Clear Sky Science · de
Aufdeckung fortgeschrittener Transfer-Learning-Strategien für tiefe neuronale Netze in der Verarbeitung natürlicher Sprache
Warum klügere Sprachwerkzeuge wichtig sind
Von E-Mail-Filtern über Chatbots bis zu Übersetzungs-Apps stützen sich viele der heutigen digitalen Werkzeuge auf Computer, die menschliche Sprache lesen und erzeugen können. Diese Systeme von Grund auf neu zu trainieren ist kostspielig und datenintensiv, deshalb beginnen Forschende oft mit großen, bereits vortrainierten Sprachmodellen und passen diese an neue Aufgaben an — eine Praxis, die als Transfer-Learning bezeichnet wird. Dieser Beitrag untersucht systematisch, wie verschiedene Anpassungsweisen im Vergleich abschneiden, und vergleicht sieben Strategien über mehrere Aufgabentypen hinweg, um herauszufinden, welche Kombination aus Genauigkeit, Geschwindigkeit und Praxistauglichkeit in realen Szenarien am besten funktioniert.
Wie Maschinen Vorwissen wiederverwenden
Die Studie beginnt mit einer Erklärung, wie moderne Sprachsysteme aus riesigen Textsammlungen lernen und dieses Wissen dann für neue Aufgaben wiederverwenden. Bekannte Modelle wie BERT und sein größeres Pendant (in dieser Arbeit BERT-3 genannt) lernen zunächst allgemeine Muster von Wörtern und Sätzen. Anschließend werden sie auf spezifische Ziele ausgerichtet, etwa die Klassifikation von Nachrichtenthemen, die Bewertung des Tons von Social-Media-Beiträgen oder die Übersetzung zwischen Englisch und Französisch. Die Autoren stellen "vollständiges Fine-Tuning", bei dem jeder Teil des Modells für die neue Aufgabe angepasst wird, dem "feature-basierten" Ansatz gegenüber, bei dem das große Modell als eingefrorener Merkmalsextraktor dient, der ein kleineres, einfacheres Modell versorgt. Außerdem heben sie Strategien hervor, die ändern, wie Daten dem Modell präsentiert werden — etwa progressives Training, das mit einfacheren Fällen beginnt und zu schwierigeren übergeht.
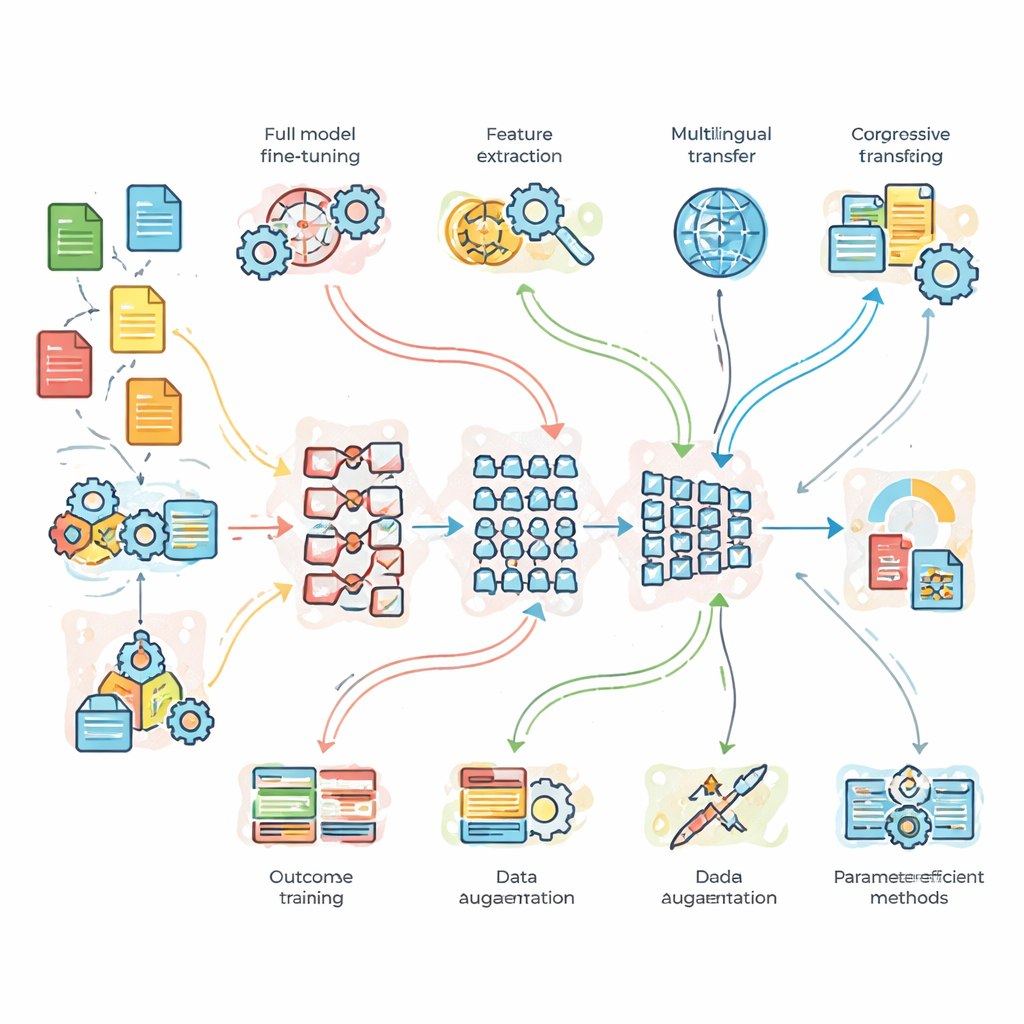
Was die Forschenden praktisch getestet haben
Um über die Theorie hinauszukommen, führten die Forschenden kontrollierte Experimente zu drei Benchmark-Problemen durch. Erstens eine Nachrichtenthemen-Klassifikation mit reichlich sauberen Daten; zweitens Sentiment-Analyse auf lauten, mit Slang durchsetzten Tweets; und drittens eine Englisch-auf-Französisch-Übersetzung. Sie verglichen ein leichtes, maßgeschneidertes Basisnetzwerk, das standardmäßige BERT und ein tieferes BERT-3-Modell. Auf diese Modelle wendeten sie sieben Anpassungsstrategien an: vollständiges Fine-Tuning, feature-basierte Übertragung, progressives und domänenadaptives Training, multilingualen Fine-Tuning, Datenaugmentation (zum Beispiel durch Paraphrasieren von Sätzen) und zwei moderne "parameter-effiziente" Methoden, die nur einen kleinen Bruchteil der internen Modellparameter verändern. Dieses Setup erlaubte ihnen zu fragen, nicht nur welches Modell am stärksten ist, sondern auch wann zusätzliche Komplexität oder mehr Daten wirklich lohnen.
Welche Modelle und Strategien sich durchsetzen
