Clear Sky Science · en
Pixel-level understanding of a world in motion within a neural encoding framework
Watching the Moving World, One Pixel at a Time
Every second, your eyes and brain work together to turn a flood of changing pixels into a stable, meaningful world of people, objects, and actions. At the same time, artificial intelligence systems are learning to do something similar when they process images and videos. This paper asks a simple but powerful question: when computers analyze motion, depth, and objects in video, do their internal workings resemble how the human brain responds to the same scenes?
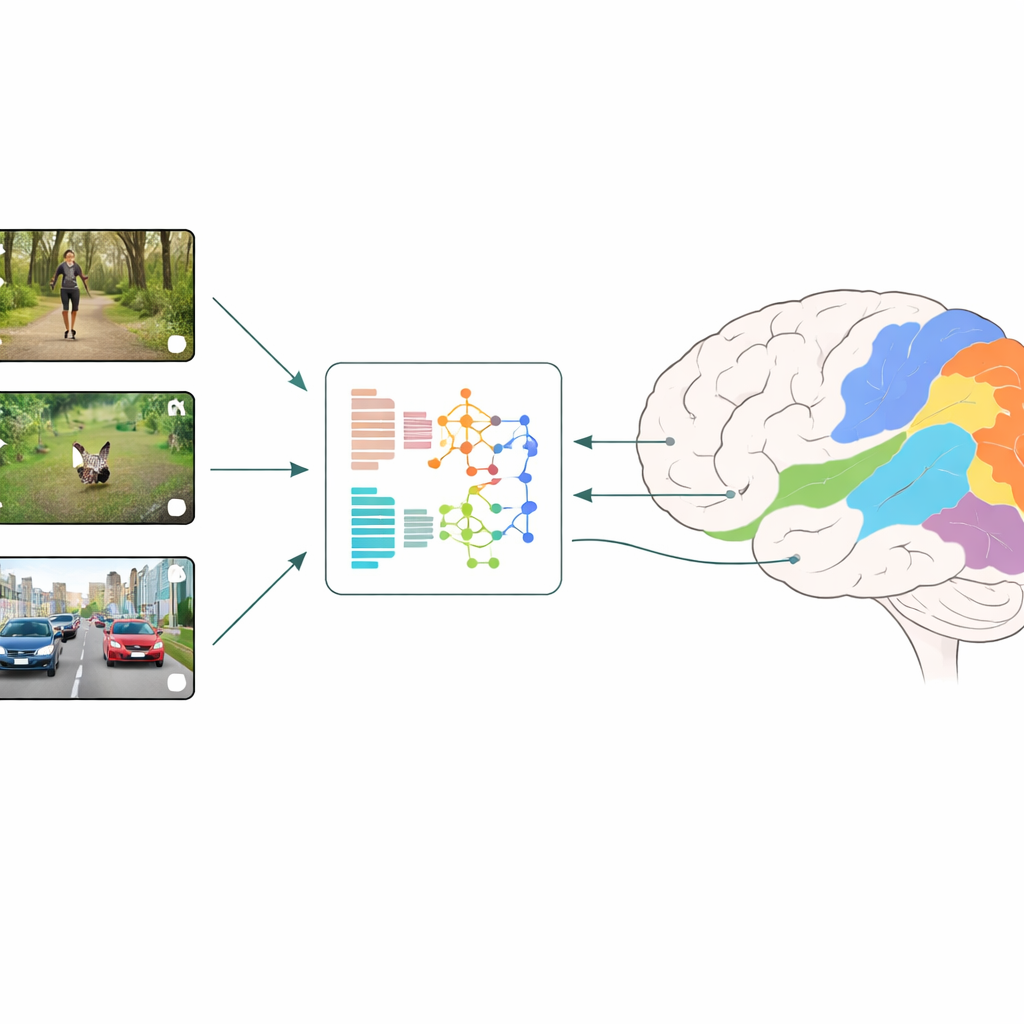
How Brains and Machines Are Compared
The researchers use a strategy called neural encoding: they show people short, everyday video clips while measuring activity across many small patches of the visual cortex with fMRI. In parallel, they feed the very same videos into different deep learning models and read out the models’ internal features at each layer. A regression model then learns how to combine these artificial features to best predict the brain’s measured responses, region by region. By comparing which models and which layers give the best predictions, the team can infer which types of visual computation most closely mirror what happens in early and later stages of human vision.
Pixel Tasks Versus Whole-Image Understanding
The study focuses on three “pixel-level” tasks that make a prediction for every pixel: optical flow (how each pixel moves from frame to frame), depth (how far each pixel is from the viewer), and semantic segmentation (which object or body part each pixel belongs to). These are contrasted with “coarse” tasks that output just a single label per image or video, such as object recognition and action recognition. Some of these tasks are class-agnostic, like optical flow and depth, which care only about motion or distance, not object categories. Others are class-aware, like object and action recognition and semantic segmentation, which directly learn about objects, scenes, bodies, and actions.
