Clear Sky Science · nl
Ontdekken van geavanceerde transfer-learningstrategieën voor diepe neurale netwerken in natuurlijke taalverwerking
Waarom slimme taalinstrumenten ertoe doen
Van e-mailfilters tot chatbots en vertaalapps: veel van de digitale hulpmiddelen van vandaag zijn afhankelijk van computers die menselijke taal kunnen lezen en schrijven. Het trainen van zulke systemen vanaf nul is kostbaar en vraagt veel data, dus onderzoekers beginnen vaak met grote, vooraf getrainde taalmodellen en passen die aan voor nieuwe taken—een methode die transfer learning heet. Dit artikel bekijkt systematisch hoe verschillende manieren van aanpassen zich verhouden, en vergelijkt zeven strategieën over meerdere typen taaltaken om te achterhalen welke de beste balans bieden tussen nauwkeurigheid, snelheid en praktisch toepasbaarheid in echte situaties.
Hoe machines hergebruiken wat ze al weten
De studie begint met een toelichting op hoe moderne taalsystemen leren van enorme tekstverzamelingen en die kennis vervolgens opnieuw gebruiken voor nieuwe taken. Bekende modellen zoals BERT en zijn grotere verwant (in dit werk BERT-3 genoemd) leren eerst algemene patronen in woorden en zinnen. Later worden ze bijgestuurd voor specifieke doelen zoals het classificeren van nieuwsonderwerpen, het beoordelen van de toon van socialmediaposts of het vertalen tussen Engels en Frans. De auteurs zetten “full fine-tuning”, waarbij elk onderdeel van het model wordt aangepast voor de nieuwe taak, af tegen “feature-based” benaderingen die het grote model als bevroren feature-extractor gebruiken en een kleiner, eenvoudiger model voeden. Ze belichten ook strategieën die veranderen hoe data aan het model worden aangeboden, waaronder progressieve training die begint met eenvoudigere gevallen en naar moeilijkere gaat.
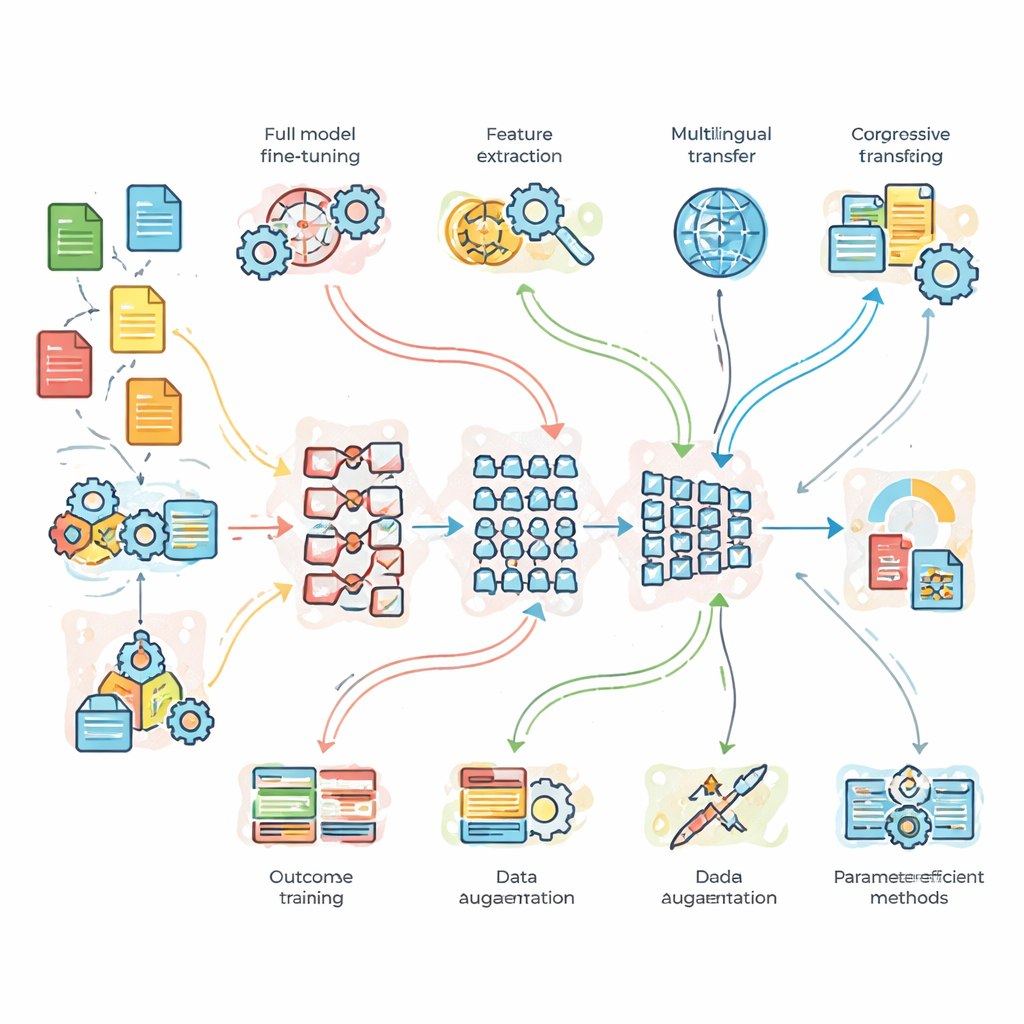
Wat de onderzoekers in de praktijk testten
Om verder te gaan dan theorie voerde het team gecontroleerde experimenten uit op drie benchmarkproblemen. Ten eerste een classificatietaak voor nieuwsonderwerpen met veel schone data; ten tweede sentimentanalyse op rumoerige tweets vol slang; en ten derde Engelse-naar-Franse vertaling. Ze vergeleken een licht, op maat gebouwd basismodel, standaard BERT en een dieper BERT-3-model. Daarbovenop pasten ze zeven adaptatiestrategieën toe: full fine-tuning, feature-based transfer, progressieve en domeinaanpassende training, meertalige fine-tuning, data-augmentatie (bijvoorbeeld door zinnen te parafraseren), en twee moderne “parameter-efficiënte” methoden die slechts een klein deel van de interne knoppen van het model aanpassen. Deze opzet stelde hen in staat niet alleen te vragen welk model het sterkst is, maar ook wanneer extra complexiteit of meer data echt rendeert.
Welke modellen en strategieën er bovenuit steken
