Clear Sky Science · ja
自然言語処理における深層ニューラルネットワークの高度な転移学習戦略の解明
より賢い言語ツールが重要な理由
メールフィルタやチャットボット、翻訳アプリなど、今日の多くのデジタルツールは人間の言語を読み書きできるコンピュータに依存しています。これらのシステムを一から学習させるのはコストが高くデータも大量に必要なため、研究者は既に大規模に学習済みの言語モデルを出発点として新しいタスクに適応させることが多く、これを転移学習と呼びます。本稿はその適応方法を体系的に検討し、複数の言語タスクに対して7つの戦略を比較することで、実運用で求められる精度、速度、実用性の最適な組み合わせを明らかにします。
機械は既知の知識をどう再利用するか
本研究は、まず現代の言語システムが膨大なテキストコレクションからどのように学び、それを新しいタスクに再利用するかを説明します。BERTのようなよく知られたモデルや、本稿でBERT-3と呼ばれるより大きなモデルは、まず語や文の一般的なパターンを学習します。その後、ニュースのトピック分類、SNS投稿の感情判定、英仏間の翻訳など特定の目的へと調整されます。著者らはモデルの全ての部分を新タスク向けに調整する「完全ファインチューニング」と、大規模モデルを固定した特徴抽出器として扱い小さなモデルに入力する「特徴ベース」のアプローチを対比します。また、データの提示方法を変える戦略、例えば簡単な例から始め徐々に難しい例へ移る漸進的トレーニングのような手法も強調しています。
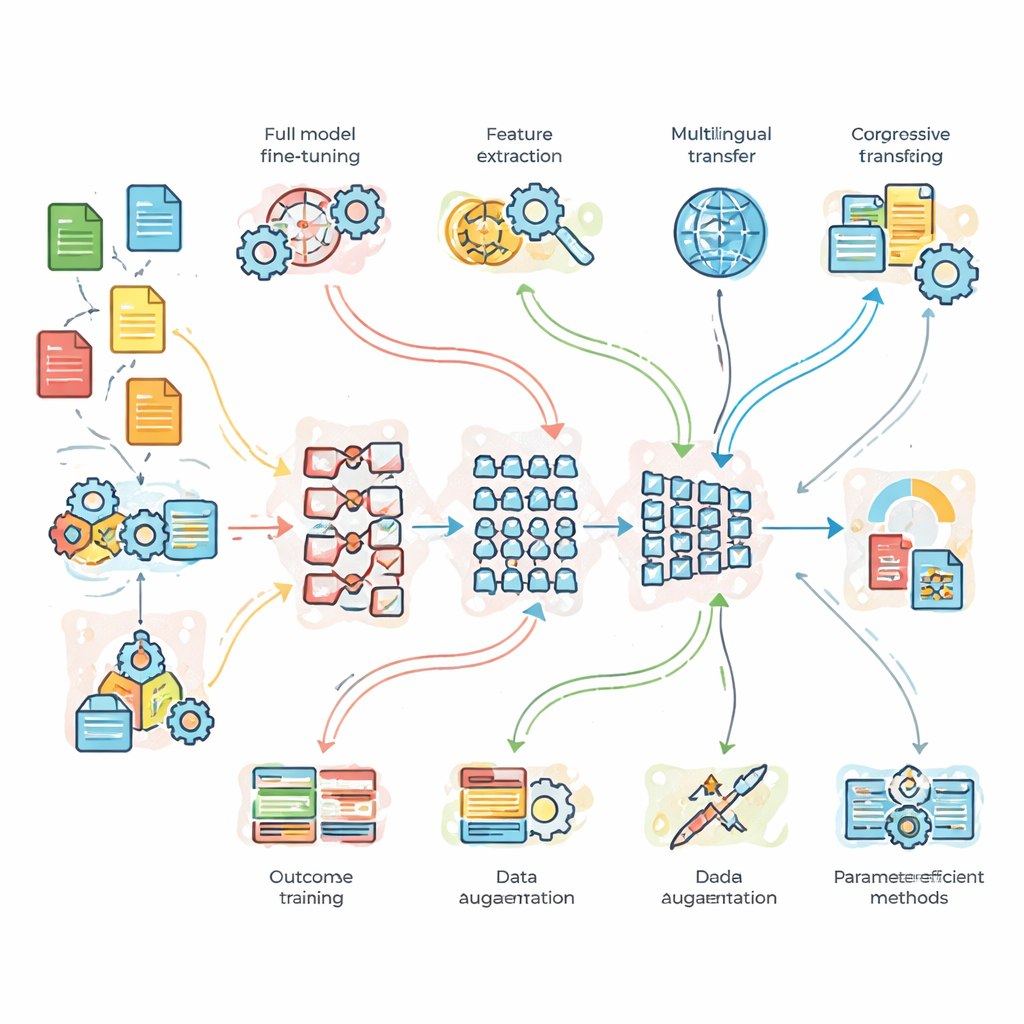
研究者たちが実際に試したこと
