Clear Sky Science · ja
ニューラル符号化フレームワーク内での動く世界のピクセルレベルの理解
動く世界をピクセル単位で観る
毎秒、あなたの目と脳は協調して、変化する大量のピクセルを人や物、行動といった安定した意味ある世界へと変換しています。同時に、人工知能システムも画像やビデオを処理する際に似たことを学習しつつあります。本論文はシンプルだが強力な問いを投げかけます:コンピュータがビデオ内の動き、深度、物体を解析するとき、その内部の働きは同じシーンに対する人間の脳の応答と似ているのか?
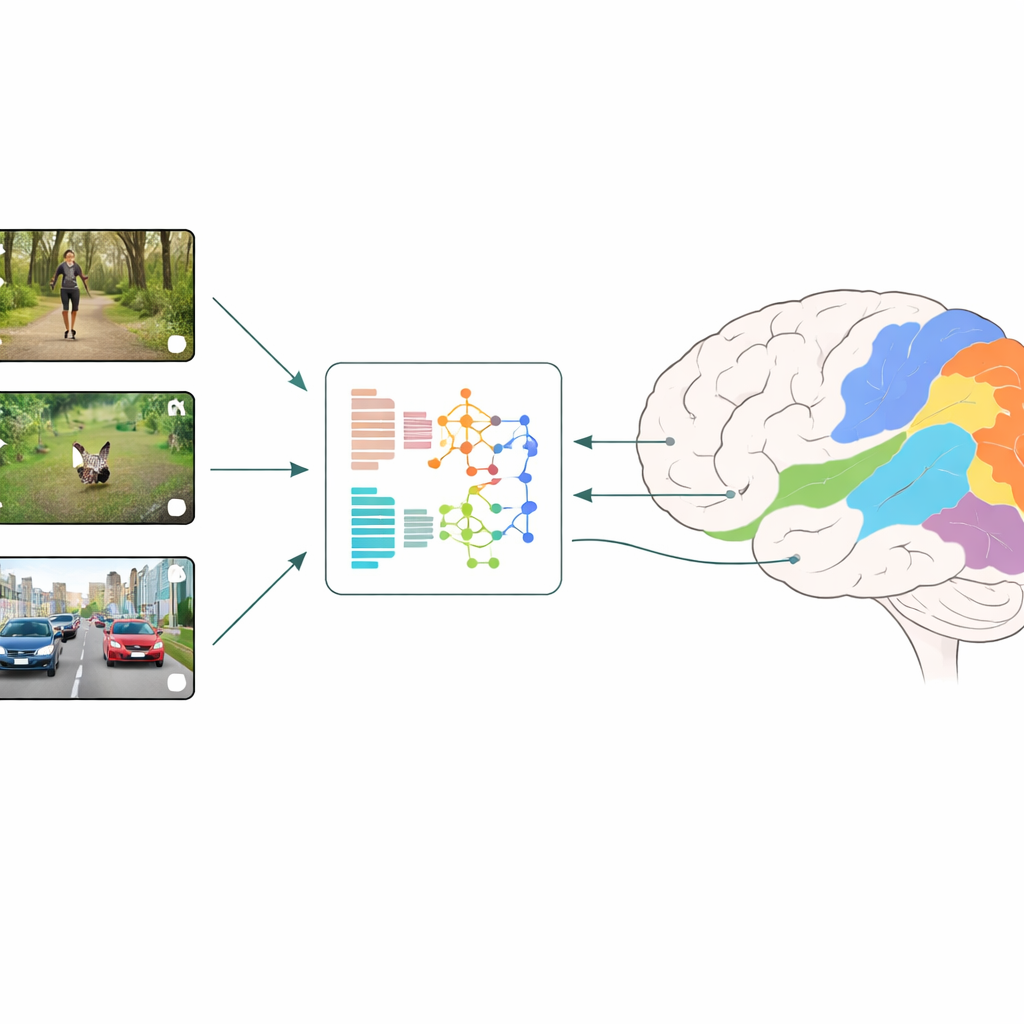
脳と機械をどう比較するか
研究者らは「ニューラル符号化」と呼ばれる手法を用います:被験者に日常的な短いビデオクリップを提示し、fMRIで視覚皮質の多くの小領域の活動を測定します。並行して、同じビデオを各種の深層学習モデルに入力し、各層の内部特徴を読み出します。回帰モデルがこれら人工特徴を組み合わせて領域ごとに脳の測定応答を最もよく予測する方法を学びます。どのモデルのどの層が最良の予測を与えるかを比較することで、初期および後期のヒト視覚で起きる処理に最も近い視覚計算の種類を推測できます。
ピクセルごとの課題と画像全体の理解
本研究は各ピクセルごとに予測を行う三つの「ピクセルレベル」課題に焦点を当てます:オプティカルフロー(各ピクセルがフレーム間でどう動くか)、深度(各ピクセルが観者からどれだけ離れているか)、意味的セグメンテーション(各ピクセルがどの物体や体の部位に属するか)。これらは、画像やビデオごとに単一ラベルを出力する「粗い」課題(物体認識や行動認識など)と対比されます。オプティカルフローや深度のような課題はクラス非依存で、動きや距離だけを扱い物体カテゴリを問わないのに対し、物体・行動認識や意味的セグメンテーションのようなクラス依存の課題は物体や場面、身体、行動に関する直接的な情報を学習します。
動きと深度が視覚について示すこと
モデルを比較すると明確なパターンが現れます。オプティカルフローモデルは、エッジや局所的な動き、単純なパターンに強く反応することで知られる初期および中間の視覚領域の活動を最もよく予測します。しかし、これらの動きモデルは物体や顔、場面により関心を持つ後期領域では比較的成績が悪いです。深度推定モデルは異なる物語を示します:深度モデルは初期領域だけでなく、「どこ」経路(背側)と「何」経路(腹側)に沿った高次領域でも応答をよく予測します。これは、物体カテゴリで明示的に訓練されていなくても、深度モデルが場面内の物体や人に関する驚くほど豊かな情報を内包する表現を学習することを示唆します。
