Clear Sky Science · ru
Выявление продвинутых стратегий трансферного обучения для глубоких нейронных сетей в обработке естественного языка
Почему умные языковые инструменты важны
От фильтров электронной почты до чат-ботов и приложений для перевода — многие современные цифровые инструменты зависят от систем, которые умеют читать и писать на человеческом языке. Обучать такие системы с нуля дорого и требует больших объёмов данных, поэтому исследователи нередко берут за основу уже обученные крупные языковые модели и адаптируют их под новые задачи — практику, называемую трансферным обучением. В этой статье систематически рассматривается, как разные подходы к адаптации сравниваются между собой: семь стратегий исследуются на нескольких типах языковых задач, чтобы выяснить, какие дают наилучшее сочетание точности, скорости и практичности в реальных условиях.
Как машины повторно используют уже усвоенное
Исследование начинается с объяснения того, как современные языковые системы учатся на огромных корпусах текстов, а затем повторно используют эти знания для новых задач. Такие известные модели, как BERT и его более крупный «собрат» (в этой работе обозначенный как BERT-3), сначала усваивают общие закономерности слов и предложений. Позже их смещают в сторону конкретных целей — например, классификации новостных тем, оценки тона постов в соцсетях или перевода с английского на французский. Авторы противопоставляют «полную донастройку», когда под новую задачу настраивается вся модель, «фичер-ориентированным» подходам, где большая модель замораживается и выступает как извлекатель признаков для более простой модели. Также обсуждаются стратегии, меняющие подачу данных модели, включая прогрессивное обучение, которое начинается с более простых примеров и переходит к более сложным.
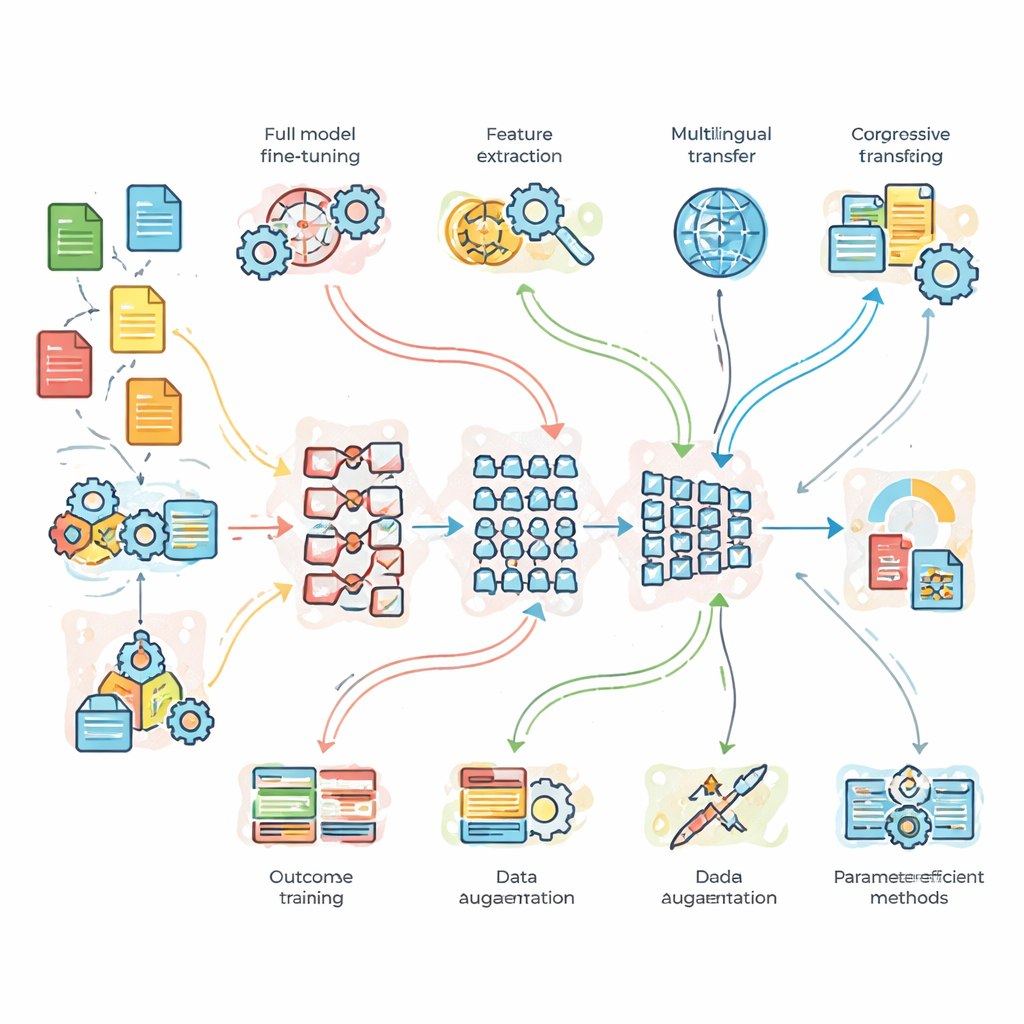
Что исследователи тестировали на практике
Чтобы выйти за рамки теории, команда провела контролируемые эксперименты на трёх эталонных задачах. Во‑первых, классификация новостных тем с большим объёмом чистых данных; во‑вторых, анализ настроений в шумных твитах, заполненных сленгом; и в‑третьих, перевод с английского на французский. Они сравнили лёгкую пользовательскую базовую сеть, стандартный BERT и более глубокую модель BERT-3. Поверх них применили семь стратегий адаптации: полную донастройку, перенос на основе признаков, прогрессивное и доменно-адаптивное обучение, мультилингвальную донастройку, увеличение данных (например, перефразированием предложений) и два современных «параметроэффективных» метода, корректирующих лишь небольшую часть внутренних параметров модели. Такая конфигурация позволила оценить не только, какая модель сильнее, но и когда дополнительная сложность или данные действительно оправданы.
Какие модели и стратегии оказались в выигрыше
