Clear Sky Science · zh
在神经编码框架下对运动世界的像素级理解
逐像素观察运动的世界
每秒钟,你的眼睛和大脑协同工作,将不断变化的像素洪流转化为稳定且富有意义的世界——人、物体和动作。与此同时,人工智能系统在处理图像和视频时也在学习做类似的事。本文提出了一个简单却有力的问题:当计算机分析视频中的运动、深度和物体时,它们的内部运算是否与人脑对相同场景的反应相似?
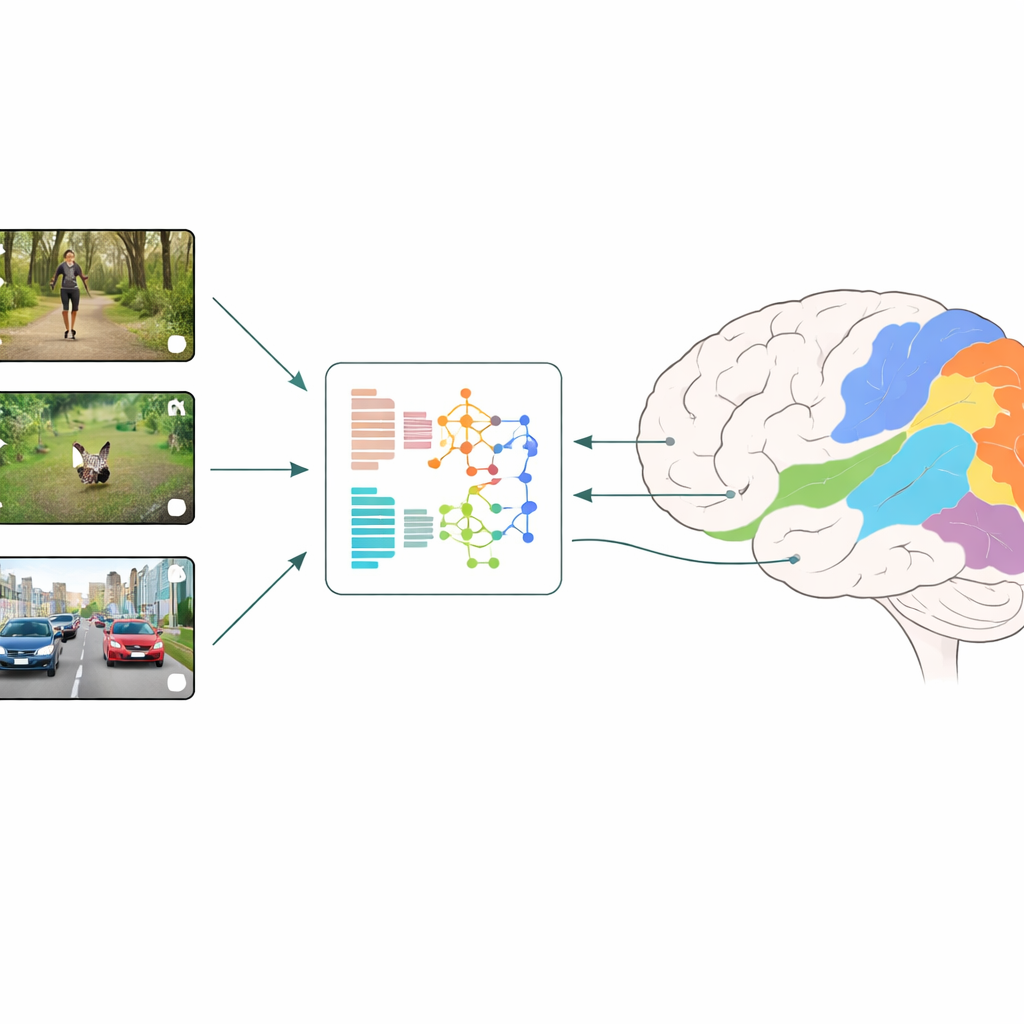
如何比较大脑与机器
研究人员使用一种称为神经编码的策略:他们在用功能性磁共振成像(fMRI)测量视觉皮层多个小区域的活动时,向受试者展示简短的日常视频片段。与此同时,他们将完全相同的视频输入到不同的深度学习模型中,并读取这些模型每一层的内部特征。然后一个回归模型学习如何组合这些人工特征,以最好地预测大脑在各个区域测得的响应。通过比较哪些模型和哪些层给出最佳预测,团队可以推断出哪些类型的视觉计算最接近人类视觉在早期与后期阶段的运作。
像素级任务与整图理解
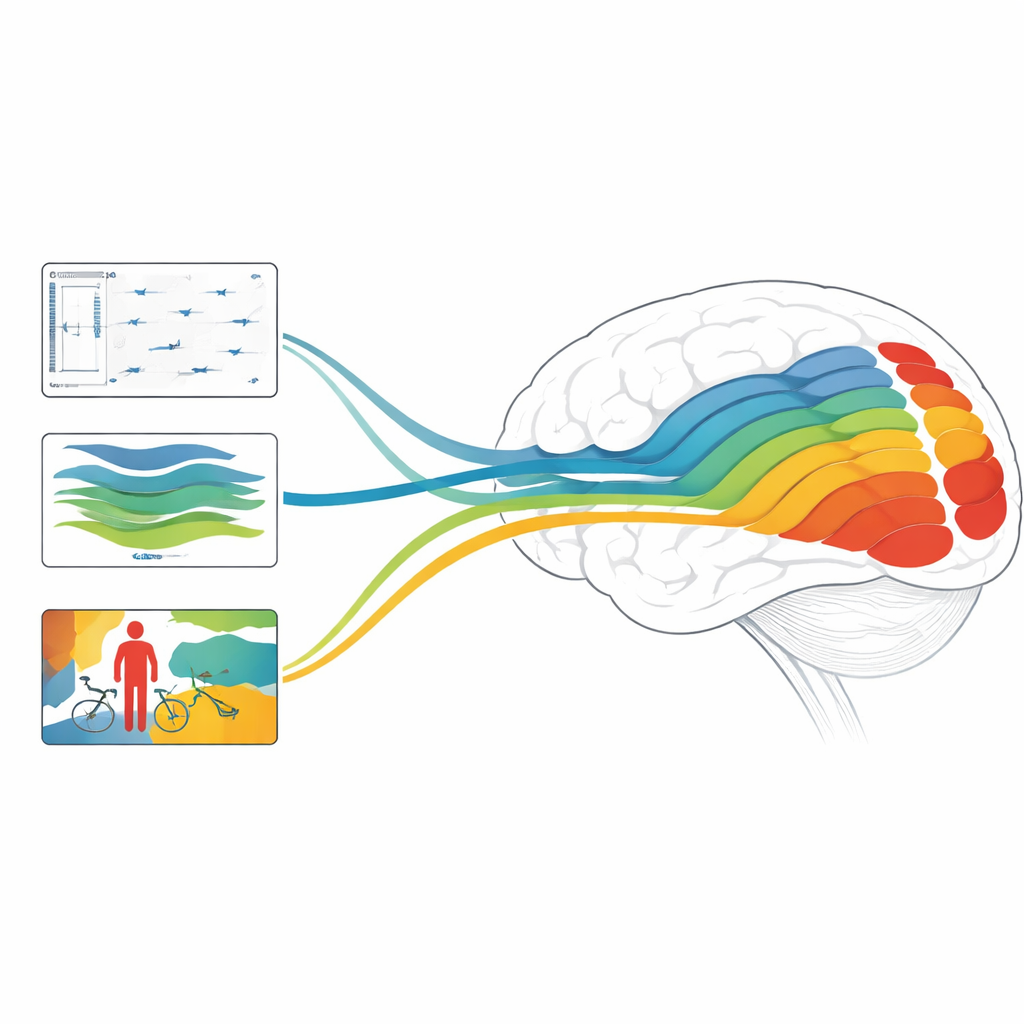
该研究聚焦于三种“像素级”任务——对每个像素都做出预测:光流(每个像素在帧间如何移动)、深度(每个像素到观察者的距离)以及语义分割(每个像素属于哪个物体或身体部位)。这些被拿来与输出单一标签的“粗糙”任务对比,例如物体识别和动作识别。其中一些任务是类别不可知的,如光流和深度,只关心运动或距离,而非物体类别。另一些则是类别相关的,如物体与动作识别以及语义分割,直接学习关于物体、场景、身体和动作的信息。
运动与深度揭示了视觉的什么
