Clear Sky Science · it
Comprensione a livello di pixel di un mondo in movimento all'interno di un quadro di codifica neurale
Osservare il mondo in movimento, un pixel alla volta
Ogni secondo, occhi e cervello collaborano per trasformare un flusso di pixel in continuo cambiamento in un mondo stabile e significativo di persone, oggetti e azioni. Allo stesso tempo, i sistemi di intelligenza artificiale imparano a fare qualcosa di simile quando elaborano immagini e video. Questo articolo pone una domanda semplice ma incisiva: quando i computer analizzano movimento, profondità e oggetti nei video, il loro funzionamento interno somiglia a come il cervello umano risponde alle stesse scene?
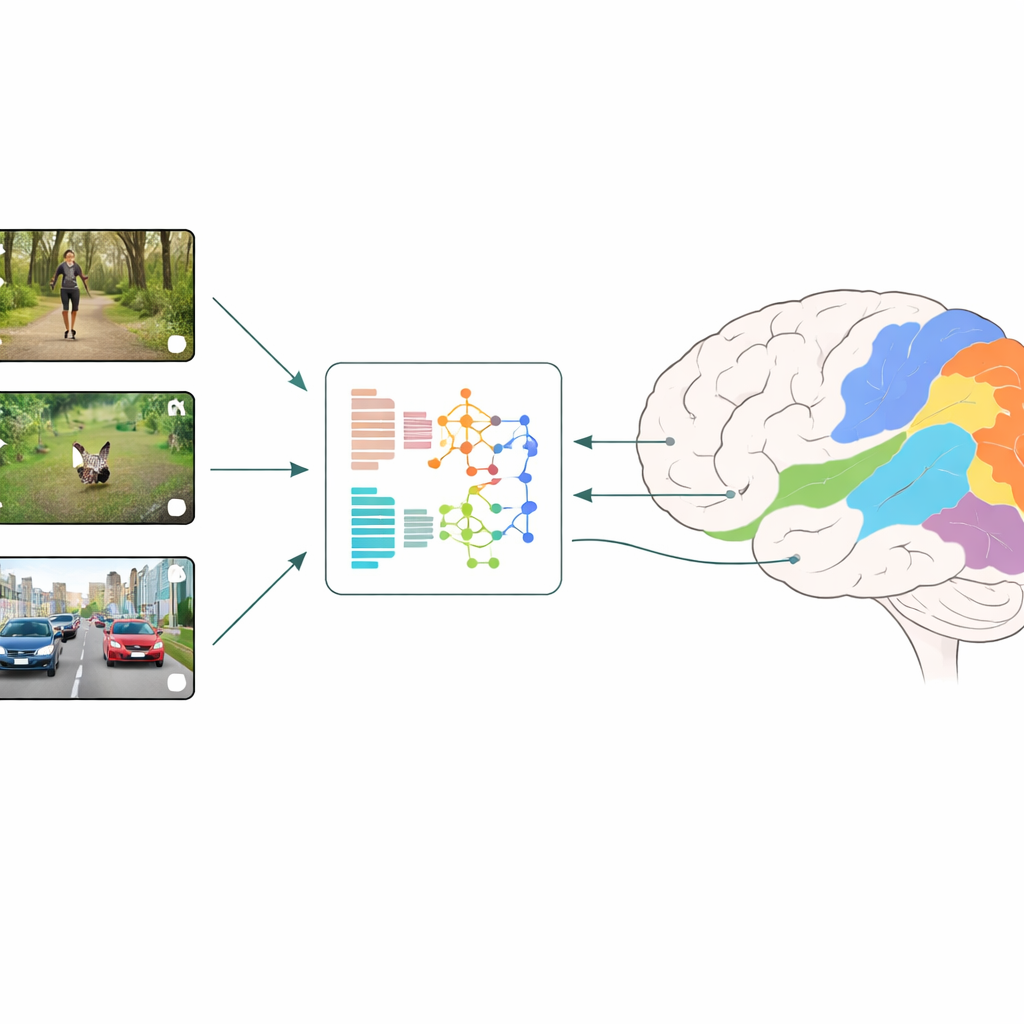
Come vengono confrontati cervelli e macchine
I ricercatori adottano una strategia chiamata codifica neurale: mostrano a persone brevi clip video quotidiane mentre misurano l'attività su molte piccole porzioni della corteccia visiva con fMRI. In parallelo, inseriscono gli stessi video in diversi modelli di deep learning e leggono le caratteristiche interne dei modelli a ogni livello. Un modello di regressione impara quindi a combinare queste caratteristiche artificiali per prevedere al meglio le risposte misurate nel cervello, regione per regione. Confrontando quali modelli e quali livelli offrono le migliori predizioni, il team può dedurre quali tipi di calcolo visivo si avvicinano maggiormente a quanto avviene nelle fasi iniziali e successive della visione umana.
