Clear Sky Science · pt
Compreensão a nível de pixel de um mundo em movimento dentro de um quadro de codificação neural
Observando o Mundo em Movimento, Um Pixel de Cada Vez
A cada segundo, seus olhos e cérebro trabalham juntos para transformar um fluxo de pixels em mudança em um mundo estável e significativo de pessoas, objetos e ações. Ao mesmo tempo, sistemas de inteligência artificial aprendem a fazer algo semelhante ao processar imagens e vídeos. Este artigo faz uma pergunta simples, mas poderosa: quando computadores analisam movimento, profundidade e objetos em vídeo, seu funcionamento interno se assemelha a como o cérebro humano responde às mesmas cenas?
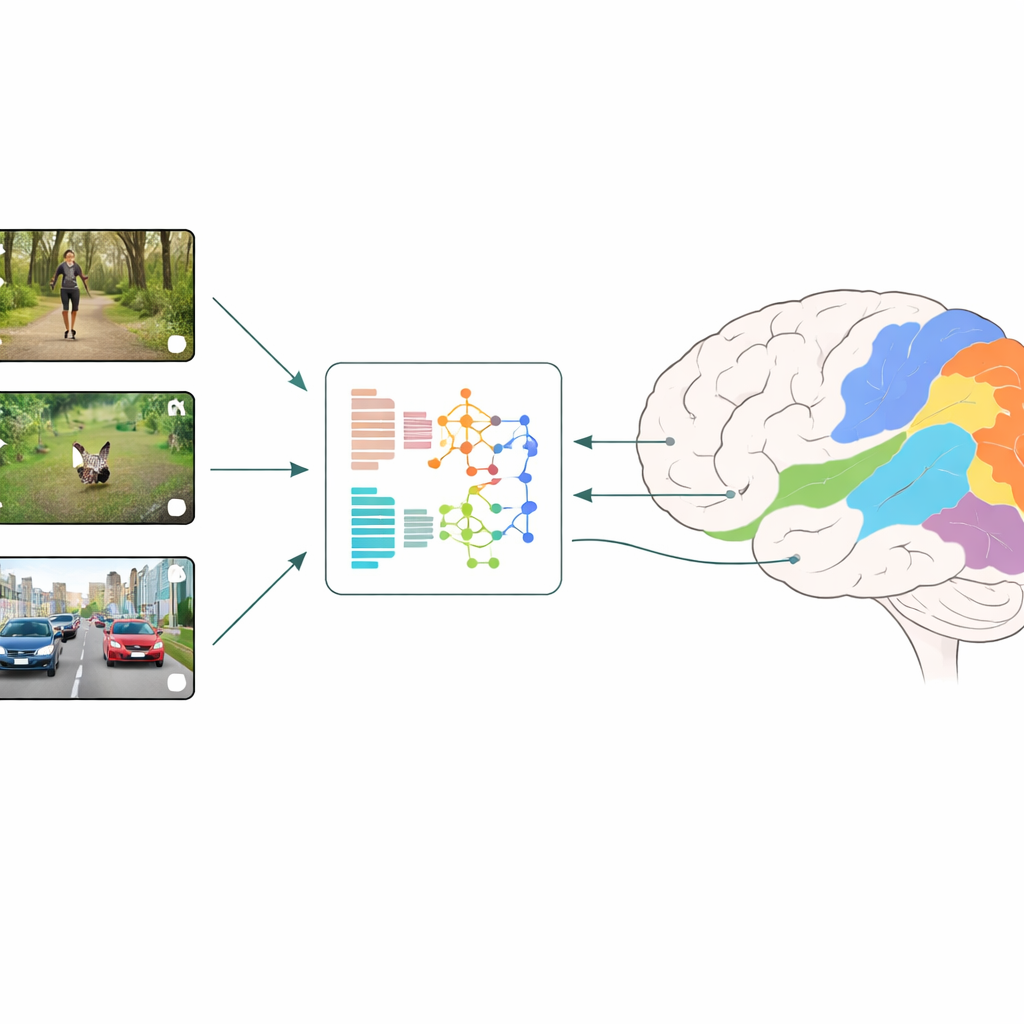
Como Cérebros e Máquinas São Comparados
Os pesquisadores usam uma estratégia chamada codificação neural: eles mostram às pessoas pequenos clipes de vídeo do cotidiano enquanto medem a atividade em muitas pequenas áreas do córtex visual com fMRI. Em paralelo, alimentam exatamente os mesmos vídeos em diferentes modelos de aprendizado profundo e extraem as características internas dos modelos em cada camada. Um modelo de regressão então aprende como combinar essas características artificiais para melhor prever as respostas medidas no cérebro, região por região. Comparando quais modelos e quais camadas dão as melhores previsões, a equipe pode inferir que tipos de cálculos visuais espelham mais de perto o que ocorre nas fases iniciais e posteriores da visão humana.
