Clear Sky Science · pl
Odkrywanie zaawansowanych strategii transferu uczenia dla głębokich sieci neuronowych w przetwarzaniu języka naturalnego
Dlaczego mądrzejsze narzędzia językowe mają znaczenie
Od filtrów poczty po chatboty i aplikacje tłumaczeniowe — wiele dzisiejszych narzędzi cyfrowych opiera się na komputerach potrafiących czytać i pisać w języku naturalnym. Trenowanie takich systemów od zera jest kosztowne i wymaga dużych zbiorów danych, dlatego badacze często zaczynają od dużych, już wytrenowanych modeli językowych i dostosowują je do nowych zadań — praktyka ta nazywa się transfer learning. Artykuł ten systematycznie analizuje, jak różne sposoby takiego dostosowania wypadają w praktyce, porównując siedem strategii w kilku typach zadań językowych, aby ustalić, które dają najlepsze połączenie dokładności, szybkości i praktyczności w realnych zastosowaniach.
Jak maszyny wykorzystują to, czego już się nauczyły
Badanie zaczyna się od wyjaśnienia, jak współczesne systemy językowe uczą się ze ogromnych kolekcji tekstów, a następnie wykorzystują tę wiedzę w nowych zadaniach. Znane modele, takie jak BERT i jego większy odpowiednik (nazywany w tej pracy BERT-3), najpierw poznają ogólne wzorce w słowach i zdaniach. Później są kierowane ku konkretnym celom, takim jak klasyfikacja tematów wiadomości, ocena tonu postów w mediach społecznościowych czy tłumaczenie między angielskim a francuskim. Autorzy kontrastują „pełny fine-tuning”, gdzie każda część modelu jest dostosowywana pod nowe zadanie, z podejściami „feature-based”, które traktują duży model jako zamrożony ekstraktor cech przekazujący dane do mniejszego, prostszego modelu. Podkreślają też strategie zmieniające sposób prezentacji danych modelowi, w tym trening progresywny, który zaczyna od prostszych przypadków i stopniowo przechodzi do trudniejszych.
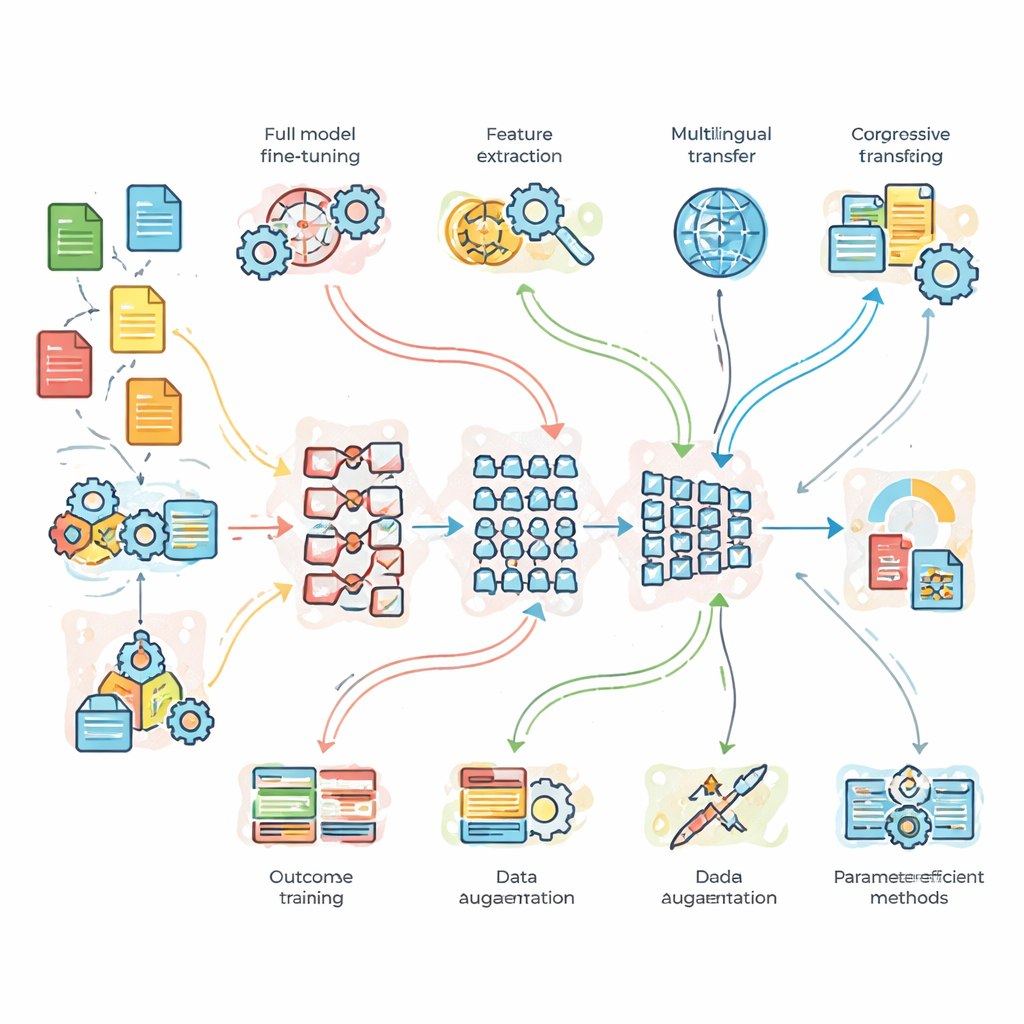
Co badacze przetestowali w praktyce