Compiti a livello di pixel versus comprensione dell'immagine intera
Lo studio si concentra su tre compiti «a livello di pixel» che forniscono una previsione per ogni pixel: optical flow (come si muove ogni pixel da un fotogramma al successivo), profondità (a che distanza è ogni pixel dall'osservatore) e segmentazione semantica (a quale oggetto o parte del corpo appartiene ciascun pixel). Questi sono messi a confronto con compiti «grossolani» che producono una sola etichetta per immagine o video, come il riconoscimento degli oggetti e delle azioni. Alcuni di questi compiti sono agnostici rispetto alle classi, come optical flow e profondità, che si interessano solo del movimento o della distanza, non delle categorie di oggetti. Altri sono consapevoli delle classi, come il riconoscimento di oggetti e azioni e la segmentazione semantica, che apprendono direttamente informazioni su oggetti, scene, corpi e azioni.
Cosa rivelano movimento e profondità sulla visione
Quando gli autori confrontano i modelli emerge un quadro chiaro. I modelli di optical flow sono i migliori nel prevedere l'attività nelle regioni visive iniziali e medie, note per rispondere fortemente a bordi, movimento locale e schemi semplici. Tuttavia, questi modelli di movimento mostrano prestazioni relativamente scarse nelle regioni successive più sensibili a oggetti, volti e scene. I modelli di stima della profondità raccontano invece una storia diversa: prevedono bene le risposte non solo nelle regioni iniziali, ma anche in aree di livello superiore lungo sia la via visiva del “dove” (dorsale) sia quella del “cosa” (ventrale). Questo suggerisce che, anche senza essere esplicitamente addestrati su categorie di oggetti, i modelli di profondità apprendono rappresentazioni interne che trasportano informazioni sorprendentemente ricche su oggetti e persone nella scena.
Strati, stili di apprendimento e regioni cerebrali
Tra molte famiglie di modelli, gli strati iniziali tendono a corrispondere meglio alle regioni visive iniziali, mentre gli strati più profondi corrispondono meglio alle regioni di livello superiore, riecheggiando la gerarchia nota del cervello. Le reti convoluzionali generalmente sovraperformano le reti basate su transformer nel prevedere la corteccia visiva iniziale e media, probabilmente perché le convoluzioni catturano naturalmente dettagli fini e ad alta frequenza simili a quelli importanti nelle prime fasi della visione. Un elemento importante è che i modelli sensibili alle classi—quelli addestrati a nominare oggetti, scene o azioni—hanno strati di output molto informativi che prevedono con forza le aree visive tardive. Al contrario, per compiti agnostici rispetto alle classi come movimento e profondità, gli output finali contano meno; sono piuttosto gli strati intermedi a offrire la corrispondenza più forte con le risposte cerebrali, specialmente per la profondità. Sorprendentemente, usando lo stesso backbone sottostante, i modelli di riconoscimento di oggetti sull'immagine intera catturano meglio l'attività cerebrale rispetto alla segmentazione semantica pixel-per-pixel, suggerendo che una visione globale della scena sia cruciale per rappresentazioni simili a quelle del cervello.
