Clear Sky Science · pt
Descobrindo estratégias avançadas de transfer learning para redes neurais profundas em processamento de linguagem natural
Por que ferramentas de linguagem mais inteligentes importam
De filtros de e-mail a chatbots e aplicativos de tradução, muitas das ferramentas digitais atuais dependem de computadores capazes de ler e escrever linguagem humana. Treinar esses sistemas do zero é caro e exige muitos dados, por isso pesquisadores frequentemente partem de modelos de linguagem grandes já treinados e os adaptam a novas tarefas — uma prática chamada transfer learning. Este artigo faz uma avaliação sistemática de como diferentes maneiras de realizar essa adaptação se comparam, analisando sete estratégias em vários tipos de tarefas de linguagem para descobrir quais oferecem a melhor combinação de precisão, rapidez e praticidade em cenários reais.
Como as máquinas reaproveitam o que já sabem
O estudo começa explicando como sistemas modernos de linguagem aprendem a partir de enormes coleções de texto e depois reutilizam esse conhecimento em novas tarefas. Modelos conhecidos como BERT e seu primo maior (chamado BERT-3 neste trabalho) primeiro aprendem padrões gerais de palavras e sentenças. Depois, são direcionados para objetivos específicos, como classificar tópicos de notícias, avaliar o tom de postagens em redes sociais ou traduzir entre inglês e francês. Os autores contrastam o “fine-tuning completo”, em que todas as partes do modelo são ajustadas para a nova tarefa, com abordagens “baseadas em features” que tratam o grande modelo como um extrator de características congelado alimentando um modelo menor e mais simples. Também destacam estratégias que mudam como os dados são apresentados ao modelo, incluindo treinamento progressivo que começa com casos mais fáceis e avança para os mais difíceis.
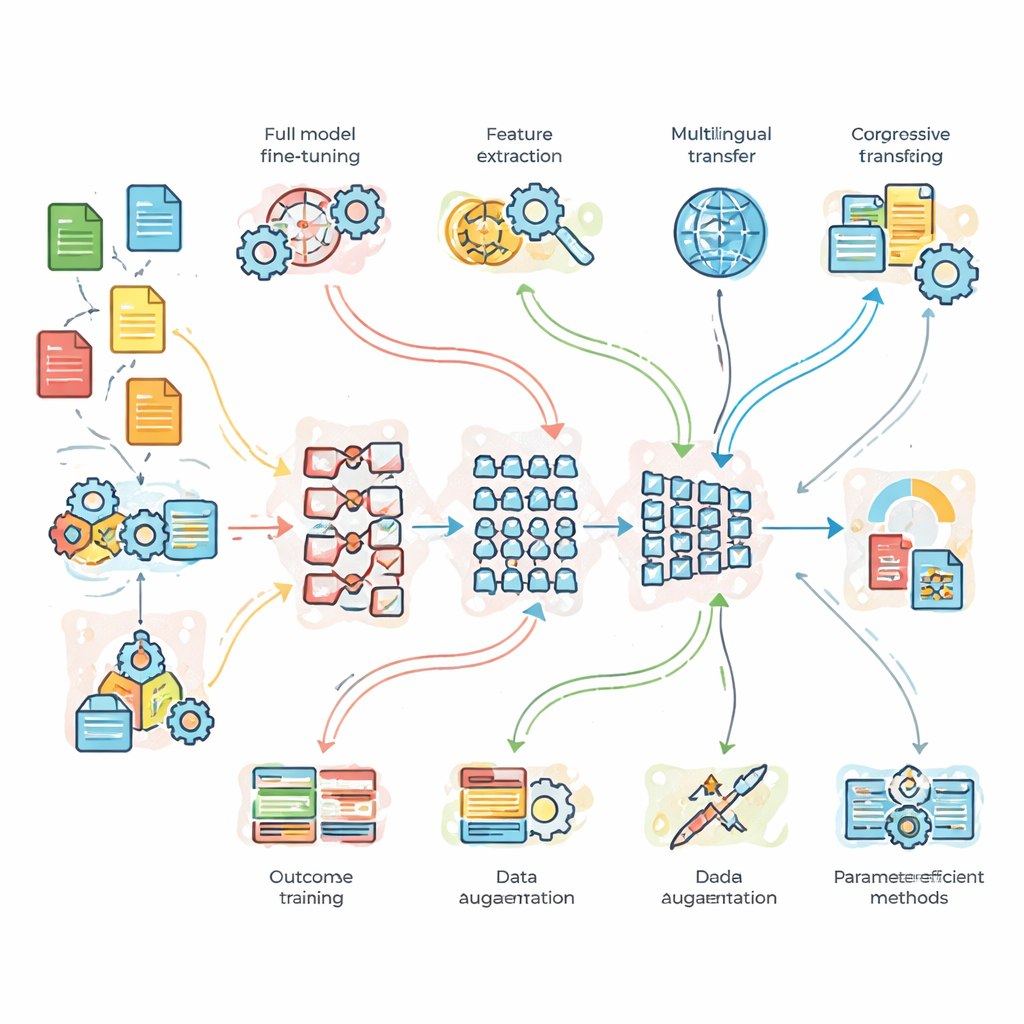
O que os pesquisadores testaram na prática
