Clear Sky Science · ru
Понимание мира в движении на уровне пикселя в рамках нейронного кодирования
Наблюдая движущийся мир по одному пикселю
Каждую секунду ваши глаза и мозг совместно преобразуют поток меняющихся пикселей в стабильный, содержательный мир людей, объектов и действий. В то же время системы искусственного интеллекта учатся делать нечто похожее при обработке изображений и видео. В этой работе поставлен простой, но важный вопрос: когда компьютеры анализируют движение, глубину и объекты в видео, сходят ли их внутренние представления с тем, как человеческий мозг реагирует на те же сцены?
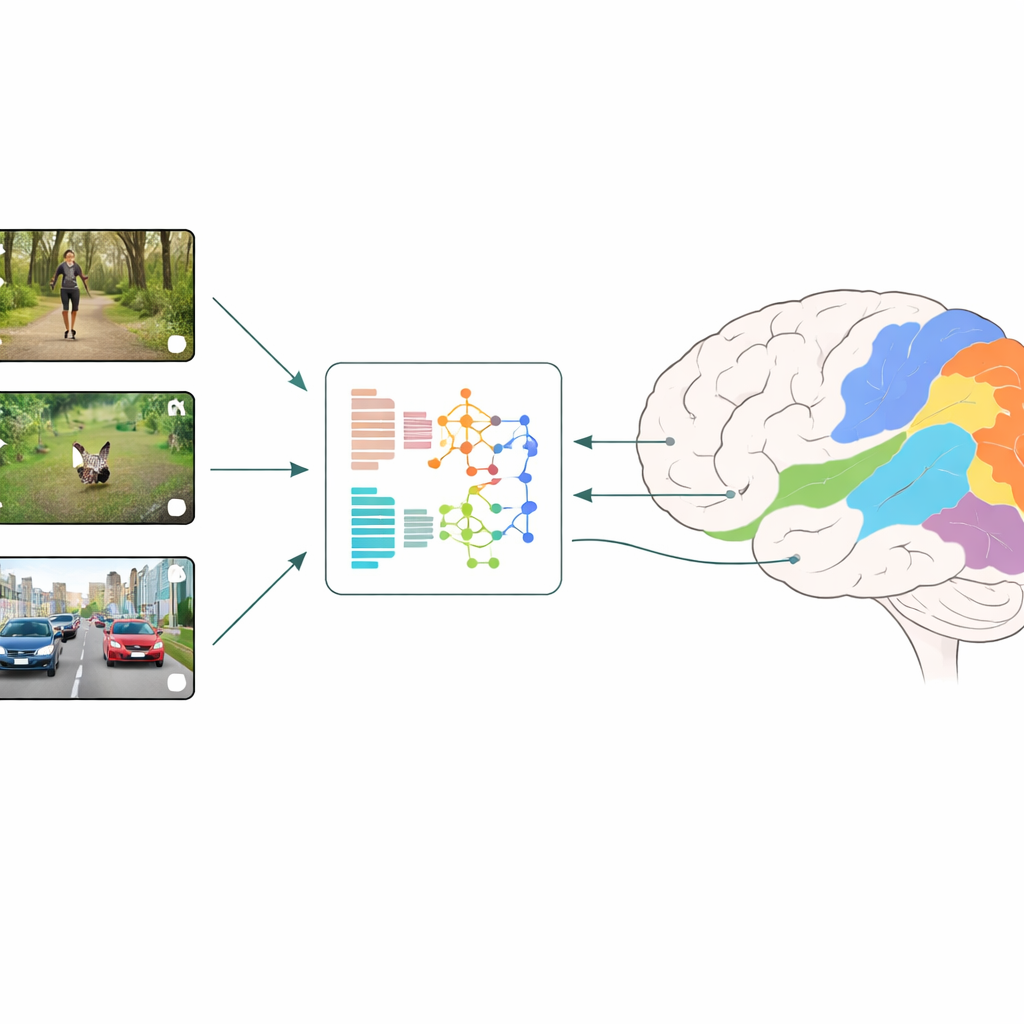
Как сравнивают мозг и машины
Исследователи используют стратегию, называемую нейронным кодированием: людям показывают короткие бытовые видеоклипы и измеряют активность множества небольших участков зрительной коры с помощью fMRI. Параллельно те же самые видео подаются в разные модели глубокого обучения, и извлекаются внутренние признаки моделей на каждом слое. Регрессионная модель затем учится комбинировать эти искусственные признаки так, чтобы наилучшим образом предсказать измеренные реакции мозга по регионам. Сравнивая, какие модели и какие слои дают лучшие предсказания, команда делает выводы о том, какие типы визуальных вычислений ближе всего соответствуют тому, что происходит на ранних и поздних стадиях человеческого зрения.
