Clear Sky Science · ar
فهم على مستوى البكسل لعالم في حركة ضمن إطار ترميز عصبي
مراقبة العالم المتحرك بكسلًا بكسل
كل ثانية، تعمل عيناك ودماغك معًا لتحويل فيضان من البكسلات المتغيرة إلى عالم ثابت وذو معنى من أشخاص وأشياء وأفعال. في الوقت نفسه، تتعلم أنظمة الذكاء الاصطناعي أن تفعل شيئًا مشابهًا عند معالجة الصور ومقاطع الفيديو. تطرح هذه الورقة سؤالًا بسيطًا لكنه قوي: عندما تحلل الحواسيب الحركة والعمق والأجسام في الفيديو، هل تشبه آلياتها الداخلية كيفية استجابة الدماغ البشري للمشاهد نفسها؟
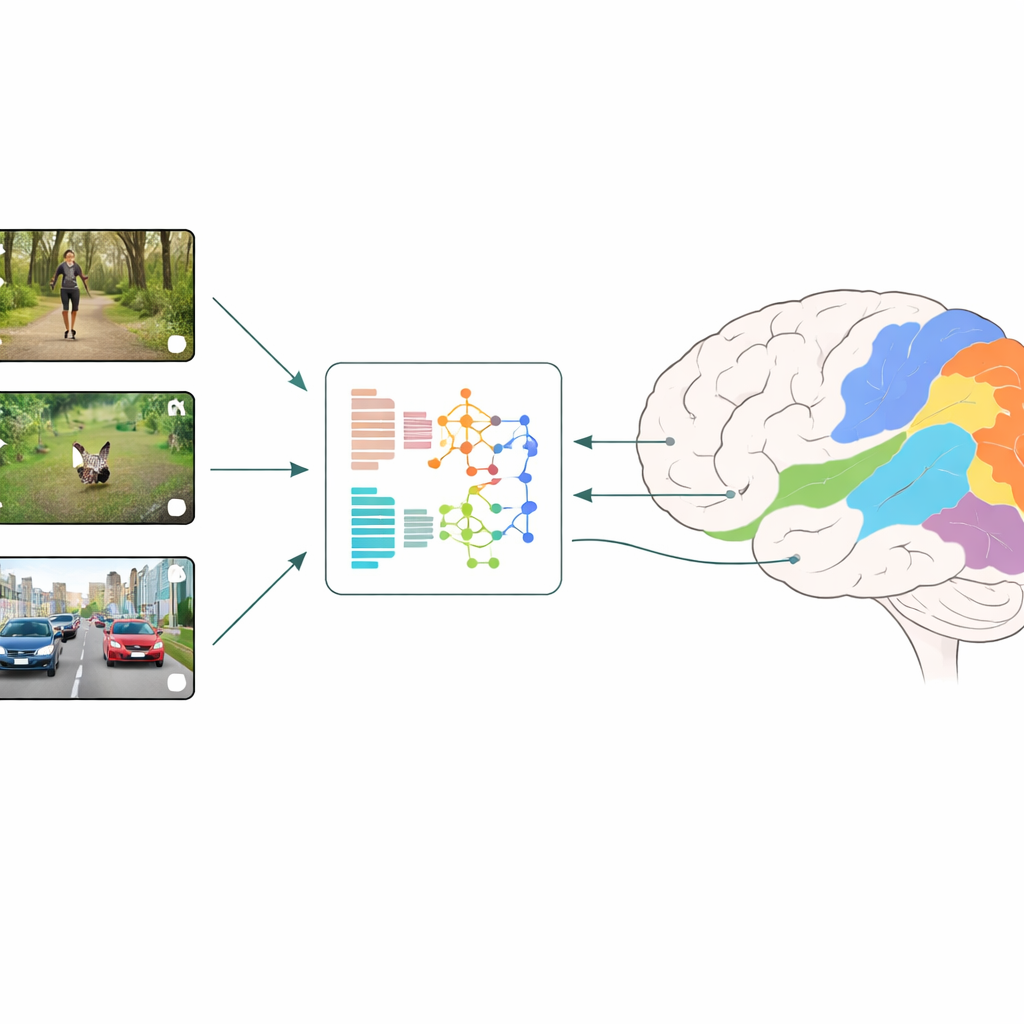
كيف تُقارن الأدمغة والآلات
يستخدم الباحثون استراتيجية تسمى الترميز العصبي: يعرضون على الأشخاص مقاطع فيديو قصيرة يومية بينما يقيسون النشاط عبر العديد من البقع الصغيرة في القشرة البصرية باستخدام تصوير الرنين المغناطيسي الوظيفي (fMRI). وبالتوازي، يدخلون نفس مقاطع الفيديو إلى نماذج تعلم عميق مختلفة ويقرأون الميزات الداخلية للنماذج على كل طبقة. ثم يتعلم نموذج انحدار كيفية دمج هذه الميزات الاصطناعية للتنبؤ بأفضل صورة باستجابات الدماغ المقاسة، منطقة بمنطقة. من خلال مقارنة النماذج والطبقات التي تعطي أفضل التنبؤات، يستطيع الفريق استنتاج أي أنواع الحسابات البصرية تحاكي بشكل أوثق ما يحدث في المراحل المبكرة والمتأخرة من الرؤية البشرية.