Tarefas a Nível de Pixel Versus Compreensão da Imagem Inteira
O estudo foca em três tarefas “a nível de pixel” que fazem uma previsão para cada pixel: fluxo óptico (como cada pixel se move de um quadro para outro), profundidade (quão distante cada pixel está do observador) e segmentação semântica (a que objeto ou parte do corpo cada pixel pertence). Estas são contrastadas com tarefas “grossas” que produzem apenas um rótulo por imagem ou vídeo, como reconhecimento de objetos e reconhecimento de ações. Algumas dessas tarefas são agnósticas a classes, como fluxo óptico e profundidade, que se importam apenas com movimento ou distância, não com categorias de objetos. Outras são sensíveis a classes, como reconhecimento de objetos e ações e segmentação semântica, que aprendem diretamente sobre objetos, cenas, corpos e ações.
O Que Movimento e Profundidade Revelam Sobre a Visão
Quando os autores comparam modelos, emerge um padrão claro. Modelos de fluxo óptico são melhores em prever a atividade nas regiões visuais iniciais e intermediárias, que são conhecidas por responder fortemente a bordas, movimento local e padrões simples. No entanto, esses modelos de movimento têm desempenho relativamente fraco em regiões posteriores que se preocupam mais com objetos, rostos e cenas. Modelos de estimativa de profundidade contam uma história diferente: eles prevêem bem as respostas não apenas em regiões iniciais, mas também em áreas de nível mais alto ao longo tanto da via visual do “onde” (dorsal) quanto da do “o quê” (ventral). Isso sugere que, mesmo sem treinamento explícito em categorias de objetos, modelos de profundidade aprendem representações internas que carregam informações surpreendentemente ricas sobre objetos e pessoas na cena.
Camadas, Estilos de Aprendizado e Regiões Cerebrais
Em muitas famílias de modelos, camadas iniciais tendem a corresponder melhor às regiões visuais iniciais, enquanto camadas posteriores correspondem melhor às regiões de nível superior, ecoando a hierarquia conhecida no cérebro. Redes convolucionais geralmente superam redes baseadas em transformadores na previsão do córtex visual inicial e intermediário, provavelmente porque convoluções capturam naturalmente detalhes finos e de alta frequência semelhantes aos importantes nas primeiras etapas da visão. Uma reviravolta importante é que modelos sensíveis a classes — aqueles treinados para nomear objetos, cenas ou ações — têm camadas de saída muito informativas que predizem fortemente áreas visuais tardias. Em contraste, para tarefas agnósticas a classes como movimento e profundidade, as saídas finais importam menos; em vez disso, camadas intermediárias oferecem a correspondência mais forte com as respostas cerebrais, especialmente para profundidade. Surpreendentemente, ao usar a mesma espinha dorsal subjacente, modelos de reconhecimento de objetos da imagem inteira capturam melhor a atividade cerebral do que a segmentação semântica pixel a pixel, sugerindo que uma visão global da cena é crucial para representações similares às do cérebro.
