Clear Sky Science · it
Scoprire strategie avanzate di transfer learning per reti neurali profonde nell’elaborazione del linguaggio naturale
Perché contano strumenti linguistici più intelligenti
Dai filtri per le e-mail ai chatbot e alle app di traduzione, molti degli strumenti digitali odierni si basano su computer in grado di leggere e scrivere il linguaggio umano. Addestrare questi sistemi da zero è costoso e richiede grandi quantità di dati, quindi i ricercatori partono spesso da grandi modelli linguistici già addestrati e li adattano a nuovi compiti—una pratica chiamata transfer learning. Questo articolo esamina in modo sistematico come diverse modalità di adattamento si confrontano, comparando sette strategie su vari tipi di compiti linguistici per capire quali offrono il miglior equilibrio fra accuratezza, rapidità e praticità in scenari reali.
Come le macchine riutilizzano ciò che già sanno
Lo studio comincia spiegando come i sistemi linguistici moderni apprendono da vaste raccolte di testo e poi riutilizzano queste conoscenze su nuovi compiti. Modelli noti come BERT e il suo cugino più grande (chiamato BERT-3 in questo lavoro) apprendono prima schemi generali di parole e frasi. Successivamente vengono orientati verso obiettivi specifici come classificare argomenti di notizie, giudicare il tono di post sui social o tradurre dall’inglese al francese. Gli autori mettono a confronto il “full fine-tuning”, dove ogni parte del modello viene regolata per il nuovo compito, con approcci “feature-based” che trattano il grande modello come un estrattore di caratteristiche congelato che alimenta un modello più piccolo e semplice. Evidenziano inoltre strategie che modificano come i dati sono presentati al modello, includendo l’addestramento progressivo che parte da casi più facili e passa a quelli più difficili.
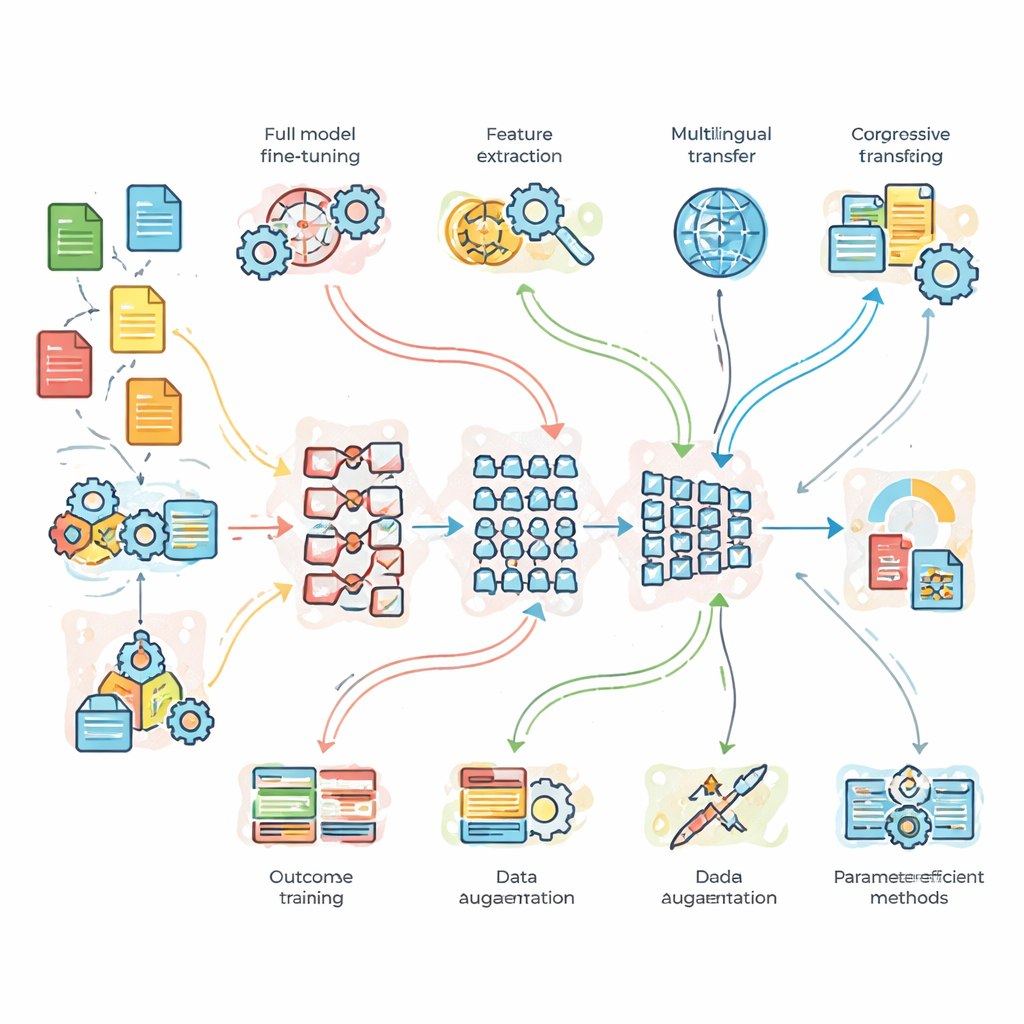
Cosa i ricercatori hanno testato in pratica
Per andare oltre la teoria, il team ha condotto esperimenti controllati su tre problemi benchmark. Primo, una classificazione di argomenti di notizie con molti dati puliti; secondo, analisi del sentiment su tweet rumorosi e ricchi di gergo; e terzo, traduzione dall’inglese al francese. Hanno confrontato una rete di base leggera e costruita ad hoc, il BERT standard e un modello più profondo BERT-3. Su questi hanno applicato sette strategie di adattamento: full fine-tuning, transfer feature-based, addestramento progressivo e domain-adaptive, fine-tuning multilingue, data augmentation (ad esempio parafrasando frasi), e due moderne tecniche “efficienti in termini di parametri” che modificano solo una piccola frazione delle manopole interne del modello. Questa impostazione ha permesso di valutare non solo quale modello sia più forte, ma anche quando complessità o dati aggiuntivi ripagano davvero.
Quali modelli e strategie emergono vincenti
