Clear Sky Science · sv
Upptäcka avancerade strategier för transferinlärning för djupa neurala nätverk inom naturlig språkbehandling
Varför smartare språkinstrument är viktiga
Från e-postfilter till chattbotar och översättningsappar förlitar sig många av dagens digitala verktyg på datorer som kan läsa och skriva mänskligt språk. Att träna dessa system från grunden är kostsamt och kräver stora datamängder, så forskare börjar ofta från stora, redan tränade språkmodeller och anpassar dem till nya uppgifter — en praxis som kallas transferinlärning. Denna artikel ger en systematisk genomgång av hur olika sätt att göra denna anpassning står sig, genom att jämföra sju strategier över flera typer av språkuppgifter för att ta reda på vilka som ger den bästa kombinationen av noggrannhet, hastighet och praktisk användbarhet i verkliga miljöer.
Hur maskiner återanvänder det de redan kan
Studien inleds med att förklara hur moderna språksystem lär sig från enorma textkorpusar och sedan återanvänder denna kunskap i nya uppgifter. Välkända modeller som BERT och dess större kusin (kallad BERT-3 i detta arbete) lär sig först allmänna mönster i ord och meningar. Därefter riktas de mot specifika mål såsom att klassificera nyhetsämnen, bedöma tonen i inlägg på sociala medier eller översätta mellan engelska och franska. Författarna kontrasterar ”full finjustering”, där varje del av modellen justeras för den nya uppgiften, med ”funktionsbaserade” tillvägagångssätt som behandlar den stora modellen som en frusen funktionsextraktor som matar en mindre, enklare modell. De lyfter också fram strategier som ändrar hur data presenteras för modellen, inklusive progressiv träning som börjar med enklare fall och går vidare till svårare.
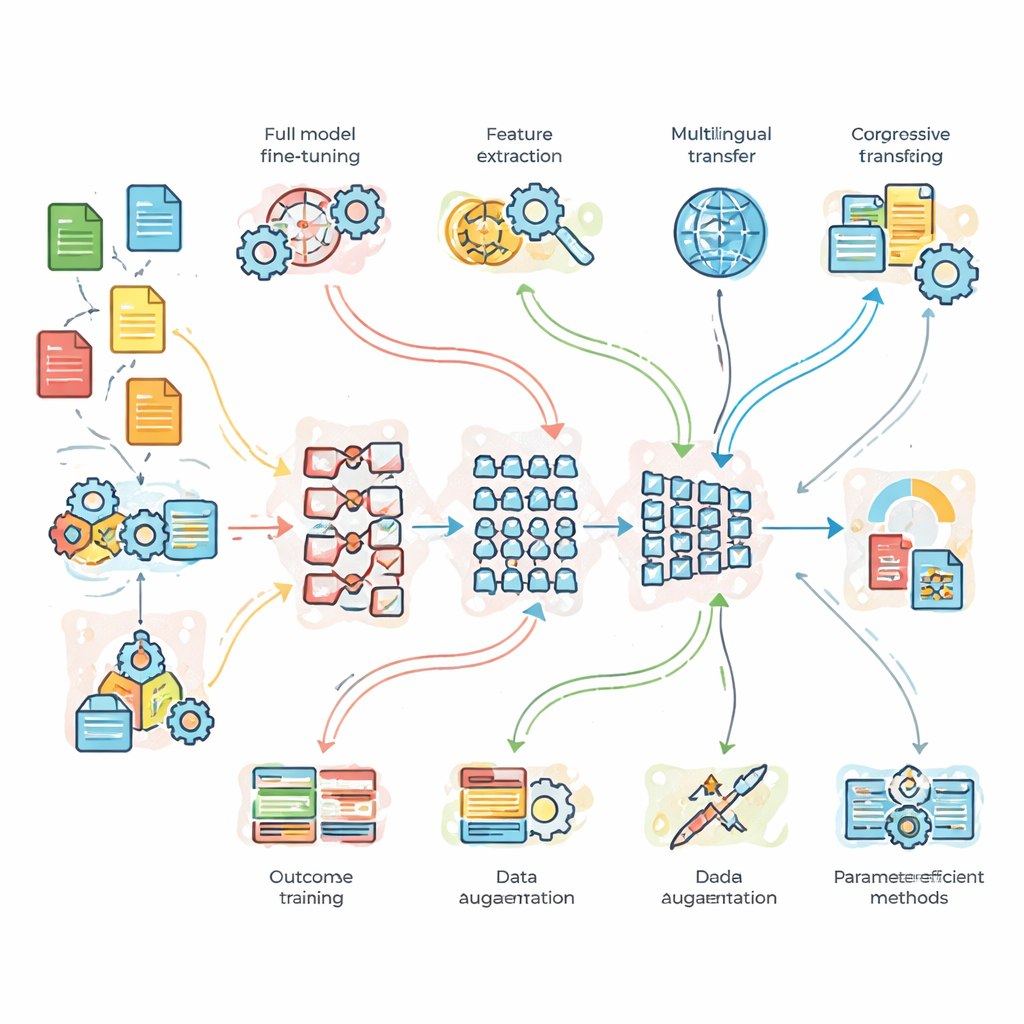
Vad forskarna testade i praktiken
