Clear Sky Science · he
חשיפת אסטרטגיות מתקדמות להעברת למידה ברשתות נוירונים עמוקות בעיבוד שפה טבעית
למה כלים שפתיים חכמים יותר חשובים
מסינוני דואר אלקטרוני ועד צ׳אטבוטים ואפליקציות תרגום — רבים מכלי היומיום הדיגיטליים מסתמכים על מחשבים היכולים לקרוא ולכתוב בשפה אנושית. לאימון מערכות אלה מאפס יש עלות גבוהה ודרישות נתונים גדולות, ולכן חוקרים לרוב מתחילים ממודלים שפתיים גדולים שכבר אומנו ומותאמים להם משימות חדשות — פרקטיקה שנקראת העברת למידה. מאמר זה בוחן באופן שיטתי כיצד דרכים שונות של התאמה זו מתפקדות, ומשווה בין שבע אסטרטגיות על פני מספר סוגי משימות שפתיות כדי לגלות אילו מהן מספקות את השילוב הטוב ביותר של דיוק, מהירות ומעשיות בסביבות עולם-אמיתי.
כיצד מכונות משתמשות במה שכבר ידוע להן
המחקר מתחיל בהסבר על האופן שבו מערכות שפה מודרניות לומדות מקולקציות טקסט רחבות ואז משתמשות בידע הזה במשימות חדשות. מודלים מוכרים כמו BERT וקרוב משפחתו הגדול יותר (המכונה בעבודה זו BERT-3) לומדים תחילה דפוסים כלליים של מילים ומשפטים. לאחר מכן הם מוסטות לעבר מטרות ספציפיות כגון סיווג נושאי חדשות, הערכת הטון בפוסטים ברשתות החברתיות או תרגום מאנגלית לצרפתית. המחברים משווים בין "כוונון עדין מלא", בו כל חלקי המודל מותאמים למשימה החדשה, לבין גישות מבוססות תכונה שמטפלות במודל הגדול כמפיק תכונות מוקפא שמזין מודל קטן ופשוט יותר. הם גם מדגישים אסטרטגיות שמשנות את אופן הצגת הנתונים למודל, כולל אימון פרוגרסיבי שמתחיל במקרה קל ועובר בהדרגה למקרים קשים יותר.
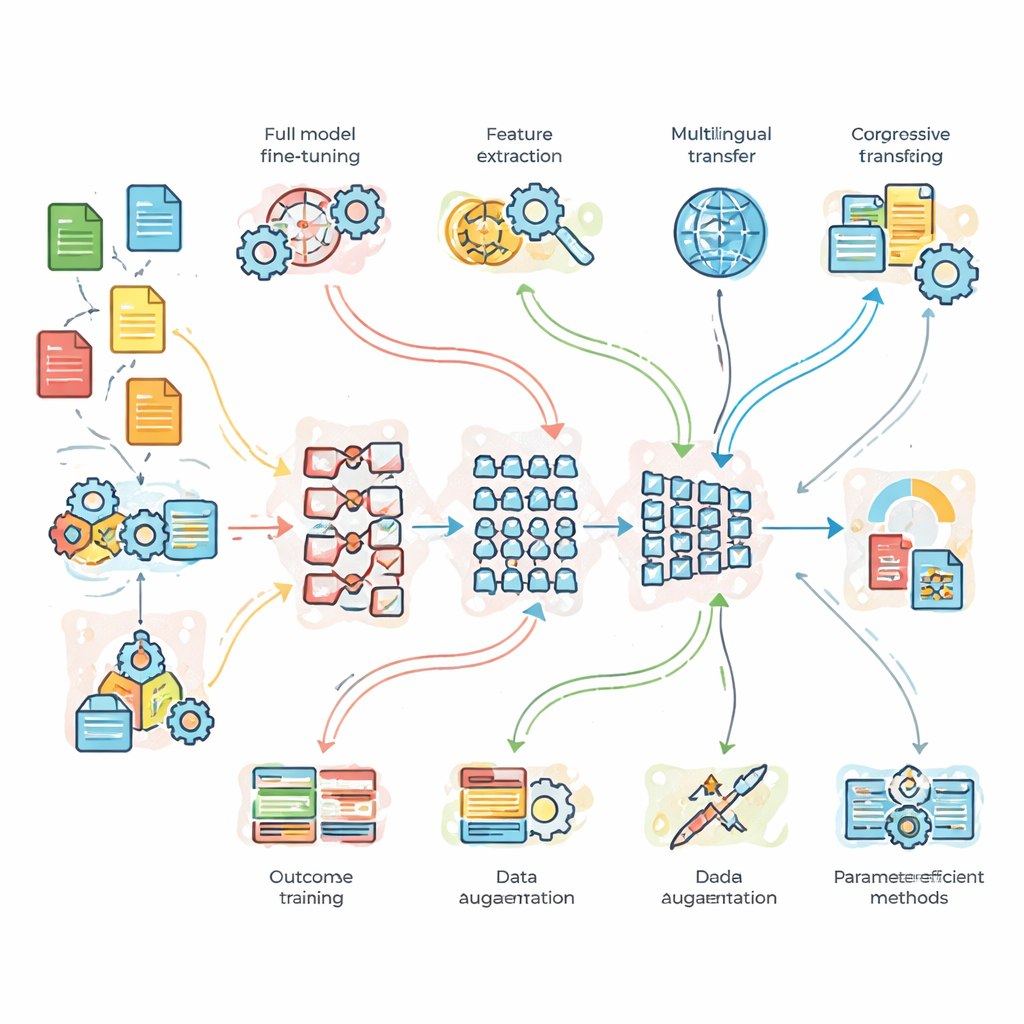
מה החוקרים בדקו בפועל