当作者比较模型时,出现了清晰的模式。光流模型最能预测早期和中间视觉区域的活动,这些区域已知对边缘、局部运动和简单模式具有强烈反应。然而,这些运动模型在更关注物体、面孔和场景的后期区域表现相对较差。深度估计模型则呈现不同的图景:它们不仅能很好地预测早期区域的响应,还能在沿“哪里”(背侧)和“是什么”(腹侧)视觉通路的更高级区域中表现良好。这表明,即便没有明确训练识别物体类别,深度模型学到的内部表示也携带着关于场景中物体与人的意外丰富信息。
层次、学习类型与脑区
在许多模型族中,早期层往往最能匹配早期视觉区域,而后期层更能匹配高级区域,这与大脑已知的分层结构相呼应。卷积网络在预测早期和中间视觉皮层方面通常优于基于变换器的网络,这很可能是因为卷积天然能捕捉与视觉最初阶段重要的细粒度、高频细节。一个重要的转折是,类别相关模型——那些经训练以命名物体、场景或动作的模型——其输出层提供了非常有信息量的预测,能强烈预测后期视觉区域。相比之下,对于像运动和深度这样的类别不可知任务,最终输出的重要性较小;相反,中间层对大脑响应的匹配最强,尤其是在深度模型中。令人意外的是,在使用相同底层主干网络的情况下,整图的物体识别模型比逐像素的语义分割更能捕捉大脑活动,这暗示了对场景的全局视角对类脑表示至关重要。
这对大脑与机器为何重要
总体而言,研究发现深度、运动和以物体为中心的模型各自与视觉系统的不同阶段对齐,且为同时处理静态结构与快速动态而设计的模型组合可以达到预测大脑响应的最新准确度。对非专业读者而言,关键信息是:现代人工智能不仅仅在模仿我们对图像的标注能力——其内部运算正开始与人类视觉的分层计算产生共鸣。通过剖析哪些任务与架构最能镜像不同脑区,这项工作指向了未来更像我们看世界的人工智能系统——以及探索我们自身大脑如何将嗡鸣、运动的像素流转化为丰富、三维且有意义体验的新方法。
引用: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
关键词: 神经编码, 视觉皮层, 视频理解, 深度学习, 运动与深度