentaires en reformulant des phrases existantes. Fait important, deux approches économes en paramètres — les couches d’adaptateurs et une méthode appelée LoRA — approchent très près des meilleures performances tout en ne mettant à jour que moins de cinq pour cent des paramètres du modèle, réduisant fortement la mémoire et les besoins de calcul.
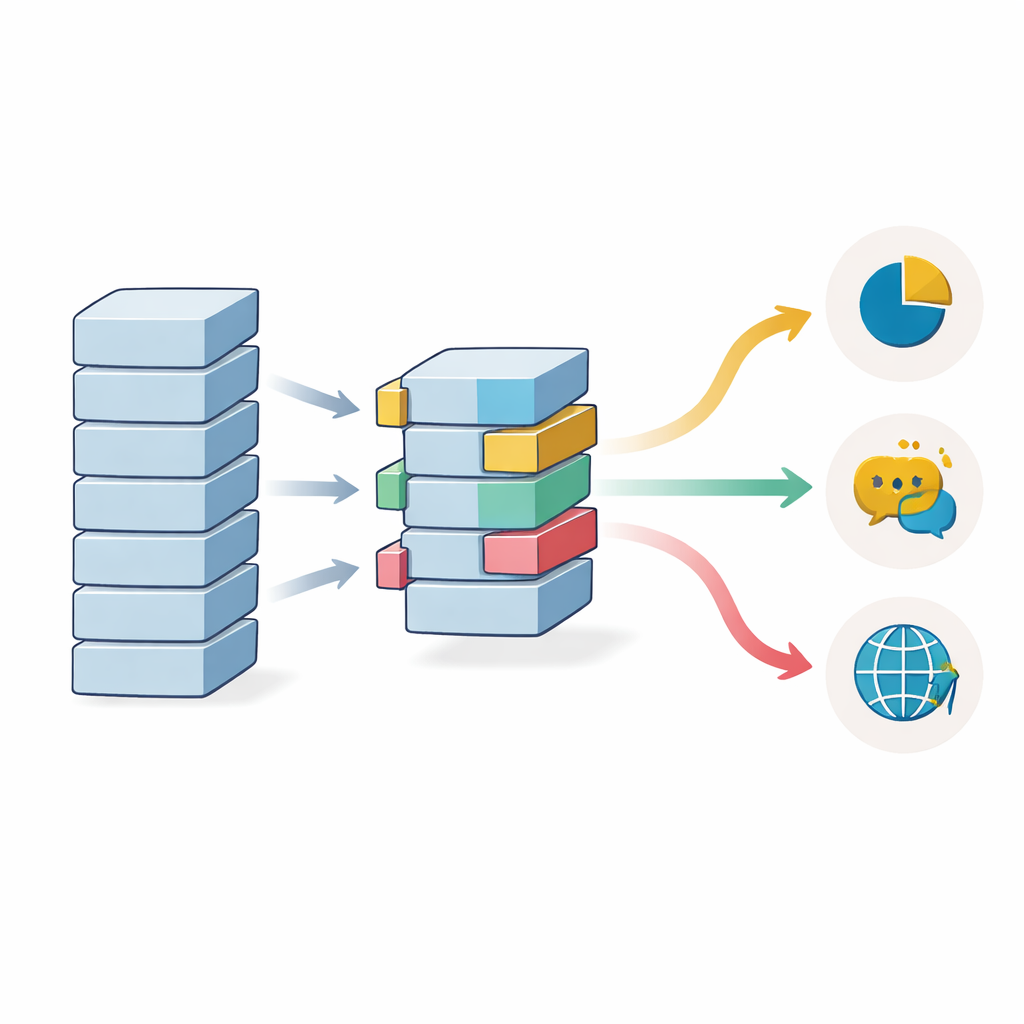
Pourquoi la quantité de données et la diversité linguistique comptent toujours
L’étude examine également la quantité d’exemples étiquetés nécessaire quand on utilise le transfert d’apprentissage. La précision augmente régulièrement à mesure que le nombre d’exemples d’entraînement croît, mais grâce au départ depuis un modèle pré-entraîné, même des expériences avec seulement 1 000 exemples atteignent des performances qui exigeraient normalement bien plus de données. Les gains commencent à se stabiliser autour de 20 000 échantillons sur les benchmarks les plus propres, bien que des jeux de données plus complexes et bruités puissent encore bénéficier d’ensembles d’entraînement plus importants. Les modèles multilingues, entraînés sur plusieurs langues à la fois, aident lorsque les données étiquetées sont rares pour une langue particulière, mais ils peuvent légèrement être en retrait par rapport aux modèles monolingues lorsque de nombreux exemples en anglais sont disponibles, indiquant un compromis entre couverture large et spécialisation fine.
Ce que cela implique pour les technologies linguistiques à venir
Pour les lecteurs hors du domaine, la conclusion principale est qu’il n’existe pas de « recette » unique pour adapter les grands modèles de langage. Les modèles plus volumineux comme BERT-3 excellent sur les tâches difficiles de compréhension et de traduction, tandis que des réseaux plus petits peuvent être parfaitement suffisants pour des tâches plus simples. Les méthodes qui introduisent les tâches progressivement ou qui augmentent l’ensemble d’entraînement avec des exemples paraphrasés rendent généralement les systèmes plus robustes, surtout quand les données sont limitées. Peut-être plus important encore, les techniques récentes qui n’ajustent que de petits composants additionnels offrent une précision proche du niveau supérieur pour une fraction du coût. Ensemble, ces résultats dessinent un avenir où des outils linguistiques puissants peuvent être adaptés plus précisément aux besoins et aux ressources d’entreprises, de langues et d’applications différents, rendant le TAL avancé plus accessible et plus efficace.
Citation: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Mots-clés: transfer learning, traitement du langage naturel, stratégies de fine-tuning, grands modèles de langage, méthodes économes en paramètres