Clear Sky Science · fr
Compréhension au niveau du pixel d’un monde en mouvement dans un cadre d’encodage neuronal
Observer le monde en mouvement, pixel par pixel
Chaque seconde, vos yeux et votre cerveau travaillent de concert pour transformer un flot de pixels changeants en un monde stable et signifiant de personnes, d’objets et d’actions. Dans le même temps, des systèmes d’intelligence artificielle apprennent à faire quelque chose de similaire lorsqu’ils traitent des images et des vidéos. Cet article pose une question simple mais puissante : lorsque les ordinateurs analysent le mouvement, la profondeur et les objets dans une vidéo, leurs mécanismes internes ressemblent-ils à la manière dont le cerveau humain répond aux mêmes scènes ?
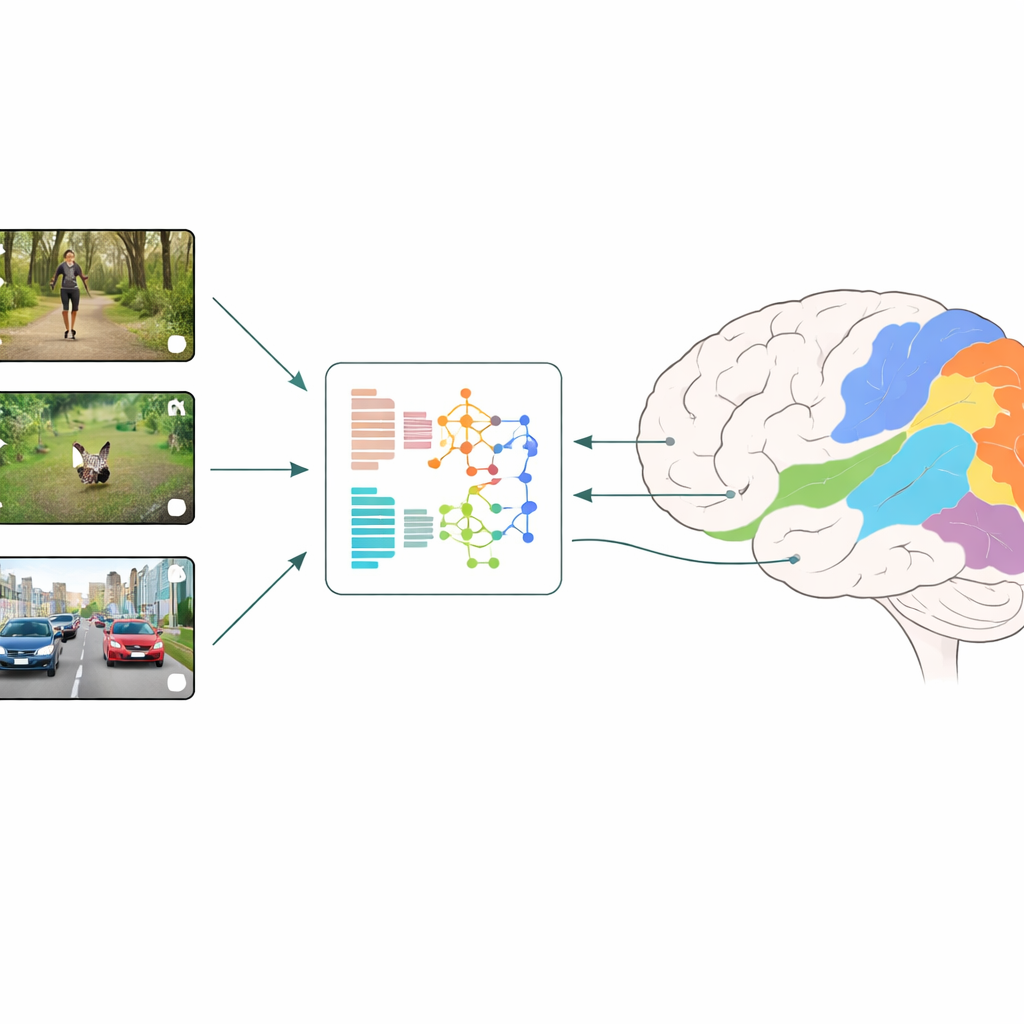
Comment on compare cerveaux et machines
Les chercheurs utilisent une stratégie appelée encodage neuronal : ils montrent à des personnes de courts extraits vidéo du quotidien tout en mesurant l’activité de nombreuses petites zones du cortex visuel avec l’IRMf. En parallèle, ils injectent les mêmes vidéos dans différents modèles d’apprentissage profond et extraient les caractéristiques internes de chaque couche. Un modèle de régression apprend ensuite à combiner ces caractéristiques artificielles pour mieux prédire les réponses mesurées du cerveau, région par région. En comparant quels modèles et quelles couches donnent les meilleures prédictions, l’équipe peut déduire quels types de calculs visuels reproduisent le plus fidèlement ce qui se passe dans les stades précoces et avancés de la vision humaine.
