Clear Sky Science · tr
Doğal dil işleme için derin sinir ağlarında gelişmiş aktarım öğrenmesi stratejilerinin ortaya çıkarılması
Daha akıllı dil araçlarının önemi
E-posta filtrelerinden sohbet botlarına ve çeviri uygulamalarına kadar, günümüz dijital araçlarının birçoğu insan dilini okuyup yazabilen bilgisayarlara dayanır. Bu sistemleri sıfırdan eğitmek maliyetli ve veri talep eder; bu yüzden araştırmacılar genellikle büyük, önceden eğitilmiş dil modellerinden başlayıp bunları yeni görevlere uyarlamayı tercih eder — buna aktarım öğrenmesi denir. Bu makale, bu uyarlama yöntemlerinin nasıl işlediğini sistematik biçimde inceliyor ve yedi farklı stratejiyi çeşitli dil görevleri üzerinde karşılaştırarak hangilerinin doğruluk, hız ve pratiklik açısından gerçek dünya koşullarında en iyi dengeyi sunduğunu araştırıyor.
Makineler bildiklerini nasıl yeniden kullanıyor
Çalışma, modern dil sistemlerinin devasa metin koleksiyonlarından nasıl öğrendiğini ve ardından bu bilgiyi yeni görevlere nasıl aktardığını anlatarak başlıyor. BERT gibi iyi bilinen modeller ve bu çalışmada BERT-3 olarak adlandırılan daha büyük akrabası, ilk aşamada kelime ve cümlelerin genel kalıplarını öğrenir. Daha sonra haber konusu sınıflandırma, sosyal medya gönderilerinin tonunu değerlendirme veya İngilizce–Fransızca çeviri gibi belirli hedeflere doğru yönlendirilirler. Yazarlar, modelin her parçasının yeni görev için ayarlandığı “tam ince ayar”ı, büyük modeli donmuş bir özellik çıkartıcı olarak kullanıp daha küçük bir modele besleyen “özellik tabanlı” yaklaşımlarla karşılaştırıyor. Ayrıca verilerin modele sunuluş biçimini değiştiren stratejilere de vurgu yapıyorlar; örneğin kolay vakalarla başlayıp daha zor olanlara geçen ilerlemeli eğitim gibi yaklaşımlar ele alınıyor.
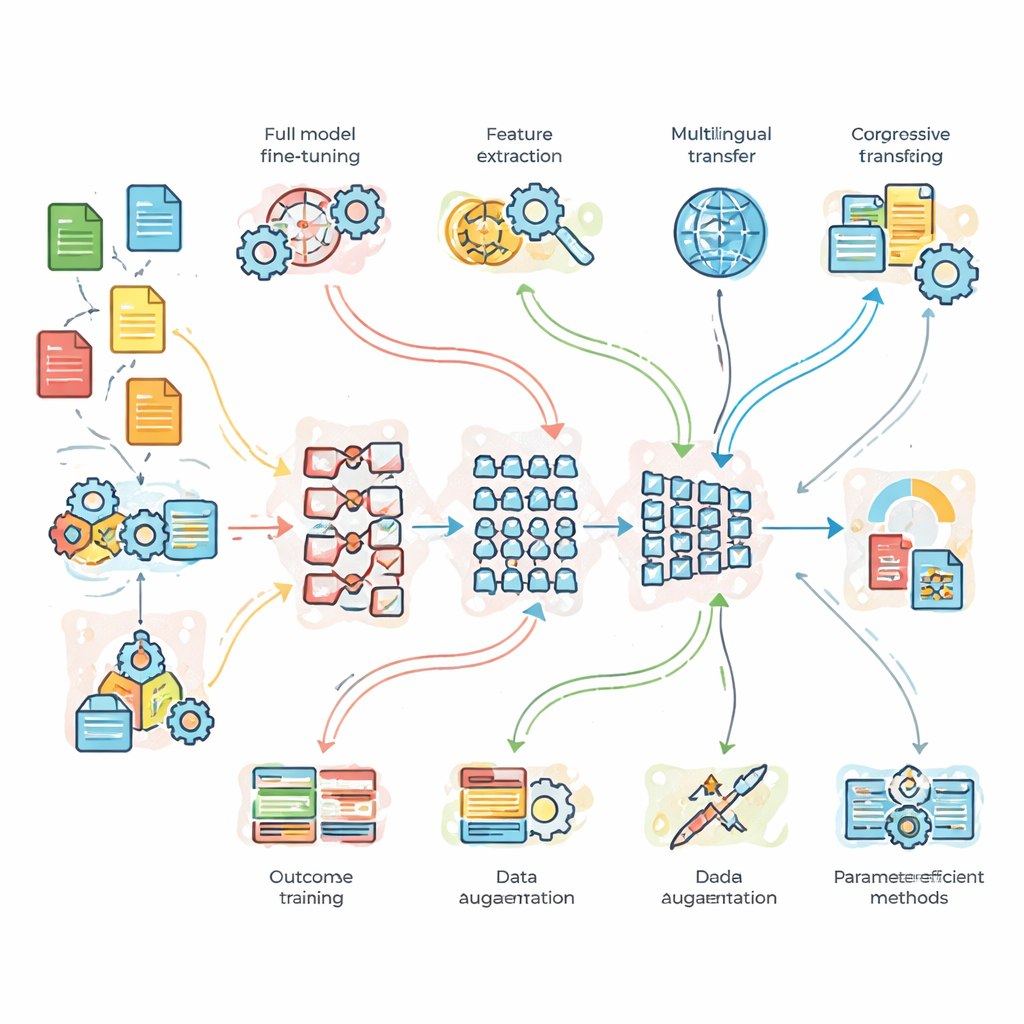
Araştırmacıların pratikte test ettikleri
Teorinin ötesine geçmek için ekip, üç kıyaslama probleminde kontrollü deneyler yürüttü. İlk olarak bol ve temiz veriye sahip bir haber konusu sınıflandırma görevi; ikinci olarak gürültülü, argo dolu tweet’lerde duygu analizi; üçüncü olarak ise İngilizceden Fransızcaya çeviri. Hafif, özel olarak tasarlanmış bir temel ağ, standart BERT ve daha derin bir BERT-3 modeli karşılaştırıldı. Bunların üzerine yedi uyarlama stratejisi uygulandı: tam ince ayar, özellik-tabanlı aktarım, ilerlemeli ve alan-adaptif eğitim, çokdilli ince ayar, veri çoğaltma (örneğin cümleleri eş-anlamlı ifadelerle yeniden yazarak) ve modelin iç ayarlarının yalnızca küçük bir kısmını değiştiren iki modern “parametre-verimli” yöntem. Bu düzen, yalnızca hangi modelin daha güçlü olduğunu değil, ne zaman ek karmaşıklık veya verinin gerçekten fayda sağladığını da sorgulamalarına olanak tanıdı.