I risultati mostrano uno schema chiaro: il modello più grande BERT-3 supera costantemente sia il BERT standard sia la baseline leggera nei compiti più impegnativi, in particolare nell’analisi del sentiment e nella traduzione. Tuttavia, il modello semplice rimane sorprendentemente competitivo nella classificazione di notizie più lineare, sottolineando che più grande non è sempre necessario. Quanto alla strategia di addestramento, il fine-tuning progressivo e domain-adaptive offre i punteggi complessivi migliori, specialmente sugli esempi più difficili in cui la formulazione è più lunga o complessa. Anche la data augmentation aiuta, funzionando in pratica come ottenere dati di addestramento aggiuntivi parafrasando frasi esistenti. Elemento cruciale: due approcci efficienti in termini di parametri—i layer adattatori e un metodo chiamato LoRA—si avvicinano molto alle migliori prestazioni aggiornando meno del cinque percento dei parametri del modello, riducendo nettamente memoria e requisiti di calcolo.
Perché quantità di dati e diversità linguistica contano ancora
Lo studio esplora anche quante etichette siano necessarie quando si usa il transfer learning. L’accuratezza aumenta progressivamente all’aumentare dei campioni di addestramento, ma grazie alla partenza da un modello pre-addestrato anche esperimenti con appena 1.000 esempi raggiungono prestazioni che normalmente richiederebbero molti più dati. I guadagni iniziano a stabilizzarsi intorno alle 20.000 istanze sui benchmark più puliti, sebbene dataset più complessi e rumorosi possano ancora beneficiare di set di addestramento più grandi. I modelli multilingue, addestrati su molte lingue contemporaneamente, aiutano quando i dati etichettati sono scarsi in una lingua particolare, ma possono rimanere leggermente indietro rispetto ai modelli monolingue quando sono disponibili molti esempi in inglese, indicando un compromesso tra copertura ampia e specializzazione fine.
Cosa significa questo per le future tecnologie linguistiche
Per i lettori al di fuori del campo, la conclusione principale è che non esiste una singola “ricetta migliore” per adattare grandi modelli linguistici. Modelli più grandi come BERT-3 brillano nei compiti complessi di comprensione e traduzione, mentre reti più piccole possono essere perfettamente adeguate per lavori più semplici. Metodi che introducono i compiti gradualmente o ampliano il set di addestramento con esempi parafrasati rendono i sistemi generalmente più robusti, specialmente quando i dati sono limitati. Forse più importante, le tecniche più recenti che regolano solo piccoli componenti aggiuntivi offrono prestazioni quasi al top a una frazione del costo. Nel complesso, questi risultati suggeriscono un futuro in cui potenti strumenti linguistici possono essere adattati in modo più preciso alle esigenze e alle risorse di diverse aziende, lingue e applicazioni, rendendo l’NLP avanzato più accessibile ed efficiente.
Citazione: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Parole chiave: transfer learning, elaborazione del linguaggio naturale, strategie di fine-tuning, grandi modelli linguistici, metodi efficienti in termini di parametri