理論を超えるために、チームは3つのベンチマーク課題で制御された実験を行いました。まずは十分なクリーンデータがあるニュースのトピック分類、次にスラングやノイズの多いツイートの感情分析、そして英語からフランス語への翻訳です。比較対象は軽量のカスタムベースラインネットワーク、標準的なBERT、より深いBERT-3モデルです。これらに対して7つの適応戦略を重ねて評価しました:完全ファインチューニング、特徴ベースの転移、漸進的およびドメイン適応トレーニング、多言語ファインチューニング、データ拡張(例えば文の言い換えによる増強)、そしてモデル内部のごく一部だけを調整する2つの現代的な「パラメータ効率の良い」手法です。この構成により、どのモデルが最強かだけでなく、追加の複雑さやデータ投入が実際に有益になる場面を問えるようになりました。
優れたモデルと戦略はどれか
結果は明瞭な傾向を示しています:より大きなBERT-3モデルは、特に感情分析や翻訳など負荷の高いタスクで、標準BERTや軽量ベースラインを一貫して上回りました。しかし、単純なニュース分類では軽量モデルが意外に競争力を維持しており、必ずしも大きいモデルが常に必要というわけではないことを示しています。トレーニング戦略では、漸進的およびドメイン適応ファインチューニングが全体的に最良のスコアを提供し、文が長かったり複雑な表現が多い難しい例で特に効果を発揮しました。データ拡張も既存文の言い換えにより追加の学習データを得るように有効です。重要な点として、アダプター層やLoRAと呼ばれる2つのパラメータ効率の良い手法は、モデルのパラメータの5%未満を更新するだけで最良に非常に近い性能を達成し、メモリと計算の負担を大きく削減しました。
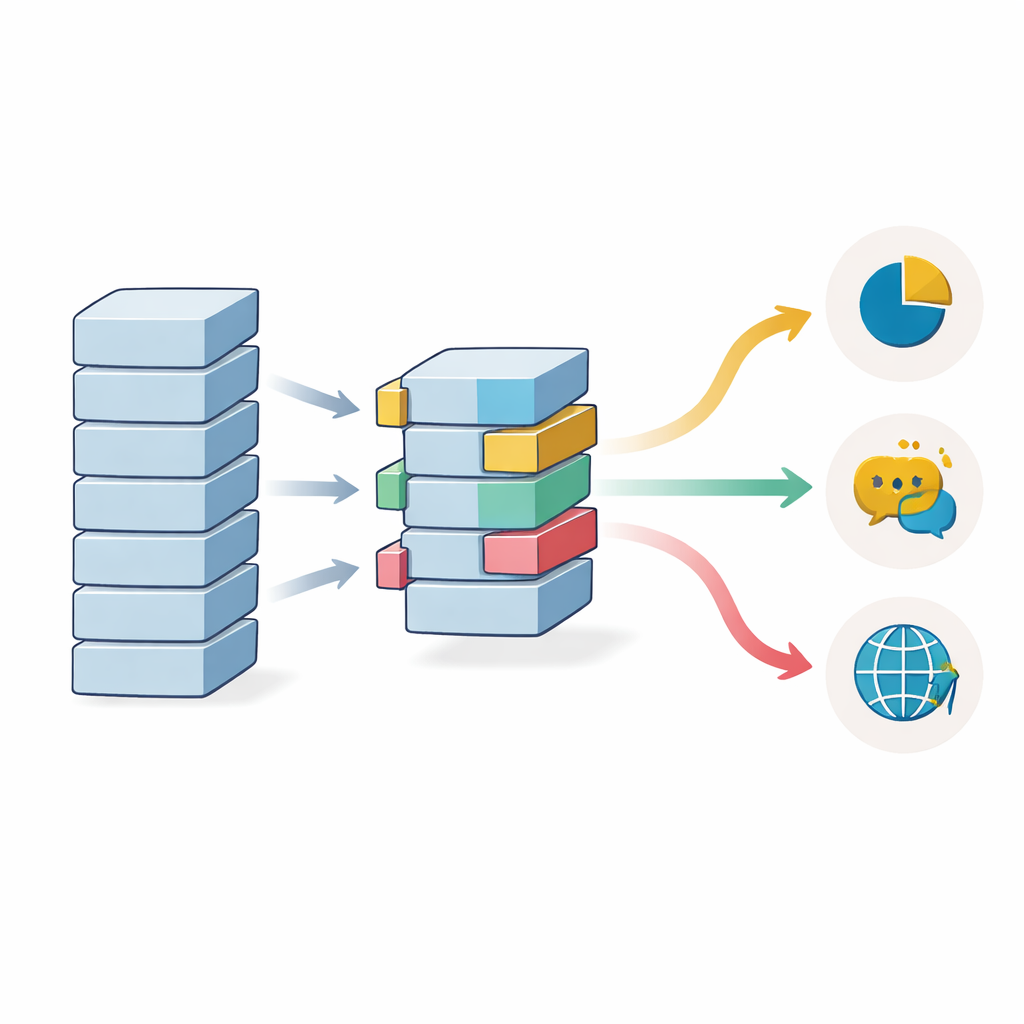
データ量と言語多様性が依然重要な理由