Tâches pixel par pixel versus compréhension de l’image entière
L’étude se concentre sur trois tâches « au niveau du pixel » qui fournissent une prédiction pour chaque pixel : le flux optique (comment chaque pixel se déplace d’une image à l’autre), la profondeur (à quelle distance chaque pixel se trouve de l’observateur) et la segmentation sémantique (à quel objet ou partie du corps appartient chaque pixel). Celles-ci sont comparées à des tâches « grossières » qui produisent une seule étiquette par image ou vidéo, comme la reconnaissance d’objets et la reconnaissance d’actions. Certaines de ces tâches sont indépendantes de la classe, comme le flux optique et la profondeur, qui s’intéressent uniquement au mouvement ou à la distance, pas aux catégories d’objets. D’autres sont sensibles aux classes, comme la reconnaissance d’objets et d’actions et la segmentation sémantique, qui apprennent directement sur les objets, les scènes, les corps et les actions.
Ce que le mouvement et la profondeur révèlent sur la vision
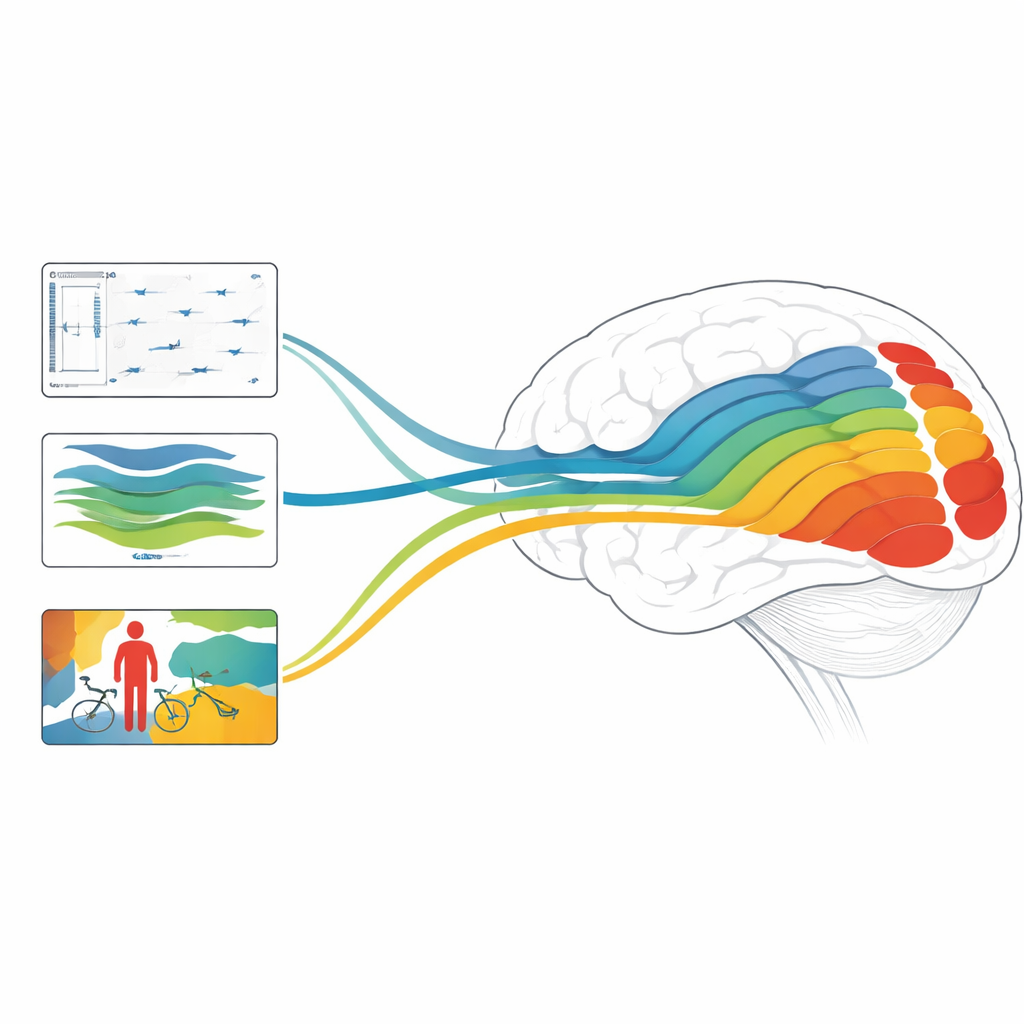
Lorsque les auteurs comparent les modèles, un schéma clair émerge. Les modèles de flux optique prédisent le mieux l’activité des régions visuelles précoces et intermédiaires, connues pour répondre fortement aux contours, aux mouvements locaux et aux motifs simples. En revanche, ces modèles de mouvement obtiennent de moins bons résultats dans les régions tardives qui s’intéressent davantage aux objets, aux visages et aux scènes. Les modèles d’estimation de la profondeur racontent une histoire différente : ils prédisent bien les réponses non seulement dans les régions précoces, mais aussi dans des zones de plus haut niveau le long des voies visuelles « où » (dorsale) et « quoi » (ventrale). Cela suggère que, même sans entraînement explicite sur des catégories d’objets, les modèles de profondeur apprennent des représentations internes qui portent des informations étonnamment riches sur les objets et les personnes de la scène.
Couches, styles d’apprentissage et régions cérébrales