Результаты показывают чёткую закономерность: более крупная модель BERT-3 последовательно превосходит стандартный BERT и лёгкую базовую модель в более требовательных задачах, особенно в анализе настроений и переводе. Тем не менее простая модель остаётся удивительно конкурентоспособной в задаче прямой классификации новостей, что подчёркивает: больше не всегда означает необходимость. Среди стратегий обучения прогрессивная и доменно-адаптивная донастройка дают наилучшие суммарные результаты, особенно на более сложных примерах с длинной или сложной формулировкой. Увеличение данных тоже помогает, фактически действуя как дополнительный тренировочный материал через перефразирование имеющихся предложений. Важно, что два параметроэффективных подхода — слои-адаптеры и метод, называемый LoRA — показывают почти сопоставимую с лучшими точность, обновляя при этом менее пяти процентов параметров модели и сильно снижая требования к памяти и вычислениям.
Почему объём данных и языковое разнообразие всё ещё важны
Исследование также изучает, сколько размеченных данных требуется при применении трансферного обучения. Точность стабильно растёт с увеличением числа обучающих примеров, но благодаря старту с предобученной модели даже прогон с лишь 1 000 примеров достигает уровня, который обычно потребовал бы гораздо больше данных. Приросты начинают выравниваться примерно около 20 000 примеров на более чистых наборах, хотя более сложные и шумные датасеты всё ещё выигрывают от больших обучающих выборок. Мультилингвальные модели, обученные сразу на многих языках, помогают, когда размеченных данных на конкретном языке мало, но они могут немного уступать одноязычным моделям при наличии большого числа примеров на английском, что указывает на компромисс между широтой покрытия и детальной специализацией.
Что это значит для будущих языковых технологий
Для читателей вне области главный вывод таков: универсального «лучшего» рецепта для адаптации крупных языковых моделей не существует. Более крупные модели, такие как BERT-3, показывают себя на сложных задачах понимания и перевода, тогда как меньшие сети могут быть полностью адекватны для простых задач. Методы, которые вводят задачи постепенно или расширяют обучающий набор перефразированными примерами, в целом делают системы более устойчивыми, особенно при ограниченных данных. Возможно, самое важное — новые техники, корректирующие лишь небольшие добавочные компоненты, обеспечивают почти топовую точность при гораздо меньших затратах. В совокупности эти результаты указывают на будущее, в котором мощные языковые инструменты можно точнее подгонять под потребности и ресурсы разных компаний, языков и приложений, делая передовые методы НЛП более доступными и эффективными.
Цитирование: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Ключевые слова: трансферное обучение, обработка естественного языка, стратегии донастройки, крупные языковые модели, параметроэффективные методы