研究はまた、転移学習を用いる場合にどれだけのラベル付きデータが必要かも検証しています。学習サンプルが増えるにつれて精度は着実に向上しますが、事前学習済みモデルから始めることで、わずか1,000件程度の例でも通常ならはるかに多くのデータを要する性能に到達します。クリーンなベンチマークでは約20,000サンプルで効果の伸びが鈍化し始めますが、より複雑でノイズの多いデータセットではさらに大きな学習セットが引き続き有益です。多言語モデルは特定の言語でラベル付きデータが乏しい場合に助けになりますが、英語の例が豊富にある状況では単一言語モデルにわずかに劣ることがあり、広範なカバレッジと細かな専門化の間のトレードオフを示しています。
将来の言語技術にとっての含意
分野外の読者に向けた主要な結論は、大規模言語モデルを適応させる「唯一の最良の」レシピは存在しないということです。BERT-3のような大きなモデルは、難しい理解や翻訳タスクで優れた性能を示し、小さなネットワークはより単純な仕事には十分に適しています。タスクを段階的に導入したり、言い換えによって訓練セットを拡張する手法は、特にデータが限られる場合にシステムの堅牢性を高めます。おそらく最も重要なのは、少数の追加コンポーネントのみを調整する新しい手法が、コストを大幅に抑えつつほぼトップクラスの精度を提供する点です。これらの知見は、企業や言語、用途ごとのニーズやリソースにより精密に合わせた強力な言語ツールが実現しやすくなり、先進的なNLPをより利用しやすく効率的にする未来を示唆しています。
引用: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
キーワード: 転移学習, 自然言語処理, ファインチューニング戦略, 大規模言語モデル, パラメータ効率の良い手法