Задачи на уровне пикселя против понимания целого изображения
Исследование фокусируется на трех «пиксельных» задачах, которые делают предсказание для каждого пикселя: оптический поток (как каждый пиксель перемещается из кадра в кадр), глубина (насколько далеко каждый пиксель от наблюдателя) и семантическая сегментация (какому объекту или части тела принадлежит каждый пиксель). Эти задачи сопоставлены с «грубее» задачами, выдающими лишь одну метку на изображение или видео, такими как распознавание объектов и распознавание действий. Некоторые из этих задач не зависят от класса — например, оптический поток и глубина, которые учитывают только движение или расстояние, а не категории объектов. Другие зависят от класса — такие как распознавание объектов и действий, а также семантическая сегментация, которые непосредственно изучают объекты, сцены, тела и действия.
Что движение и глубина говорят о зрении
При сравнении моделей проявляется четкая картина. Модели оптического потока лучше всего предсказывают активность в ранних и средних зрительных областях, которые известны своей сильной реакцией на края, локальное движение и простые паттерны. Однако эти модели движения относительно плохо работают в поздних областях, которые больше ориентированы на объекты, лица и сцены. Модели оценки глубины дают иную картину: они хорошо предсказывают ответы не только в ранних областях, но и в высокоуровневых зонах как вдоль «где» (дорсального), так и «что» (вентрального) визуальных путей. Это указывает на то, что даже без явного обучения на категории объектов модели глубины усваивают внутренние представления, содержащие неожиданно богатую информацию об объектах и людях в сцене.
Слои, стили обучения и области мозга
В разных семействах моделей ранние слои, как правило, лучше соответствуют ранним зрительным областям, тогда как более поздние слои лучше совпадают с высокоуровневыми областями, что отражает известную иерархию в мозге. Сверточные сети в целом опережают трансформерные сети в предсказании активности ранней и средней зрительной коры, вероятно потому, что свертки естественно улавливают тонкие, высокочастотные детали, важные на первых этапах зрения. Важный нюанс в том, что модели, обученные распознавать классы — те, что учатся называть объекты, сцены или действия — имеют очень информативные выходные слои, которые сильно предсказывают поздние визуальные области. Напротив, для задач, не зависящих от класса, таких как движение и глубина, финальные выходы имеют меньшее значение; вместо этого промежуточные слои дают наилучшее совпадение с реакциями мозга, особенно для глубины. Удивительно, но при использовании одной и той же базовой архитектуры модели распознавания объектов по всему изображению лучше отражают активность мозга, чем покадровая семантическая сегментация, что намекает на то, что глобальный взгляд на сцену важен для мозеподобных представлений.
