Clear Sky Science · tr
Piksel düzeyinde hareket halindeki bir dünyayı sinirsel kodlama çerçevesinde anlama
Hareket Halindeki Dünyayı Birer Piksel Olarak İzlemek
Her saniye, gözleriniz ve beyniniz değişen pikseller selini birlikte işleyerek insanları, nesneleri ve eylemleri içeren kararlı ve anlamlı bir dünya oluşturur. Aynı zamanda yapay zeka sistemleri de görüntüleri ve videoları işlerken benzer bir şeyi öğreniyor. Bu makale basit ama güçlü bir soru soruyor: Bilgisayarlar videodaki hareketi, derinliği ve nesneleri analiz ettiğinde, iç işleyişleri aynı sahnelere insan beyninin verdiği tepkilere benziyor mu?
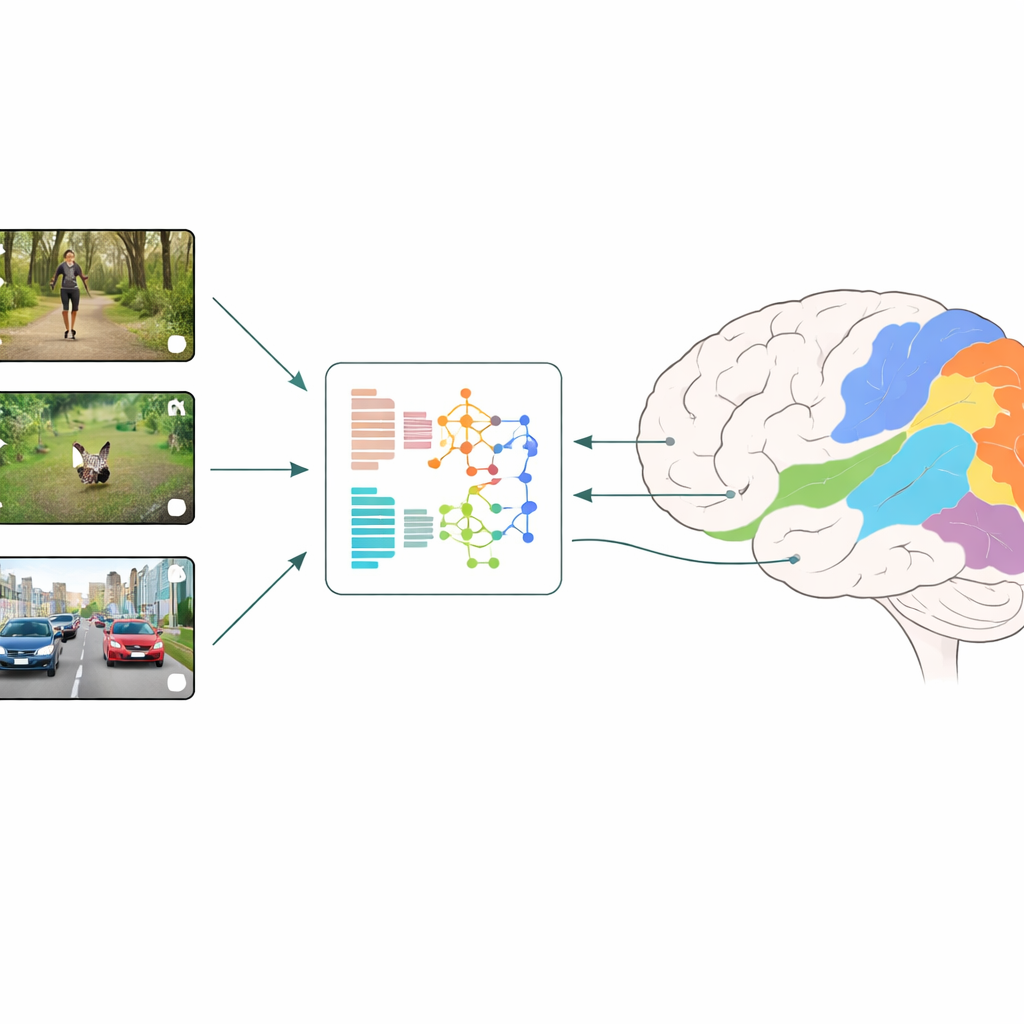
Beyinler ve Makineler Nasıl Karşılaştırılıyor
Araştırmacılar sinirsel kodlama adını verdikleri bir strateji kullanıyor: insanlara kısa, gündelik video klipleri gösterirken fMRI ile görsel korteksin çok sayıda küçük bölgesindeki etkinliği ölçüyorlar. Aynı videoları farklı derin öğrenme modellerine besliyor ve modellerin her katmandaki içsel özelliklerini okuyorlar. Bir regresyon modeli daha sonra bu yapay özellikleri bölge bölge beynin ölçülen tepkilerini en iyi şekilde tahmin etmek için nasıl birleştireceğini öğreniyor. Hangi model ve hangi katmanların en iyi tahminleri verdiğini karşılaştırarak ekip, hangi tür görsel hesaplamaların insan görselinin erken ve geç aşamalarında olup bitenleri en yakın şekilde yansıttığı hakkında çıkarımlar yapabiliyor.