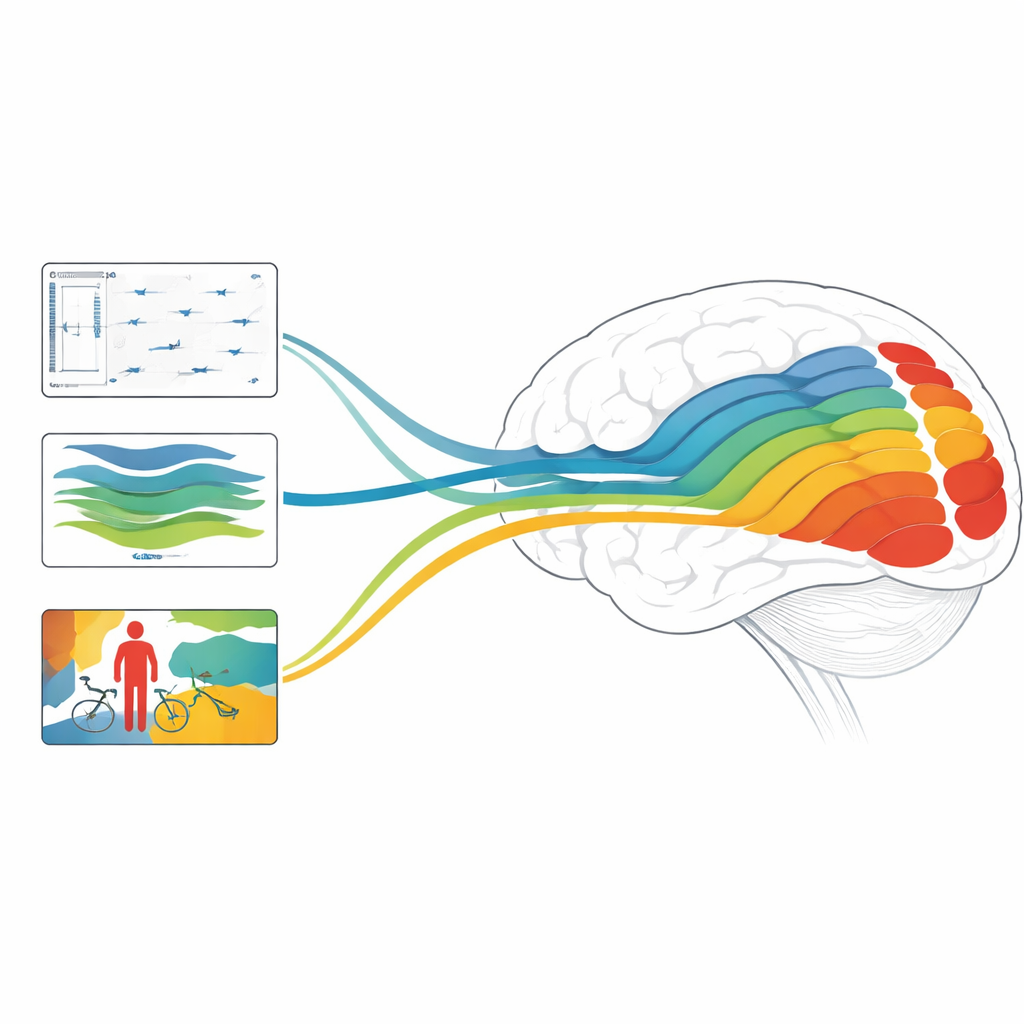
Perché è importante per cervelli e macchine
Nel complesso, lo studio mostra che modelli focalizzati su profondità, movimento e oggetti si allineano ciascuno con stadi differenti del sistema visivo, e che combinazioni di modelli progettati per gestire sia la struttura statica sia le dinamiche rapide possono raggiungere livelli di accuratezza all'avanguardia nella previsione delle risposte cerebrali. Per il lettore non specialistico, il messaggio chiave è che l'IA moderna fa più che imitare la nostra capacità di etichettare le immagini: il suo funzionamento interno inizia a riflettere i calcoli stratificati della visione umana. Separando quali compiti e architetture rispecchiano meglio diverse regioni cerebrali, questo lavoro indica la strada verso sistemi di IA che vedono il mondo più come noi—e verso nuovi modi di sondare come i nostri cervelli trasformano un flusso ronzante e in movimento di pixel in un'esperienza ricca, tridimensionale e significativa.
Citazione: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Parole chiave: codifica neurale, corteccia visiva, comprensione dei video, apprendimento profondo, moto e profondità