כדי לצאת מעבר לתיאוריה, הצוות ערך ניסויים מבוקרים על שלושה בעיות תקניות. ראשית, משימת סיווג נושאי חדשות עם נתונים נקיים בשפע; שנית, ניתוח סנטימנט על ציוצים רועשים ומלאי סלנג; ושלישית, תרגום מאנגלית לצרפתית. הם השוו רשת בסיס קלה שבנו בהתאמה, BERT סטנדרטי, ומודל עמוק יותר BERT-3. מעליהם הם ניסו שבע אסטרטגיות התאמה: כוונון עדין מלא, העברה מבוססת תכונות, אימון פרוגרסיבי ואימון אדפטיבי לתחום, כוונון רב-לשוני, הגברת נתונים (למשל על ידי פרפרזינג של משפטים), ושתי שיטות מודרניות "חסכוניות בפרמטרים" שמכווננות רק חלק קטן מהמפרטים הפנימיים של המודל. תצורה זו איפשרה להם לשאול לא רק איזה מודל החזק ביותר, אלא מתי מורכבות נוספת או נתונים נוספים באמת מצדיקים את עצמם.
אילו מודלים ואסטרטגיות מובילים
התוצאות מציירות דפוס ברור: המודל הגדול BERT-3 משיג באופן עקבי ביצועים טובים יותר משניהם — BERT הסטנדרטי והרשת הקלה — במשימות התובעניות יותר, במיוחד בניתוח סנטימנט ובתרגום. עם זאת, המודל הפשוט נותר תחרותי באופן מפתיע בסיווג חדשות ישיר, מה שמדגיש שגדול אינו תמיד הכרחי. מבחינת אסטרטגיית אימון, כוונון פרוגרסיבי ואימון אדפטיבי לתחום מספקים את הציונים הכוללים הטובים ביותר, במיוחד בדוגמאות קשות שבהן הניסוח ארוך או מורכב יותר. הגברת נתונים גם היא תורמת, ומתפקדת בדומה להגדלת מערך האימון על ידי ניסוח מחדש של משפטים קיימים. והעיקר — שתי גישות חסכוניות בפרמטרים — שכבות אדפטר ושיטה הנקראת LoRA — מתקרבות מאוד לביצועים הטובים ביותר בעודן מעדכנות פחות מחמישה אחוזים מפרטרי המודל, מה שמקטין באופן משמעותי את דרישות הזיכרון והחישוב.