För att gå bortom teori genomförde teamet kontrollerade experiment på tre standarduppgifter. Först en nyhetsämnesklassificering med gott om ren data; för det andra sentimentsanalys på brusiga tweets fyllda med slang; och för det tredje engelska–franska översättningar. De jämförde ett lätt, egenbyggt basnätverk, standard-BERT och en djupare BERT-3-modell. Ovanpå dessa la de sju anpassningsstrategier: full finjustering, funktionsbaserad transfer, progressiv och domänanpassad träning, flerspråkig finjustering, dataaugmentation (till exempel genom parafrasering av meningar) samt två moderna ”parametereffektiva” metoder som bara finjusterar en liten andel av modellens interna reglage. Denna uppställning gjorde det möjligt att fråga inte bara vilken modell som är starkast, utan när extra komplexitet eller mer data verkligen ger utdelning.
Vilka modeller och strategier som kommer i topp
Resultaten visar ett tydligt mönster: den större BERT-3-modellen presterar konsekvent bättre än både standard-BERT och den lätta baslinjen på de mer krävande uppgifterna, särskilt sentimentsanalys och översättning. Den enkla modellen förblir dock förvånansvärt konkurrenskraftig på den raka nyhetsklassificeringen, vilket understryker att större inte alltid är nödvändigt. När det gäller träningsstrategi levererar progressiv och domänanpassad finjustering de bästa övergripande resultaten, särskilt på svårare exempel där formuleringarna är längre eller mer komplexa. Dataaugmentation hjälper också genom att fungera som att få extra träningsdata genom att omformulera befintliga meningar. Avgörande är att två parametereffektiva tillvägagångssätt — adapterlager och en metod kallad LoRA — kommer mycket nära topprestanda samtidigt som de uppdaterar mindre än fem procent av modellens parametrar, vilket kraftigt minskar minnes- och beräkningsbehov.