Dans de nombreuses familles de modèles, les couches précoces correspondent le mieux aux régions visuelles précoces, tandis que les couches tardives correspondent mieux aux régions de haut niveau, ce qui fait écho à la hiérarchie connue du cerveau. Les réseaux convolutionnels surpassent généralement les réseaux basés sur les transformers pour prédire le cortex visuel précoce et intermédiaire, probablement parce que les convolutions captent naturellement des détails fins et haute fréquence similaires à ceux importants dans les premiers stades de la vision. Une nuance importante est que les modèles sensibles aux classes — ceux entraînés à nommer des objets, des scènes ou des actions — ont des couches de sortie très informatives qui prédisent fortement les zones visuelles tardives. En revanche, pour les tâches indépendantes des classes comme le mouvement et la profondeur, les sorties finales comptent moins ; ce sont plutôt les couches intermédiaires qui offrent la meilleure correspondance avec les réponses cérébrales, en particulier pour la profondeur. De manière surprenante, en utilisant la même architecture de base, les modèles de reconnaissance d’objets sur l’image entière capturent mieux l’activité cérébrale que la segmentation sémantique pixel par pixel, ce qui suggère qu’une vue globale de la scène est cruciale pour des représentations proches de celles du cerveau.
Pourquoi cela importe pour les cerveaux et les machines
Globalement, l’étude montre que les modèles axés sur la profondeur, le mouvement et les objets s’alignent chacun sur des étapes différentes du système visuel, et que des combinaisons de modèles conçus pour gérer à la fois la structure statique et la dynamique rapide peuvent atteindre une précision de pointe pour prédire les réponses cérébrales. Pour un lecteur non spécialiste, le message clé est que l’IA moderne fait plus que simplement imiter notre capacité à étiqueter des images : ses mécanismes internes commencent à refléter les calculs en couches de la vision humaine. En isolant quelles tâches et architectures reproduisent le mieux les régions cérébrales, ce travail ouvre la voie à de futurs systèmes d’IA qui voient le monde de manière plus proche de la nôtre — et à de nouvelles façons d’explorer comment nos propres cerveaux transforment un flux bourdonnant et mobile de pixels en une expérience riche, tridimensionnelle et signifiante.
Citation: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Mots-clés: encodage neuronal, cortex visuel, compréhension vidéo, apprentissage profond, mouvement et profondeur