Clear Sky Science · es
Descubriendo estrategias avanzadas de transferencia de aprendizaje para redes neuronales profundas en el procesamiento del lenguaje natural
Por qué importan herramientas lingüísticas más inteligentes
Desde filtros de correo hasta chatbots y aplicaciones de traducción, muchas de las herramientas digitales actuales dependen de ordenadores capaces de leer y escribir lenguaje humano. Entrenar estos sistemas desde cero es costoso y exige muchos datos, por lo que los investigadores suelen partir de grandes modelos de lenguaje ya entrenados y adaptarlos a nuevas tareas: una práctica llamada transferencia de aprendizaje. Este artículo examina de forma sistemática cómo se comparan diferentes maneras de realizar esa adaptación, evaluando siete estrategias en varios tipos de tareas lingüísticas para determinar cuáles ofrecen la mejor combinación de precisión, rapidez y viabilidad en escenarios reales.
Cómo las máquinas reutilizan lo que ya saben
El estudio comienza explicando cómo los sistemas de lenguaje actuales aprenden a partir de enormes colecciones de texto y luego reutilizan ese conocimiento en tareas nuevas. Modelos conocidos como BERT y su pariente mayor (denominado BERT-3 en este trabajo) aprenden primero patrones generales de palabras y oraciones. Después se ajustan hacia objetivos concretos, como clasificar temas de noticias, valorar el tono de publicaciones en redes sociales o traducir entre inglés y francés. Los autores contrastan el “ajuste fino completo”, donde se modifica cada parte del modelo para la nueva tarea, con enfoques “basados en características” que tratan el gran modelo como un extractor de características congelado que alimenta a un modelo más pequeño y simple. También resaltan estrategias que cambian cómo se presentan los datos al modelo, incluyendo el entrenamiento progresivo que comienza con casos más sencillos y avanza hacia otros más difíciles.
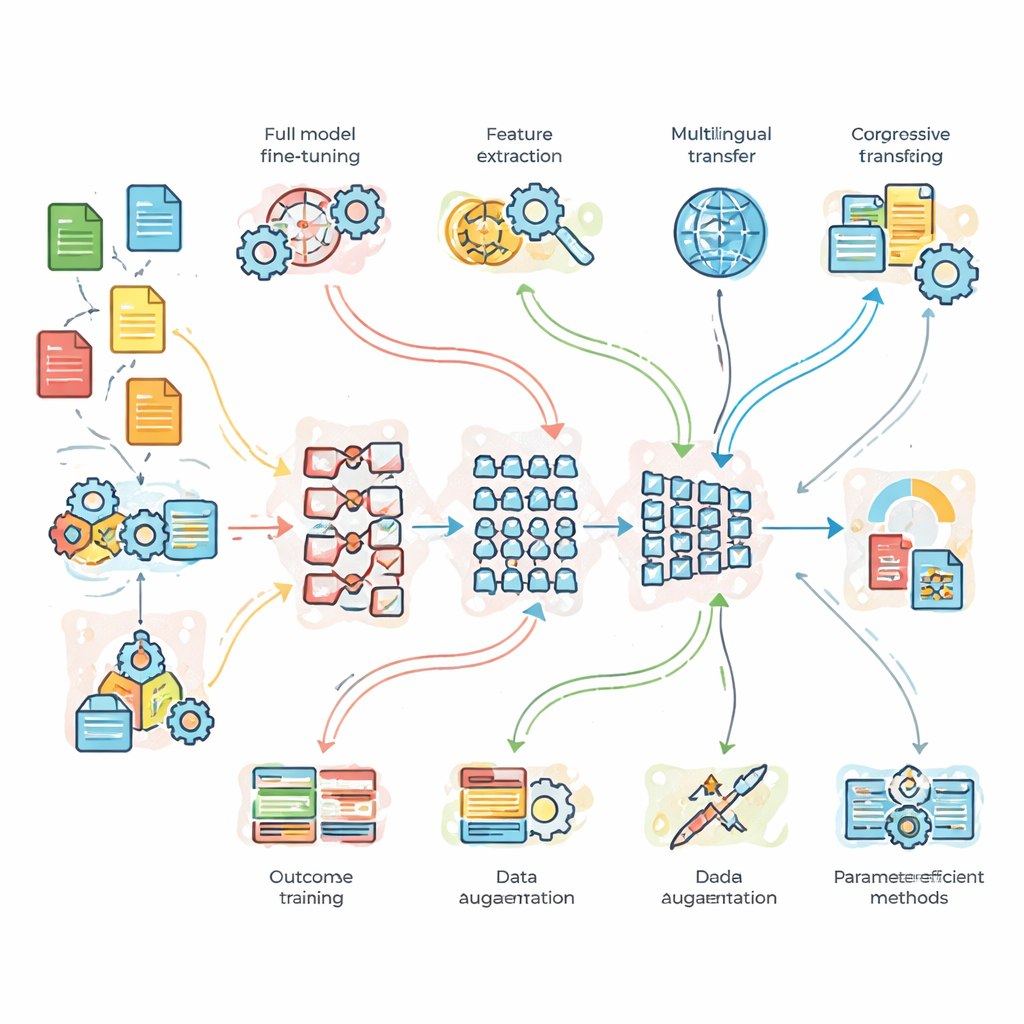
Lo que los investigadores probaron en la práctica
Para ir más allá de la teoría, el equipo llevó a cabo experimentos controlados en tres problemas de referencia. Primero, una tarea de clasificación de temas de noticias con abundantes datos limpios; segundo, análisis de sentimiento en tuits ruidosos y llenos de jerga; y tercero, traducción de inglés a francés. Compararon una red ligera de referencia personalizada, BERT estándar y un modelo más profundo, BERT-3. Sobre estos modelos aplicaron siete estrategias de adaptación: ajuste fino completo, transferencia basada en características, entrenamiento progresivo y adaptativo al dominio, ajuste fino multilingüe, aumento de datos (por ejemplo, mediante parafraseo de oraciones) y dos métodos modernos “eficientes en parámetros” que modifican solo una pequeña fracción de los controles internos del modelo. Esta configuración les permitió preguntar no solo qué modelo es más fuerte, sino cuándo la complejidad o los datos adicionales realmente compensan.
Qué modelos y estrategias resultaron mejores