Aby wyjść poza teorię, zespół przeprowadził kontrolowane eksperymenty na trzech problemach benchmarkowych. Po pierwsze: zadanie klasyfikacji tematów wiadomości z dużą ilością czystych danych; po drugie: analiza sentymentu na hałaśliwych, pełnych slangu tweetach; i po trzecie: tłumaczenie z angielskiego na francuski. Porównali lekki, niestandardowy model bazowy, standardowy BERT oraz głębszy model BERT-3. Na to nałożyli siedem strategii adaptacji: pełny fine-tuning, transfer oparty na cechach, trening progresywny i adaptacyjny względem domeny, fine-tuning wielojęzyczny, zwiększanie danych (np. przez parafrazowanie zdań) oraz dwie nowoczesne metody „efektywne względem parametrów”, które modyfikują tylko niewielką część wewnętrznych parametrów modelu. Takie ustawienie pozwoliło im zapytać nie tylko, który model jest najsilniejszy, ale też kiedy dodatkowa złożoność lub więcej danych rzeczywiście się opłaca.
Które modele i strategie wychodzą na prowadzenie
Wyniki ukazują wyraźny wzorzec: większy model BERT-3 konsekwentnie przewyższa zarówno standardowy BERT, jak i lekki model bazowy w bardziej wymagających zadaniach, szczególnie w analizie sentymentu i tłumaczeniu. Jednak prosty model pozostaje zaskakująco konkurencyjny w prostszej klasyfikacji wiadomości, co podkreśla, że „większe” nie zawsze znaczy „konieczne”. Jeśli chodzi o strategię trenowania, najlepsze ogólne wyniki przynosiła progresywna i adaptacyjna względem domeny procedura fine-tuningu, zwłaszcza na trudniejszych przykładach o dłuższym lub bardziej złożonym sformułowaniu. Zwiększanie danych również pomagało, działając jak uzyskanie dodatkowych przykładów treningowych przez przeformułowanie istniejących zdań. Co kluczowe — dwie metody efektywne względem parametrów, warstwy adapterów i metoda zwana LoRA, osiągały bardzo zbliżone wyniki do najlepszych, aktualizując mniej niż pięć procent parametrów modelu i znacząco zmniejszając zapotrzebowanie na pamięć i moc obliczeniową.