Piksel Görevleri ve Tüm Görüntü Anlaması
Çalışma, her piksel için bir tahmin üreten üç "piksel düzeyinde" göreve odaklanıyor: optik akış (her pikselin kareden kareye nasıl hareket ettiği), derinlik (her pikselin izleyiciden ne kadar uzakta olduğu) ve semantik segmentasyon (her pikselin hangi nesneye veya vücut parçasına ait olduğu). Bunlar, nesne tanıma ve eylem tanıma gibi görüntü veya video başına yalnızca tek bir etiket üreten "kaba" görevlerle karşılaştırılıyor. Bazı görevler sınıf-ayrılmazdır; örneğin optik akış ve derinlik yalnızca hareket veya mesafe ile ilgilenir, nesne kategorileriyle değil. Diğerleri ise sınıf-bilinçlidir; örneğin nesne ve eylem tanıma ile semantik segmentasyon doğrudan nesneler, sahneler, bedenler ve eylemler hakkında öğrenir.
Hareket ve Derinliğin Görüş Hakkında Ne Anlattığı
Yazarlar modelleri karşılaştırdığında belirgin bir desen ortaya çıkıyor. Optik akış modelleri, kenarlar, yerel hareket ve basit desenlere güçlü yanıt veren erken ve orta görsel bölgelerde etkinliği en iyi tahmin ediyor. Ancak bu hareket modelleri, nesneler, yüzler ve sahnelerle daha çok ilgilenen sonraki bölgelerde nispeten kötü performans gösteriyor. Derinlik tahmin modelleri ise farklı bir tablo çiziyor: sadece erken bölgelerde değil, hem "nerede" (dorsal) hem de "ne" (ventral) görsel yolları boyunca daha üst düzey alanlarda da yanıtları iyi tahmin ediyorlar. Bu, derinlik modellerinin nesne kategorileri üzerinde açıkça eğitilmemiş olsalar bile sahnedeki nesneler ve insanlar hakkında şaşırtıcı derecede zengin bilgiyi taşıyan iç temsil öğrenimleri edindiğini gösteriyor.
Katmanlar, Öğrenme Tarzları ve Beyin Bölgeleri
Birçok model ailesinde erken katmanlar genellikle erken görsel bölgelerle, daha sonraki katmanlar ise daha üst düzey bölgelerle en iyi eşleşmeyi gösteriyor; bu, beyindeki bilinen hiyerarşiyi yansıtıyor. Konvolüsyonel ağlar genellikle erken ve orta görsel korteksi tahmin etmede dönüştürücü tabanlı ağlardan daha iyi performans gösteriyor; muhtemelen konvolüsyonlar, görmenin ilk aşamalarında önemli olan ince, yüksek frekanslı ayrıntıları doğal olarak yakalıyor. Önemli bir nokta da sınıf-bilinçli modellerin—nesneleri, sahneleri veya eylemleri adlandırmak üzere eğitilmiş olanların—geç görsel alanları güçlü şekilde tahmin eden çok bilgilendirici çıktı katmanlarına sahip olması. Buna karşılık, hareket ve derinlik gibi sınıf-ayrılmaz görevlerde son çıktılar daha az önemli; bunun yerine ara katmanlar özellikle derinlik için beyin yanıtlarıyla en güçlü eşleşmeyi veriyor. Aynı temel yapıyı kullanırken, tüm görüntü nesne tanıma modellerinin piksel piksel semantik segmentasyondan daha iyi beyin etkinliğini yakalaması şaşırtıcı olabilir; bu da sahnenin küresel bir görüşünün beyne benzer temsiller için kritik olduğunu ima ediyor.