Para ir além da teoria, a equipe conduziu experimentos controlados em três problemas de referência. Primeiro, uma tarefa de classificação de tópicos de notícias com muitos dados limpos; segundo, análise de sentimento em tweets ruidosos e cheios de gírias; e terceiro, tradução de inglês para francês. Eles compararam uma rede base leve construída sob medida, o BERT padrão e um modelo mais profundo, o BERT-3. Sobre esses modelos, aplicaram sete estratégias de adaptação: fine-tuning completo, transferência baseada em features, treinamento progressivo e adaptativo ao domínio, fine-tuning multilíngue, aumento de dados (por exemplo, por paráfrase de sentenças) e dois métodos modernos “eficientes em parâmetros” que ajustam apenas uma pequena fração dos controles internos do modelo. Essa configuração permitiu avaliar não apenas qual modelo é mais forte, mas também quando complexidade ou dados adicionais realmente compensam.
Quais modelos e estratégias se destacam
Os resultados mostram um padrão claro: o maior modelo BERT-3 supera consistentemente tanto o BERT padrão quanto a base leve nas tarefas mais exigentes, especialmente análise de sentimento e tradução. Contudo, o modelo simples permanece surpreendentemente competitivo na classificação de notícias mais direta, ressaltando que maior nem sempre é necessário. Em termos de estratégia de treinamento, o fine-tuning progressivo e o adaptativo ao domínio apresentam as melhores pontuações gerais, especialmente em exemplos mais difíceis, com enunciados mais longos ou complexos. O aumento de dados também ajuda, funcionando de modo semelhante a ganhar mais exemplos de treinamento ao reescrever sentenças existentes. De forma crucial, duas abordagens eficientes em parâmetros — camadas adapter e um método chamado LoRA — chegam muito perto do melhor desempenho enquanto atualizam menos de cinco por cento dos parâmetros do modelo, reduzindo drasticamente as necessidades de memória e computação.
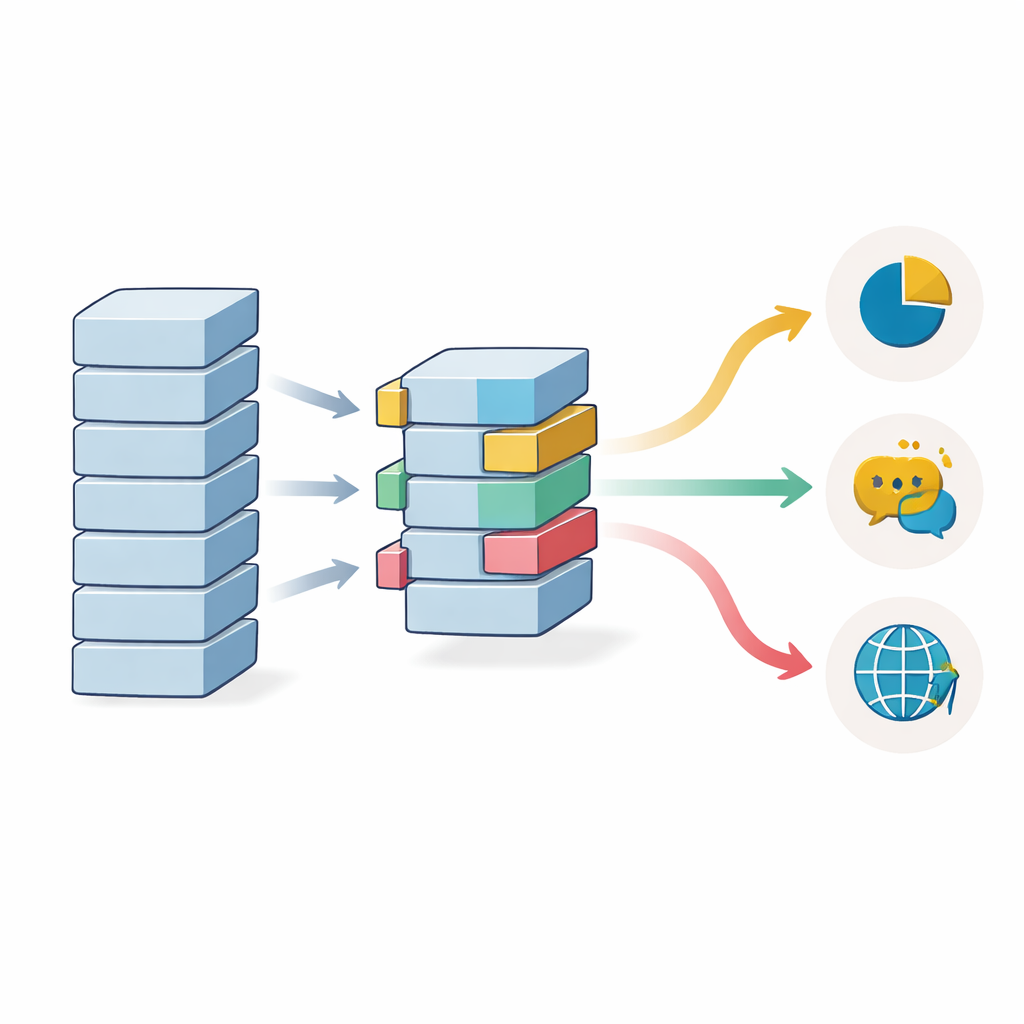
Por que quantidade de dados e diversidade linguística ainda importam
