Clear Sky Science · en
Uncovering advanced transfer learning strategies for deep neural networks in natural language processing
Why smarter language tools matter
From email filters to chatbots and translation apps, many of today’s digital tools rely on computers that can read and write human language. Training these systems from scratch is costly and data-hungry, so researchers often start from large, already-trained language models and adapt them to new jobs—a practice called transfer learning. This paper takes a systematic look at how different ways of doing that adaptation stack up, comparing seven strategies across several types of language tasks to find out which give the best mix of accuracy, speed, and practicality in real-world settings.
How machines reuse what they already know
The study begins by explaining how modern language systems learn from huge text collections and then reuse this knowledge on new tasks. Well-known models like BERT and its larger cousin (called BERT-3 in this work) first learn general patterns of words and sentences. Later, they are nudged toward specific goals such as classifying news topics, judging the tone of social media posts, or translating between English and French. The authors contrast “full fine-tuning,” where every part of the model is adjusted for the new task, with “feature-based” approaches that treat the big model as a frozen feature extractor feeding a smaller, simpler model. They also highlight strategies that change how data are presented to the model, including progressive training that starts with easier cases and moves to harder ones.
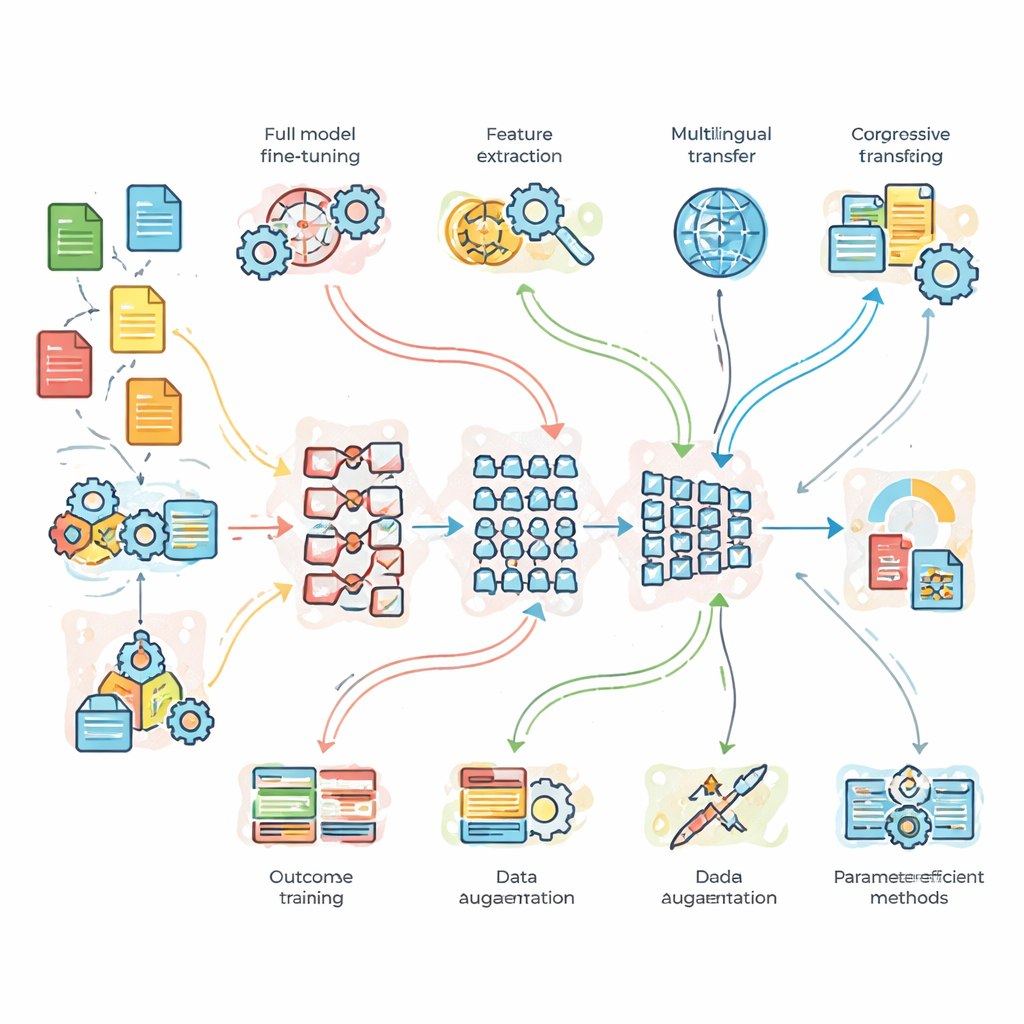
What the researchers tested in practice
To move beyond theory, the team ran controlled experiments on three benchmark problems. First, a news topic classification task with plenty of clean data; second, sentiment analysis on noisy, slang-filled tweets; and third, English-to-French translation. They compared a light custom-built baseline network, standard BERT, and a deeper BERT-3 model. On top of these, they layered seven adaptation strategies: full fine-tuning, feature-based transfer, progressive and domain-adaptive training, multilingual fine-tuning, data augmentation (for example by paraphrasing sentences), and two modern “parameter-efficient” methods that tweak only a small fraction of the model’s internal knobs. This setup allowed them to ask not just which model is strongest, but when extra complexity or data truly pays off.
Which models and strategies come out ahead
The results show a clear pattern: the larger BERT-3 model consistently outperforms both standard BERT and the lightweight baseline on the more demanding tasks, especially sentiment analysis and translation. However, the simple model remains surprisingly competitive on straightforward news classification, underlining that bigger is not always necessary. For training strategy, progressive and domain-adaptive fine-tuning delivers the best overall scores, especially on harder examples where wording is longer or more complex. Data augmentation also helps, acting much like gaining extra training data by rephrasing existing sentences. Crucially, two parameter-efficient approaches—adapter layers and a method called LoRA—come very close to the best performance while updating less than five percent of the model’s parameters, sharply cutting memory and computing needs.
Why data quantity and language diversity still matter
The study also probes how much labeled data are needed when transfer learning is used. Accuracy rises steadily as training samples increase, but thanks to starting from a pre-trained model, even runs with as few as 1,000 examples reach performance that would normally require far more data. Gains start to level off around 20,000 samples on the cleaner benchmarks, though more complex, noisier datasets can still benefit from larger training sets. Multilingual models, which are trained on many languages at once, help when labeled data are scarce in a particular language, but they can lag slightly behind single-language models when plenty of English examples are available, indicating a trade-off between broad coverage and fine-grained specialization.
What this means for future language technologies
For readers outside the field, the main takeaway is that there is no single “best” recipe for adapting large language models. Bigger models like BERT-3 shine on challenging understanding and translation tasks, while smaller networks can be perfectly adequate for simpler jobs. Methods that introduce tasks gradually or expand the training set with paraphrased examples generally make systems more robust, especially when data are limited. Perhaps most importantly, newer techniques that only adjust small add-on components offer nearly top-tier accuracy at a fraction of the cost. Together, these findings suggest a future in which powerful language tools can be tailored more precisely to the needs and resources of different companies, languages, and applications, making advanced NLP more accessible and efficient.
Citation: Abbassy, M.M., Ead, W.M., El-Shora, A.I.A. et al. Uncovering advanced transfer learning strategies for deep neural networks in natural language processing. Sci Rep 16, 14698 (2026). https://doi.org/10.1038/s41598-026-39819-3
Keywords: transfer learning, natural language processing, fine-tuning strategies, large language models, parameter-efficient methods