De resultaten tonen een duidelijk patroon: het grotere BERT-3-model presteert consequent beter dan zowel standaard BERT als het lichtgewicht basismodel bij de zwaardere taken, vooral bij sentimentanalyse en vertaling. Het eenvoudige model blijft echter verrassend competitief bij de eenvoudige nieuwsklassificatie, wat benadrukt dat groter niet altijd nodig is. Wat trainingsstrategieën betreft leveren progressieve en domeinaanpassende fine-tuning de beste scores op, vooral bij moeilijkere voorbeelden met langere of complexere formuleringen. Data-augmentatie helpt ook, en werkt veelal als het verkrijgen van extra trainingsdata door bestaande zinnen anders te formuleren. Cruciaal is dat twee parameter-efficiënte benaderingen—adapter-lagen en een methode genaamd LoRA—zeer dicht bij de beste prestaties komen terwijl ze minder dan vijf procent van de modelparameters bijwerken, wat het geheugen- en rekengebruik sterk vermindert.
Waarom datavolume en taald diversiteit nog steeds belangrijk zijn
De studie onderzoekt ook hoeveel gelabelde data nodig zijn wanneer transfer learning wordt toegepast. De nauwkeurigheid stijgt gestaag naarmate het aantal trainingsvoorbeelden toeneemt, maar dankzij het starten vanaf een voorgetraind model halen zelfs runs met zo weinig als 1.000 voorbeelden prestaties die normaal veel meer data zouden vergen. De verbeteringen vlakken rond 20.000 voorbeelden af voor de schonere benchmarks, hoewel complexere, rumoerige datasets nog steeds profiteren van grotere trainingssets. Meertalige modellen, die op veel talen tegelijk zijn getraind, helpen wanneer gelabelde data schaars zijn in een bepaalde taal, maar ze kunnen iets achterblijven bij eentalige modellen wanneer er veel Engelse voorbeelden beschikbaar zijn, wat wijst op een afweging tussen brede dekking en fijne specialisatie.
Wat dit betekent voor toekomstige taaltechnologieën
Voor lezers buiten het vakgebied is de belangrijkste conclusie dat er geen enkel ‘‘beste’’ recept is voor het aanpassen van grote taalmodellen. Grotere modellen zoals BERT-3 excelleren bij uitdagende begrip- en vertaaltaken, terwijl kleinere netwerken prima voldoen voor eenvoudigere taken. Methoden die taken geleidelijk introduceren of de trainingsset uitbreiden met geparafraseerde voorbeelden maken systemen over het algemeen robuuster, vooral wanneer data beperkt zijn. Misschien nog belangrijker: nieuwere technieken die alleen kleine aanvullende componenten aanpassen bieden bijna topniveau nauwkeurigheid tegen een fractie van de kosten. Samen suggereren deze bevindingen een toekomst waarin krachtige taalinstrumenten nauwkeuriger kunnen worden afgestemd op de behoeften en middelen van verschillende bedrijven, talen en toepassingen, waardoor geavanceerde NLP toegankelijker en efficiënter wordt.
Bronvermelding: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Trefwoorden: transfer learning, natuurlijke taalverwerking, fine-tuningstrategieën, grote taalmodellen, parameter-efficiënte methoden