What Motion and Depth Reveal About Vision
When the authors compare models, a clear pattern emerges. Optical flow models are best at predicting activity in early and mid visual regions, which are known to respond strongly to edges, local motion, and simple patterns. However, these motion models perform relatively poorly in later regions that care more about objects, faces, and scenes. Depth estimation models tell a different story: they predict responses well not only in early regions, but also in higher-level areas along both the “where” (dorsal) and “what” (ventral) visual pathways. This suggests that, even without being explicitly trained on object categories, depth models learn internal representations that carry surprisingly rich information about objects and people in the scene.
Layers, Learning Styles, and Brain Regions
Across many model families, early layers tend to best match early visual regions, while later layers better match higher-level regions, echoing the known hierarchy in the brain. Convolutional networks generally outperform transformer-based networks in predicting early and mid visual cortex, likely because convolutions naturally pick up fine, high-frequency details similar to those important in the first stages of vision. An important twist is that class-aware models—those trained to name objects, scenes, or actions—have very informative output layers that strongly predict late visual areas. In contrast, for class-agnostic tasks like motion and depth, the final outputs matter less; instead, intermediate layers give the strongest match to brain responses, especially for depth. Surprisingly, when using the same underlying backbone, whole-image object recognition models better capture brain activity than pixel-by-pixel semantic segmentation, hinting that a global view of the scene is crucial for brain-like representations.
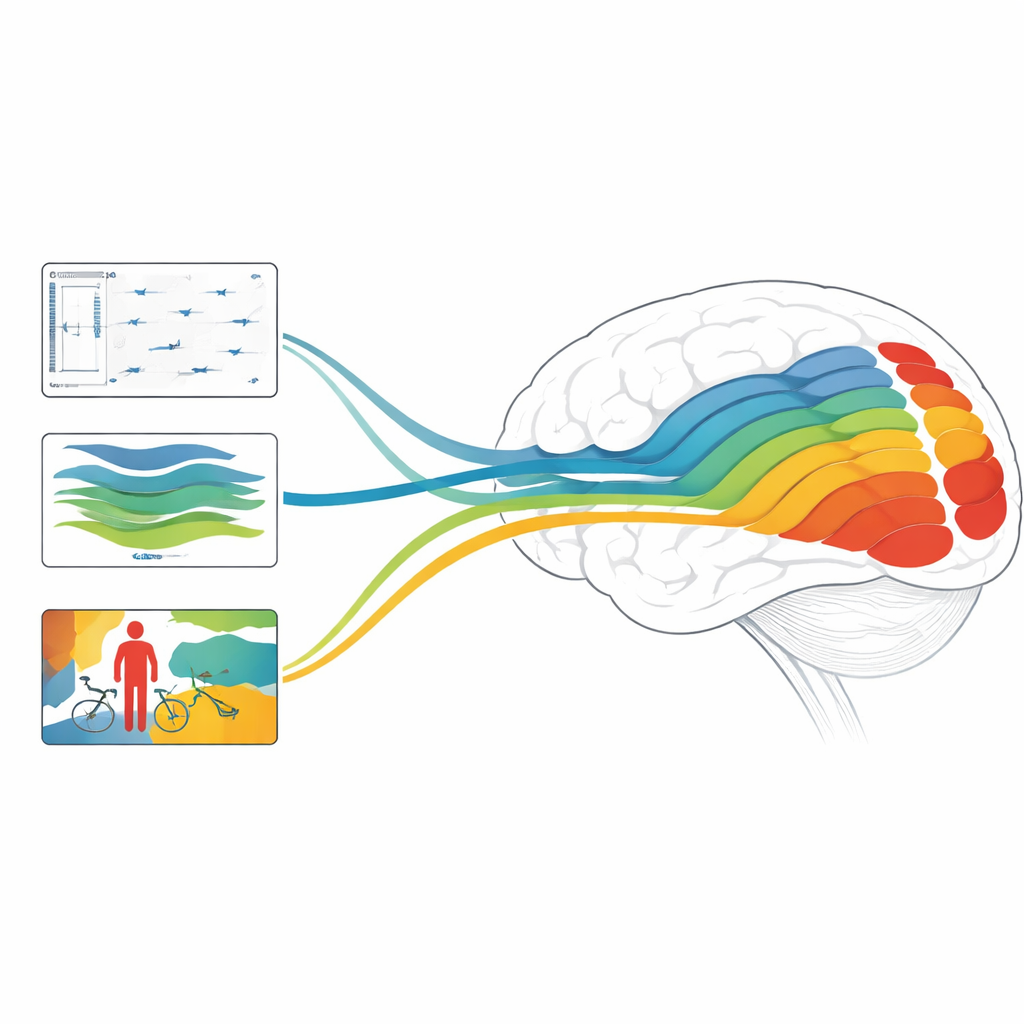
Why This Matters for Brains and Machines
Overall, the study finds that depth, motion, and object-focused models each align with different stages of the visual system, and that combinations of models designed to handle both static structure and fast dynamics can reach state-of-the-art accuracy in predicting brain responses. For a lay reader, the key message is that modern AI does more than just imitate our ability to label images: its internal workings are beginning to echo the layered computations of human vision. By teasing apart which tasks and architectures best mirror different brain regions, this work points toward future AI systems that see the world more like we do—and toward new ways of probing how our own brains turn a buzzing, moving pixel stream into a rich, three-dimensional, and meaningful experience.
Citation: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Keywords: neural encoding, visual cortex, video understanding, deep learning, motion and depth