O estudo também investiga quanto de dados rotulados é necessário quando se usa transfer learning. A acurácia aumenta de forma consistente à medida que o número de amostras de treinamento cresce, mas graças a partir do uso de um modelo pré-treinado, mesmo execuções com apenas 1.000 exemplos alcançam desempenho que normalmente exigiria muito mais dados. Os ganhos começam a se estabilizar por volta de 20.000 amostras em benchmarks mais limpos, embora conjuntos de dados mais complexos e ruidosos ainda possam se beneficiar de bases de treinamento maiores. Modelos multilíngues, treinados em várias línguas ao mesmo tempo, ajudam quando há poucos dados rotulados em um idioma específico, mas podem ficar ligeiramente atrás de modelos monolíngues quando há muitos exemplos em inglês disponíveis, indicando um trade-off entre cobertura ampla e especialização mais fina.
O que isso significa para as futuras tecnologias de linguagem
Para leitores fora da área, a principal conclusão é que não existe uma única receita “melhor” para adaptar grandes modelos de linguagem. Modelos maiores como o BERT-3 se destacam em tarefas desafiadoras de compreensão e tradução, enquanto redes menores podem ser perfeitamente adequadas para tarefas mais simples. Métodos que introduzem tarefas gradualmente ou ampliam o conjunto de treinamento com exemplos parafraseados geralmente tornam os sistemas mais robustos, especialmente quando os dados são limitados. Talvez mais importante, técnicas mais recentes que ajustam apenas pequenos componentes adicionais oferecem precisão quase de topo a uma fração do custo. Em conjunto, essas descobertas apontam para um futuro em que ferramentas de linguagem poderosas podem ser ajustadas mais precisamente às necessidades e recursos de diferentes empresas, idiomas e aplicações, tornando o PLN avançado mais acessível e eficiente.
Citação: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Palavras-chave: transfer learning, processamento de linguagem natural, estratégias de fine-tuning, modelos de linguagem grandes, métodos eficientes em parâmetros