مهام على مستوى البكسل مقابل فهم الصورة الكاملة
تركز الدراسة على ثلاث مهام «على مستوى البكسل» تعطي تنبؤًا لكل بكسل: التدفق الضوئي (كيفية حركة كل بكسل من إطار إلى آخر)، والعمق (مدى بُعد كل بكسل عن المشاهد)، والتجزئة الدلالية (إلى أي كائن أو جزء من الجسم ينتمي كل بكسل). تُقارن هذه بمهام «خشنّة» تُنتج تسمية واحدة فقط لكل صورة أو فيديو، مثل تعرف الأشياء والتعرف على الأفعال. بعض هذه المهام غير معتمدة على الفئة، مثل التدفق الضوئي والعمق، التي تهمها الحركة أو المسافة فقط، لا فئات الكائنات. والبعض الآخر واعٍ بالفئات، مثل تعرف الأشياء والأفعال والتجزئة الدلالية، التي تتعلم مباشرة عن الأشياء والمشاهد والأجسام والأفعال.
ماذا تكشف الحركة والعمق عن الرؤية
عند مقارنة النماذج، يظهر نمط واضح. تنبؤات نماذج التدفق الضوئي هي الأفضل في توقع النشاط في المناطق البصرية المبكرة والمتوسطة، المعروفة باستجابتها القوية للحواف والحركة المحلية والأنماط البسيطة. ومع ذلك، تؤدي هذه النماذج الحركية أداءً أقل نسبيًا في المناطق المتأخرة التي تهتم أكثر بالأشياء والوجوه والمشاهد. تروي نماذج تقدير العمق قصة مختلفة: فهي تتنبأ بالاستجابات بشكل جيد ليس فقط في المناطق المبكرة، بل أيضًا في المناطق عالية المستوى على طول كلٍ من المسارين البصريين «أين» (الظهري) و«ما» (الحجابي). هذا يشير إلى أنه حتى دون تدريب صريح على فئات الكائنات، تتعلم نماذج العمق تمثيلات داخلية تحمل معلومات غنية بشكل مدهش عن الأجسام والأشخاص في المشهد.
الطبقات، أساليب التعلم، ومناطق الدماغ
عبر عائلات نماذج عديدة، تميل الطبقات المبكرة إلى التطابق الأفضل مع المناطق البصرية المبكرة، بينما تطابق الطبقات المتأخرة المناطق الأعلى مستوى، مما يعكس التسلسل الهرمي المعروف في الدماغ. تتفوق الشبكات الالتفافية عمومًا على الشبكات القائمة على المحولات في توقع القشرة البصرية المبكرة والمتوسطة، على الأرجح لأن العمليات الالتفافية تلتقط طبيعيًا التفاصيل الدقيقة وذات التردد العالي المشابهة لتلك المهمة في المراحل الأولى من الرؤية. لفتة مهمة هي أن النماذج الواعية بالفئات — تلك المدربة لتسمية الأشياء أو المشاهد أو الأفعال — تملك طبقات إخراج معلوماتية جدًا تتنبأ بقوة بالمناطق البصرية المتأخرة. بالمقابل، بالنسبة للمهام غير المعتمدة على الفئة مثل الحركة والعمق، لا تكون المخرجات النهائية مهمة بنفس القدر؛ بل تعطي الطبقات الوسيطة التطابق الأقوى مع استجابات الدماغ، لا سيما بالنسبة للعمق. ومن المدهش أنه عند استخدام نفس العمود الفقري الأساسي، تلتقط نماذج تعرف الأشياء للصورة الكاملة نشاط الدماغ أفضل من التجزئة الدلالية بكسلًا بكسل، مما يوحي بأن النظرة الكلية للمشهد حاسمة لتمثيلات شبيهة بالدماغ.