Los resultados muestran un patrón claro: el modelo más grande, BERT-3, supera de forma consistente tanto a BERT estándar como a la referencia ligera en las tareas más exigentes, especialmente en análisis de sentimiento y traducción. Sin embargo, el modelo simple sigue siendo sorprendentemente competitivo en la clasificación de noticias directa, lo que subraya que lo más grande no siempre es necesario. En cuanto a la estrategia de entrenamiento, el ajuste fino progresivo y adaptado al dominio ofrece las mejores puntuaciones generales, especialmente en ejemplos más difíciles donde las formulaciones son más largas o complejas. El aumento de datos también ayuda, actuando de forma similar a disponer de más datos de entrenamiento al reformular oraciones existentes. De manera crucial, dos enfoques eficientes en parámetros —capas adaptadoras y un método llamado LoRA— se acercan mucho al mejor rendimiento mientras actualizan menos del cinco por ciento de los parámetros del modelo, reduciendo de forma notable las necesidades de memoria y computación.
Por qué la cantidad de datos y la diversidad lingüística siguen importando
El estudio también explora cuántos datos etiquetados son necesarios cuando se utiliza transferencia de aprendizaje. La precisión aumenta de forma constante conforme crecen las muestras de entrenamiento, pero gracias a partir de un modelo preentrenado, incluso ejecuciones con tan solo 1.000 ejemplos alcanzan un rendimiento que normalmente requeriría muchos más datos. Las ganancias empiezan a estabilizarse alrededor de 20.000 muestras en los benchmarks más limpios, aunque conjuntos de datos más complejos y ruidosos aún pueden beneficiarse de tamaños de entrenamiento mayores. Los modelos multilingües, entrenados en varios idiomas a la vez, ayudan cuando los datos etiquetados escasean en un idioma concreto, pero pueden quedarse ligeramente atrás respecto a modelos monolingües cuando hay muchos ejemplos en inglés disponibles, lo que indica un compromiso entre cobertura amplia y especialización detallada.
Qué implica esto para las futuras tecnologías del lenguaje
Para lectores ajenos al campo, la conclusión principal es que no existe una única “mejor” receta para adaptar grandes modelos de lenguaje. Modelos mayores como BERT-3 destacan en tareas exigentes de comprensión y traducción, mientras que redes más pequeñas pueden ser perfectamente adecuadas para trabajos más sencillos. Métodos que introducen las tareas de forma gradual o amplían el conjunto de entrenamiento con ejemplos parafraseados tienden a hacer los sistemas más robustos, especialmente cuando los datos son limitados. Y quizás lo más importante, las técnicas más recientes que solo ajustan pequeños componentes añadidos ofrecen una precisión casi de primer nivel a una fracción del coste. En conjunto, estos hallazgos sugieren un futuro en el que herramientas lingüísticas potentes puedan adaptarse de forma más precisa a las necesidades y recursos de distintas empresas, idiomas y aplicaciones, haciendo el PLN avanzado más accesible y eficiente.
Cita: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Palabras clave: transferencia de aprendizaje, procesamiento del lenguaje natural, estrategias de ajuste fino, modelos de lenguaje grandes, métodos de eficiencia de parámetros