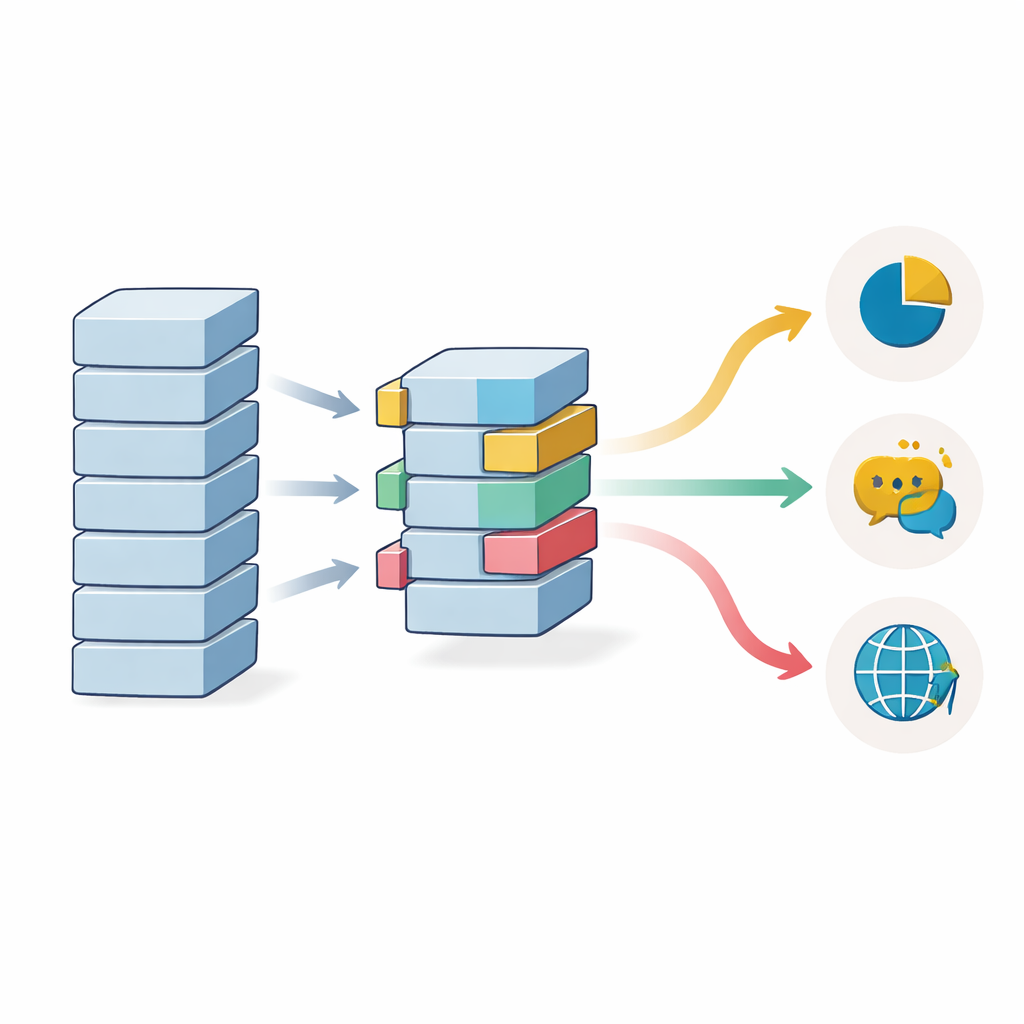
Varför datamängd och språkmångfald fortfarande spelar roll
Studien undersöker också hur mycket etiketterad data som behövs när transferinlärning används. Noggrannheten ökar stadigt i takt med att antalet träningsprov växer, men tack vare att man startar från en förtränad modell når även körningar med så få som 1 000 exempel en prestanda som normalt skulle kräva betydligt mer data. Vinsterna börjar planas ut kring 20 000 prover på de renare benchmarks, även om mer komplexa, brusigare datamängder fortfarande kan gynnas av större träningsset. Flerspråkiga modeller, som tränas på många språk samtidigt, hjälper när etiketterade data är bristfälliga i ett särskilt språk, men de kan halka något efter enspåkiga modeller när det finns gott om engelska exempel tillgängliga, vilket indikerar en avvägning mellan bred täckning och finare specialisering.
Vad detta betyder för framtida språkteknologier
För läsare utanför fältet är huvudslutsatsen att det inte finns ett enda ”bästa” recept för att anpassa stora språkmodeller. Större modeller som BERT-3 utmärker sig vid utmanande förståelse- och översättningsuppgifter, medan mindre nätverk kan vara fullt tillräckliga för enklare uppgifter. Metoder som introducerar uppgifter gradvis eller utökar träningssetet med parafraserade exempel gör system generellt mer robusta, särskilt när data är begränsade. Kanske viktigast är att nyare tekniker som endast justerar små tilläggskomponenter erbjuder nästan topprestanda till en bråkdel av kostnaden. Tillsammans pekar dessa fynd mot en framtid där kraftfulla språkinstrument kan skräddarsys mer precist efter olika företag, språk och applikationers behov och resurser, vilket gör avancerad NLP mer tillgänglig och effektiv.
Citering: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Nyckelord: transferinlärning, naturlig språkbehandling, finjusteringsstrategier, stora språkmodeller, parametereffektiva metoder