Hangi modeller ve stratejiler öne çıkıyor
Sonuçlar belirgin bir desen gösteriyor: daha büyük BERT-3 modeli, özellikle duygu analizi ve çeviri gibi daha zorlayıcı görevlerde, standart BERT ve hafif temele kıyasla tutarlı biçimde daha iyi performans sergiliyor. Bununla birlikte basit model, düz haber sınıflandırmasında şaşırtıcı derecede rekabetçi kalıyor; bu da daha büyük olmanın her zaman gerekli olmadığını vurguluyor. Eğitim stratejisi açısından ilerlemeli ve alan-adaptif ince ayar genel olarak en iyi puanları veriyor; özellikle ifade daha uzun veya daha karmaşık olduğunda daha zor örneklerde öne çıkıyorlar. Veri çoğaltma da yardımcı oluyor; mevcut cümleleri yeniden ifade ederek ek eğitim verisi kazanmış gibi bir etki sağlıyor. Kritik olarak, iki parametre-verimli yaklaşım —adaptor katmanları ve LoRA adlı bir yöntem— modelin parametrelerinin yüzde beşinden daha azını güncelleyerek en iyi performansa çok yakın sonuçlar elde ediyor ve bellek ile hesaplama ihtiyaçlarını önemli ölçüde azaltıyor.
Veri miktarı ve dil çeşitliliğinin neden hâlâ önemli olduğu
Çalışma ayrıca aktarım öğrenmesi kullanıldığında ne kadar etiketli veriye ihtiyaç duyulduğunu da araştırıyor. Doğruluk, eğitim örnekleri arttıkça istikrarlı biçimde yükseliyor, ancak önceden eğitilmiş bir modelden başlanması sayesinde bin örnek kadar az veriyle bile genellikle çok daha fazla veri gerektirecek performanslara ulaşılabiliyor. Temiz kıyaslamalarda kazançlar yaklaşık 20.000 örnekte azalmaya başlasa da daha karmaşık ve gürültülü veri kümeleri hâlâ daha büyük eğitim setlerinden fayda sağlayabiliyor. Birden çok dili aynı anda eğiten çokdilli modeller, belirli bir dilde etiketli veri kıt olduğunda yardımcı oluyor; ancak bol miktarda İngilizce örnek mevcut olduğunda tek dilli modellerin biraz gerisinde kalabiliyorlar; bu da geniş kapsama ile ince ayrıntılı özelleşme arasında bir takas olduğunu gösteriyor.
Gelecek dil teknolojileri için çıkarımlar
Alanın dışındaki okuyucular için ana çıkarım, büyük dil modellerini uyarlamak için tek bir “en iyi” reçetenin olmadığıdır. BERT-3 gibi daha büyük modeller, zorlu anlama ve çeviri görevlerinde parlıyor; daha küçük ağlar ise daha basit işler için gayet uygun olabilir. Görevleri kademeli olarak tanıtmak veya eğitim setini eş-anlamlı örneklerle genişletmek gibi yöntemler genellikle sistemleri daha sağlam kılıyor; özellikle veri sınırlı olduğunda. Belki de en önemlisi, yalnızca küçük eklenti bileşenlerini ayarlayan yeni teknikler neredeyse en üst düzey doğruluğu çok daha düşük maliyetle sunuyor. Bu bulgular, güçlü dil araçlarının farklı şirketlerin, dillerin ve uygulamaların ihtiyaç ve kaynaklarına daha hassas biçimde uyarlanabileceği; gelişmiş NLP’yi daha erişilebilir ve verimli hale getirebilecek bir gelecek öngörüyor.
Atıf: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Anahtar kelimeler: aktarım öğrenmesi, doğal dil işleme, ince ayar stratejileri, büyük dil modelleri, parametre-verimli yöntemler