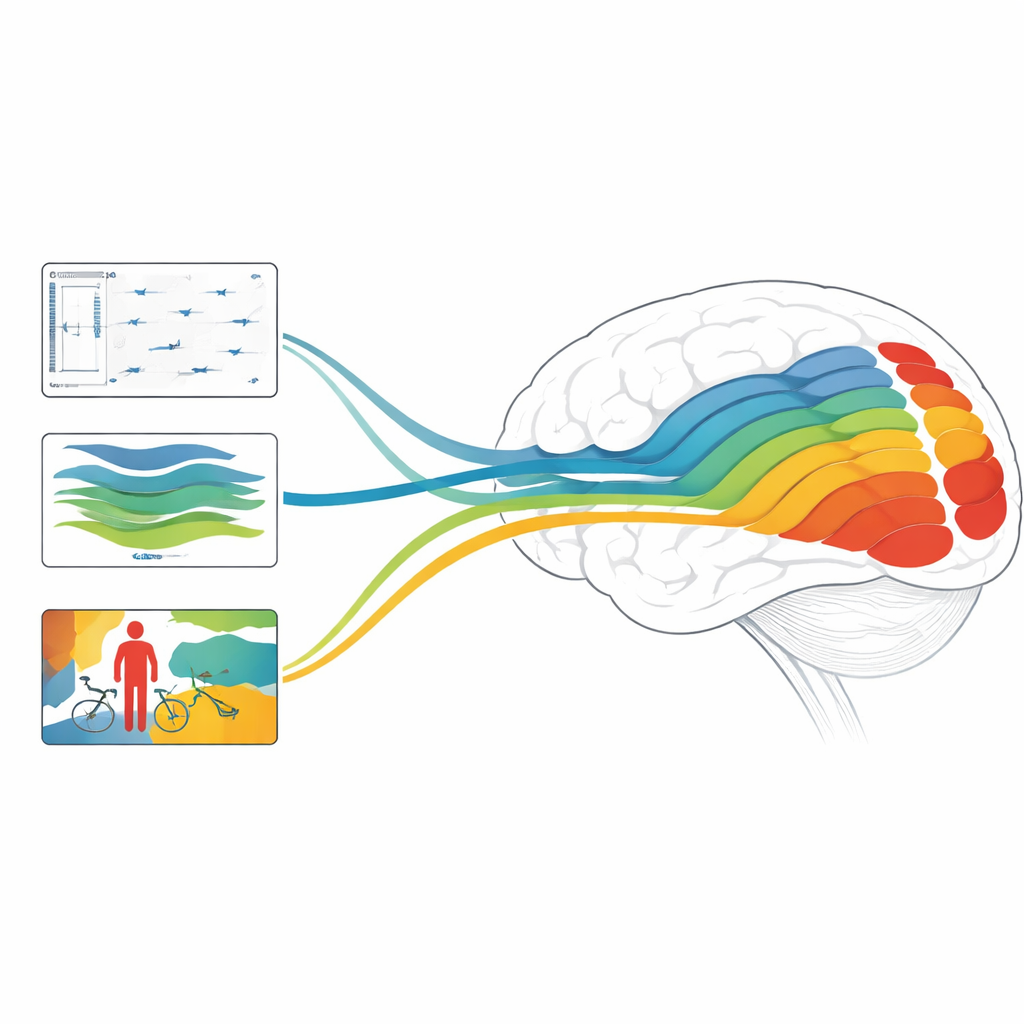
لماذا يهم هذا للدماغ والآلات
بشكل عام، تجد الدراسة أن نماذج العمق والحركة والنماذج الموجهة نحو الأشياء تتوافق كل واحدة مع مراحل مختلفة من النظام البصري، وأن مجموعات من النماذج المصممة للتعامل مع البنية الثابتة والديناميكيات السريعة يمكن أن تصل إلى دقة متقدمة في توقع استجابات الدماغ. للقراء غير المتخصصين، الرسالة الأساسية هي أن الذكاء الاصطناعي الحديث يفعل أكثر من مجرد تقليد قدرتنا على تسمية الصور: إن آلياته الداخلية بدأت تعكس حسابات متدرجة تشبه تلك في الرؤية البشرية. من خلال تفكيك أي المهام والهياكل المعمارية تحاكي أفضل مناطق الدماغ المختلفة، يشير هذا العمل نحو أنظمة ذكاء اصطناعي مستقبلية ترى العالم بشكل أقرب إلى رؤيتنا — وإلى طرق جديدة لفحص كيف يحول دماغنا نفسه تدفقًا صاخبًا من البكسلات المتحركة إلى تجربة غنية وثلاثية الأبعاد وذات مغزى.
الاستشهاد: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
الكلمات المفتاحية: الترميز العصبي, القشرة البصرية, فهم الفيديو, التعلم العميق, الحركة والعمق