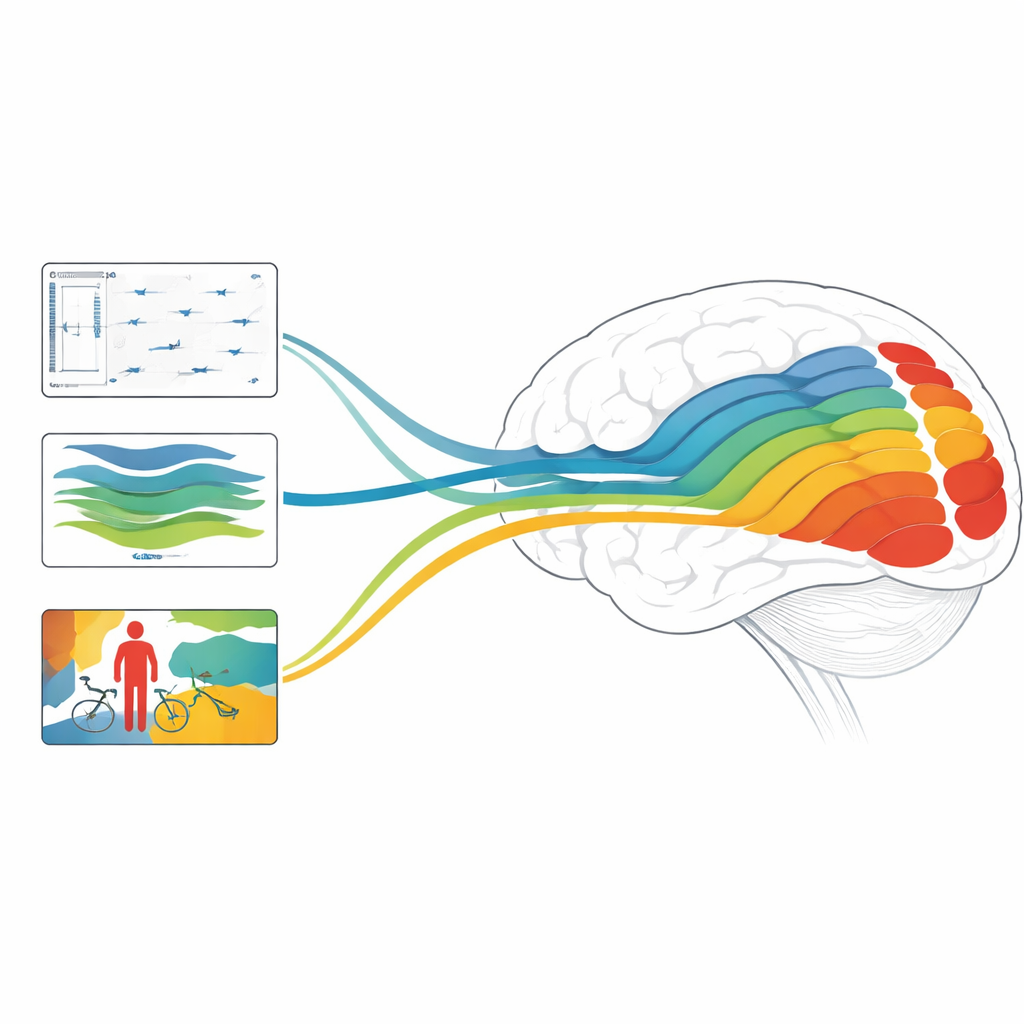
Por Que Isso Importa para Cérebros e Máquinas
No geral, o estudo mostra que modelos focados em profundidade, movimento e objetos se alinham a diferentes estágios do sistema visual, e que combinações de modelos projetados para lidar tanto com estrutura estática quanto com dinâmicas rápidas podem alcançar precisão de ponta na previsão das respostas cerebrais. Para um leitor leigo, a mensagem chave é que a IA moderna faz mais do que apenas imitar nossa habilidade de rotular imagens: seu funcionamento interno começa a refletir os cálculos em camadas da visão humana. Ao discernir quais tarefas e arquiteturas melhor espelham diferentes regiões cerebrais, este trabalho aponta para futuros sistemas de IA que veem o mundo mais como nós — e para novas maneiras de sondar como nossos próprios cérebros transformam um fluxo zumbidente de pixels em movimento em uma experiência rica, tridimensional e com significado.
Citação: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Palavras-chave: codificação neural, córtex visual, compreensão de vídeo, aprendizado profundo, movimento e profundidade