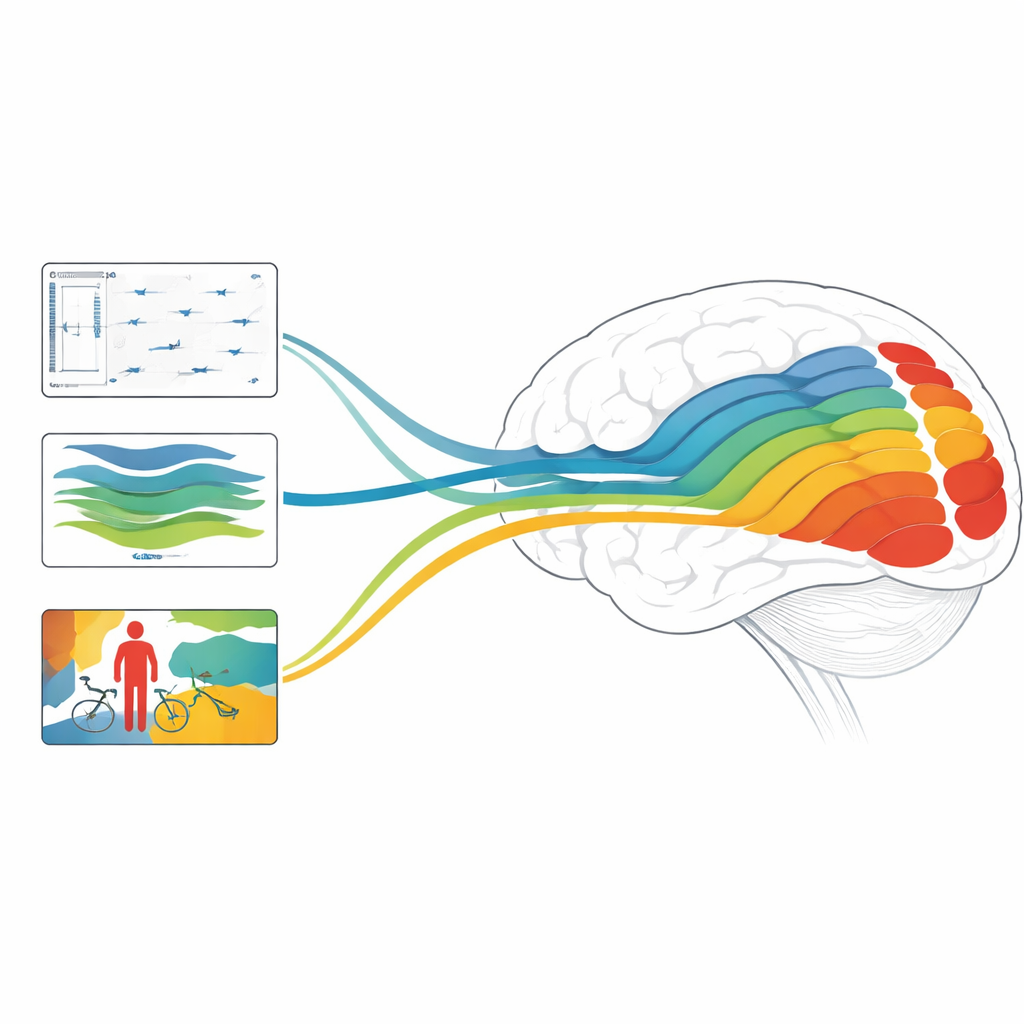
Bu Neden Beyinler ve Makineler İçin Önemli
Genel olarak çalışma, derinlik, hareket ve nesne odaklı modellerin görsel sistemin farklı aşamalarıyla hizalandığını ve hem statik yapıyı hem de hızlı dinamikleri ele alacak şekilde tasarlanmış model kombinasyonlarının beyin yanıtlarını tahmin etmede son teknoloji doğruluğuna ulaşabileceğini buluyor. Gayri uzman bir okuyucu için ana mesaj şu: modern yapay zeka sadece görüntü etiketleme yeteneğimizi taklit etmekle kalmıyor; içsel işleyişi insan görüşünün katmanlı hesaplamalarını yankılamaya başlıyor. Hangi görevlerin ve mimarilerin hangi beyin bölgelerini en iyi yansıttığını ayırarak, bu çalışma dünyayı bizim gördüğümüz şekilde daha çok gören gelecek yapay zeka sistemlerine ve kendi beynimizin vızıldayan, hareketli piksel akışını zengin, üç boyutlu ve anlamlı bir deneyime nasıl çevirdiğini sorgulamanın yeni yollarına işaret ediyor.
Atıf: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Anahtar kelimeler: sinirsel kodlama, görsel korteks, video anlama, derin öğrenme, hareket ve derinlik