層、学習スタイル、そして脳領域
多くのモデル群にわたって、初期の層は初期の視覚領域と最もよく一致し、後の層は高次領域とよりよく一致する傾向が見られ、これは脳に知られる階層性を反映しています。畳み込みネットワークは一般に、視覚皮質の初期および中間領域の予測において、トランスフォーマーベースのネットワークより優れています。これは畳み込みが視覚の初期段階で重要な細かい高周波の特徴を自然に捉えるためだと考えられます。重要なポイントは、クラス依存モデル(物体、場面、行動の名称を学習したモデル)は出力層が非常に情報量が多く、後期の視覚領域を強く予測することです。対照的に、動きや深度のようなクラス非依存課題では最終出力の重要性は小さく、中間層が脳応答と最も強く一致することが多く、特に深度ではその傾向が顕著です。驚くべきことに、同じバックボーンを用いた場合、画像全体の物体認識モデルはピクセル単位の意味的セグメンテーションよりも脳活動をよく捉えます。これは場面のグローバルな把握が脳に似た表現にとって重要であることを示唆します。
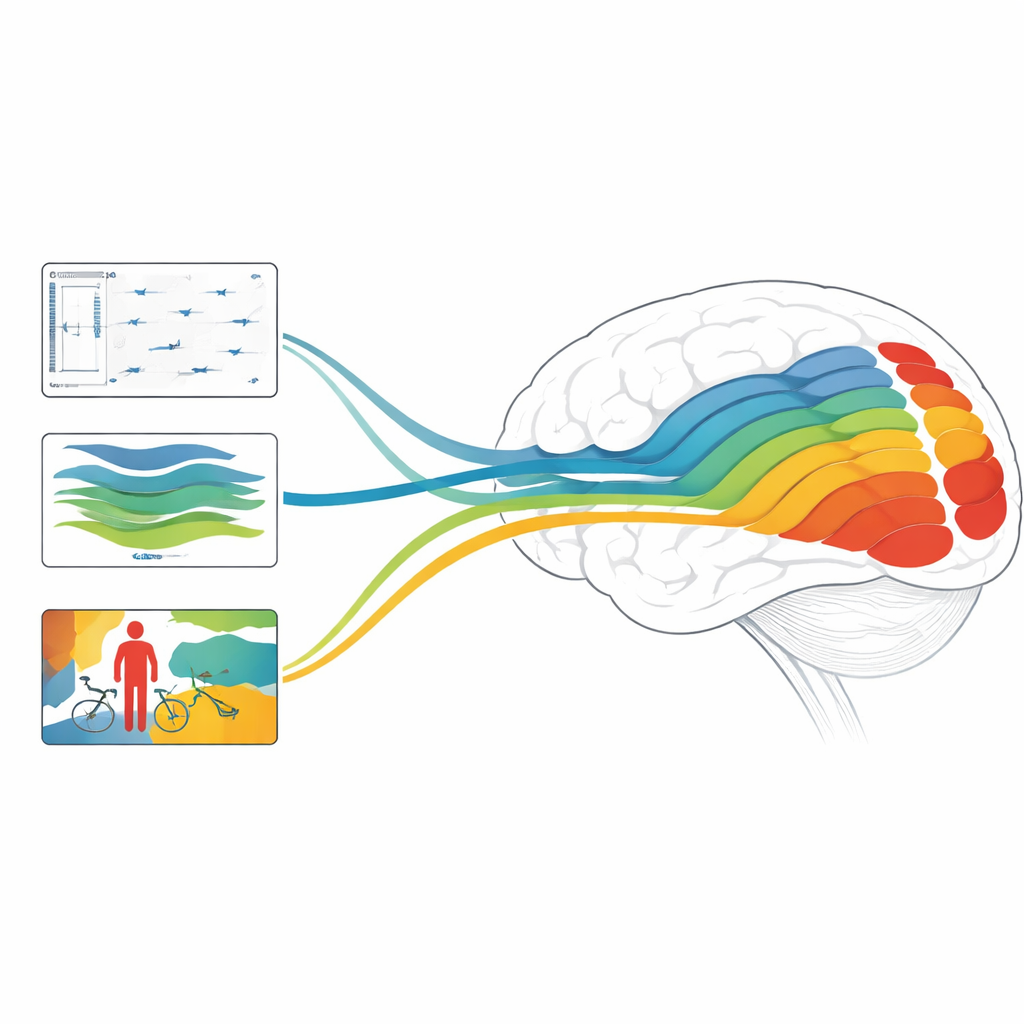
なぜこれは脳と機械にとって重要か
まとめると、本研究は深度、動き、物体に焦点を当てたモデルが視覚系の異なる段階とそれぞれ整合すること、静的構造と高速な動態の両方を扱えるモデルの組み合わせが脳応答予測で最先端の精度に達しうることを示します。一般向けの要点は、現代のAIは単に画像にラベルを付ける能力を模倣するだけでなく、その内部処理が人間の視覚の多層的な計算を反映し始めているということです。どの課題やアーキテクチャが異なる脳領域を最もよく鏡映するかを分解することで、この研究はAIが人間のように世界を見られる方向性と、騒がしく動くピクセル列をどのようにして豊かで立体的、意味深い体験に変えているかを探る新しい手段を示しています。
引用: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
キーワード: ニューラル符号化, 視覚皮質, ビデオ理解, 深層学習, 動きと深度