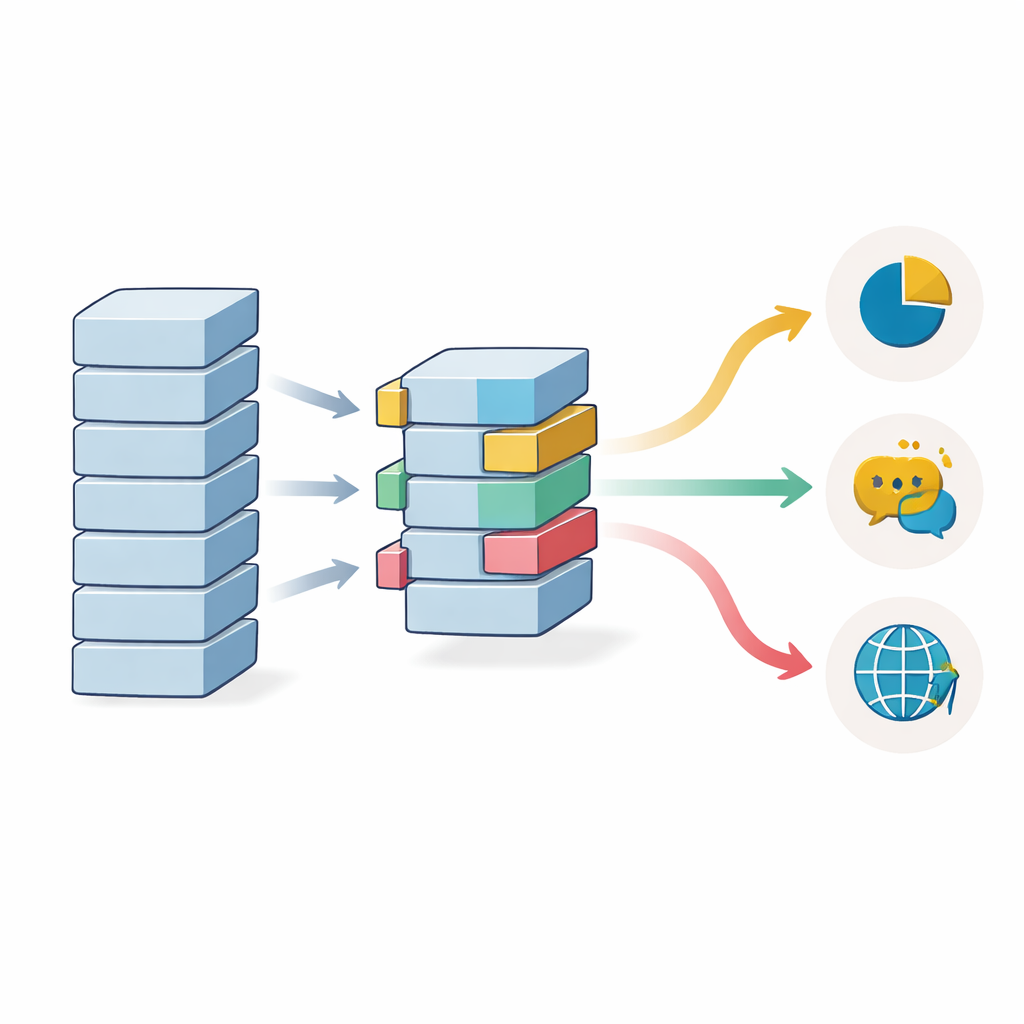
Dlaczego ilość danych i różnorodność językowa wciąż się liczą
W badaniu sprawdzono także, ile oznakowanych danych potrzeba przy zastosowaniu transfer learningu. Dokładność rośnie stopniowo wraz ze wzrostem liczby przykładów treningowych, ale dzięki rozpoczęciu od modelu wstępnie wytrenowanego nawet przebiegi z zaledwie 1 000 przykładów osiągają wydajność, która normalnie wymagałaby znacznie większych zbiorów danych. Zyski zaczynają się wyrównywać w okolicach 20 000 próbek na czystszych benchmarkach, choć bardziej złożone, hałaśliwe zbiory nadal mogą korzystać z większych zestawów treningowych. Modele wielojęzyczne, trenowane równocześnie na wielu językach, pomagają, gdy w danym języku brakuje oznakowanych danych, ale mogą być nieco gorsze od modeli jednojazycznych, gdy dostępnych jest dużo przykładów po angielsku — co wskazuje na kompromis między szerokim pokryciem a drobiazgową specjalizacją.
Co to oznacza dla przyszłych technologii językowych
Dla czytelników spoza dziedziny główny wniosek jest taki, że nie ma jednej „najlepszej” recepty na dostosowywanie dużych modeli językowych. Większe modele, takie jak BERT-3, błyszczą w wymagających zadaniach rozumienia i tłumaczenia, podczas gdy mniejsze sieci mogą być w pełni wystarczające do prostszych zadań. Metody wprowadzające zadania stopniowo lub rozszerzające zestaw treningowy o parafrazy generalnie zwiększają odporność systemów, zwłaszcza gdy dane są ograniczone. Być może najważniejsze jest to, że nowsze techniki, które modyfikują jedynie małe dodatkowe komponenty, oferują niemal czołową dokładność przy ułamku kosztów. Razem te ustalenia sugerują przyszłość, w której potężne narzędzia językowe można będzie dostosowywać precyzyjniej do potrzeb i zasobów różnych firm, języków i zastosowań, co uczyni zaawansowane NLP bardziej dostępnym i wydajnym.
Cytowanie: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Słowa kluczowe: transfer learning, przetwarzanie języka naturalnego, strategie fine-tuningu, duże modele językowe, metody efektywne względem parametrów