Die Ergebnisse zeigen ein klares Muster: Das größere BERT-3-Modell übertrifft durchgehend sowohl das Standard-BERT als auch das leichte Basismodell bei den anspruchsvolleren Aufgaben, insbesondere bei Sentiment-Analyse und Übersetzung. Das einfache Modell bleibt jedoch bei der unkomplizierten Nachrichtenklassifikation überraschend konkurrenzfähig, was zeigt, dass größer nicht immer nötig ist. Hinsichtlich der Trainingsstrategie liefern progressives und domänenadaptives Fine-Tuning die besten Gesamtergebnisse, besonders bei schwierigeren Beispielen mit längerer oder komplexerer Formulierung. Datenaugmentation hilft ebenfalls und wirkt ähnlich wie zusätzliches Trainingsmaterial durch Umformulierung vorhandener Sätze. Entscheidend ist, dass zwei parameter-effiziente Ansätze — Adapter-Schichten und eine Methode namens LoRA — sehr nahe an die beste Leistung herankommen, während sie weniger als fünf Prozent der Modellparameter aktualisieren und dadurch Speicher- und Rechenbedarf stark reduzieren.
Warum Datenmenge und Sprachvielfalt weiterhin wichtig sind
Die Studie untersucht auch, wie viele gelabelte Daten beim Einsatz von Transfer-Learning erforderlich sind. Die Genauigkeit steigt stetig mit zunehmender Stichprobengröße, aber da auf einem vortrainierten Modell aufgebaut wird, erzielen selbst Durchläufe mit nur etwa 1.000 Beispielen Leistungen, für die sonst deutlich mehr Daten nötig wären. Die Zugewinne flachen bei den saubereren Benchmarks um etwa 20.000 Beispiele ab, während komplexere, lautere Datensätze weiterhin von größeren Trainingsmengen profitieren können. Multilinguale Modelle, die auf vielen Sprachen zugleich trainiert werden, helfen, wenn in einer bestimmten Sprache nur wenige gelabelte Daten vorliegen, können jedoch leicht hinter einsprachigen Modellen zurückbleiben, wenn viele englische Beispiele verfügbar sind — was einen Kompromiss zwischen breiter Abdeckung und feiner Spezialisierung zeigt.
Was das für zukünftige Sprachtechnologien bedeutet
Für Leser außerhalb des Fachgebiets lautet die wichtigste Erkenntnis, dass es kein einzelnes "bestes" Rezept zur Anpassung großer Sprachmodelle gibt. Größere Modelle wie BERT-3 glänzen bei anspruchsvollen Verständnis- und Übersetzungsaufgaben, während kleinere Netze für einfachere Aufgaben völlig ausreichen können. Methoden, die Aufgaben schrittweise einführen oder den Trainingssatz mit paraphrasierten Beispielen erweitern, machen Systeme im Allgemeinen robuster, insbesondere wenn Daten knapp sind. Vielleicht am wichtigsten: Neuere Techniken, die nur kleine Zusatzkomponenten anpassen, erreichen nahezu Spitzenleistungen zu einem Bruchteil der Kosten. Zusammengenommen deuten diese Befunde auf eine Zukunft hin, in der leistungsfähige Sprachwerkzeuge genauer an die Bedürfnisse und Ressourcen verschiedener Unternehmen, Sprachen und Anwendungen angepasst werden können — und damit fortgeschrittene NLP zugänglicher und effizienter werden.
Zitation: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Schlüsselwörter: Transfer-Learning, Verarbeitung natürlicher Sprache, Fine-Tuning-Strategien, große Sprachmodelle, parameter-effiziente Methoden