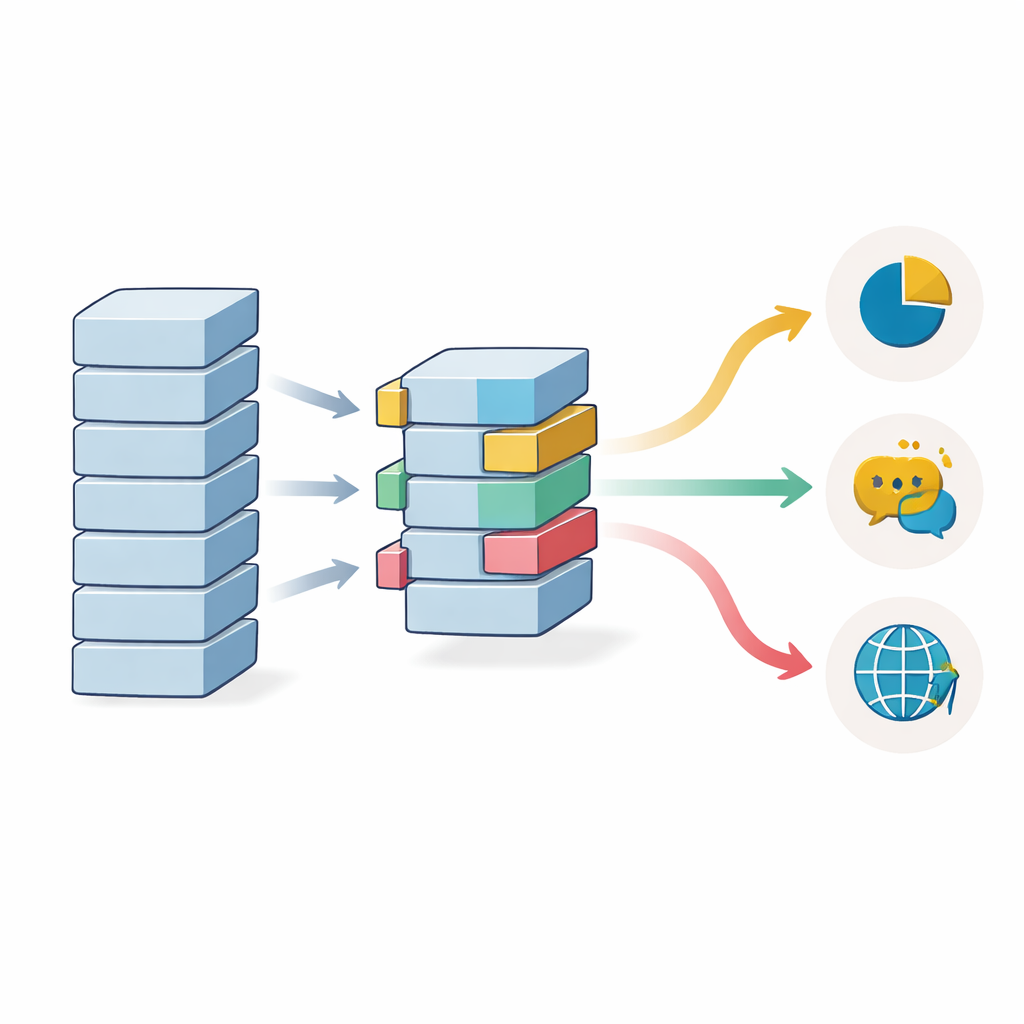
מדוע כמות הנתונים וגיוון השפות עדיין חשובים
המחקר בוחן גם כמה דוגמאות מתויגות נחוצות כאשר משתמשים בהעברת למידה. הדיוק עולה בהתמדה ככל שמספר דוגמאות האימון גדל, אך הודות להתחלה ממודל שאומן מראש, אפילו ניסויים עם כמה אלפי דוגמאות בלבד (כ-1,000) משיגים ביצועים שבדרך כלל היו דרושים להם הרבה יותר נתונים. הרווחים מתחילים להירגע סביב כ-20,000 דוגמאות בבדיקות הנקיות יותר, אם כי מערכי נתונים מורכבים ורועשים יכולים עדיין ליהנות ממערכי אימון גדולים יותר. מודלים רב-לשוניים, שאומנו על שפות רבות בו-זמנית, עוזרים כאשר נתונים מתויגים דלים בשפה מסוימת, אך הם עלולים להישאר מעט מאחורי מודלים חד-לשוניים כאשר יש שפע דוגמאות באנגלית — מה שמעיד על פשרה בין כיסוי רחב להתמחות דקה.
מה משמעות הדבר לטכנולוגיות שפה עתידיות
לקוראים חיצוניים לתחום, המסקנה העיקרית היא שאין מתכון יחיד "הטוב ביותר" להתאמת מודלים שפתיים גדולים. מודלים גדולים כמו BERT-3 מצטיינים במשימות קשות של הבנה ותרגום, בעוד שרשתות קטנות יכולות להספיק לחלוטין למשימות פשוטות יותר. שיטות שמחדירות משימות בהדרגה או מרחיבות את מערך האימון בדוגמאות פרפרזיות בדרך כלל משפרות את העמידות של המערכות, במיוחד כשיש מגבלות נתונים. ואולי החשוב מכל — טכניקות חדשות שמעדכנות רק רכיבים תוספתיים קטנים מציעות דיוק כמעט שיאי במחיר של חלק קטן מהעלות. יחד, ממצאים אלה מצביעים על עתיד שבו כלים שפתיים רבי-עוצמה ניתנים להתאמה מדויקת יותר לצרכים ולמשאבים של חברות, שפות ויישומים שונים, מה שעושה את תחום ה-NLP המתקדם לנגיש ויעיל יותר.
ציטוט: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
מילות מפתח: העברת למידה, עיבוד שפה טבעית, אסטרטגיות כוונון עדין, מודלים שפתיים גדולים, שיטות חסכוניות בפרמטרים