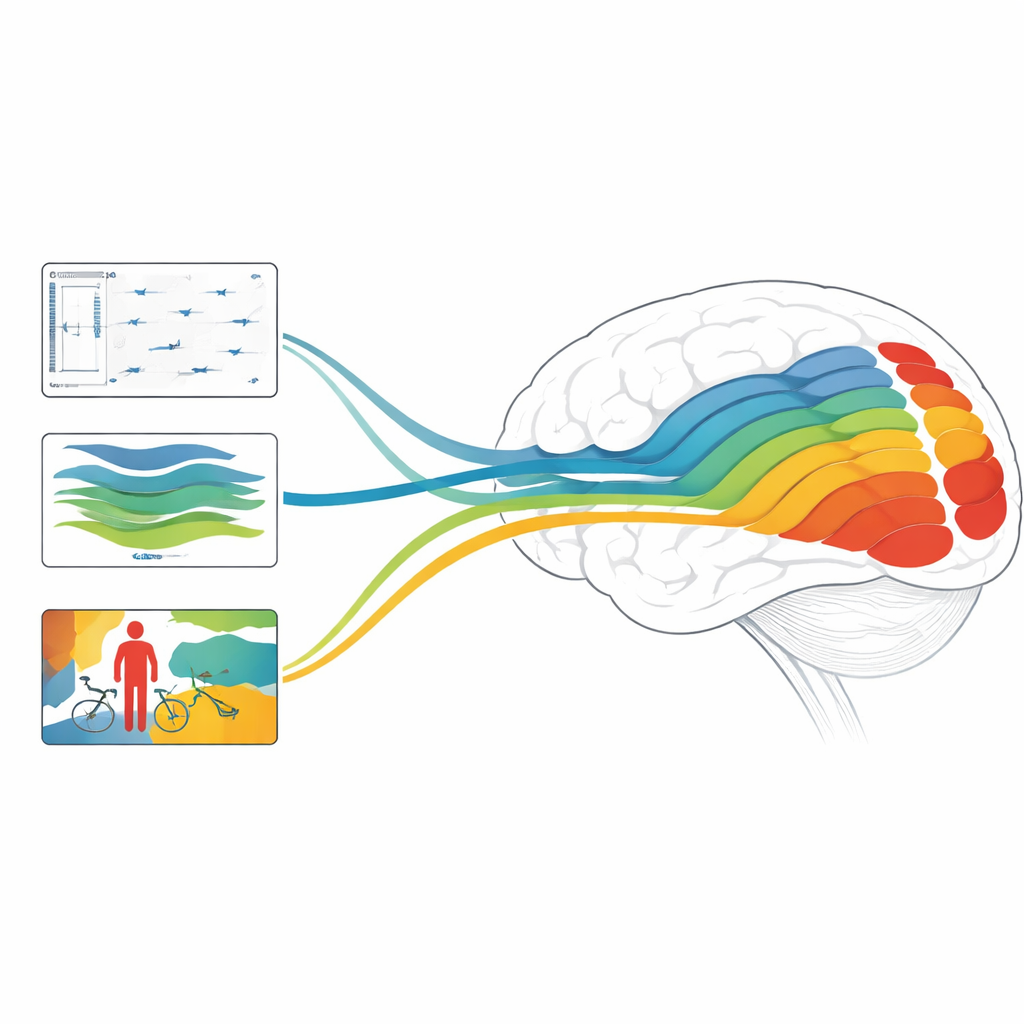
Почему это важно для мозга и машин
В целом исследование показывает, что модели глубины, движения и ориентированные на объекты согласуются с разными стадиями визуальной системы, и что комбинации моделей, предназначенные для работы со статической структурой и быстрыми динамиками, могут достигать передовой точности в предсказании реакций мозга. Для непрофессионального читателя главный вывод таков: современный ИИ делает не просто имитацию нашей способности маркировать изображения — его внутренние механизмы начинают отражать многослойные вычисления человеческого зрения. Разбирая, какие задачи и архитектуры лучше всего соответствуют разным областям мозга, эта работа указывает путь к будущим системам ИИ, которые видят мир более подобно нам, — и к новым методам исследования того, как наши собственные мозги превращают шумный, движущийся поток пикселей в богатый, трехмерный и содержательный опыт.
Цитирование: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Ключевые слова: нейронное кодирование, зрительная кора, понимание видео, глубокое обучение, движение и глубина