Clear Sky Science · sv
Pixel‑nivåförståelse av en värld i rörelse inom en neuralt kodningsram
Att betrakta en rörlig värld, en pixel i taget
Varje sekund samarbetar dina ögon och din hjärna för att förvandla en ström av föränderliga pixlar till en stabil, meningsfull värld av människor, föremål och handlingar. Samtidigt lär sig artificiella intelligenssystem att göra något liknande när de bearbetar bilder och videor. Den här artikeln ställer en enkel men kraftfull fråga: när datorer analyserar rörelse, djup och objekt i video, liknar deras interna processer hur människans hjärna svarar på samma scener?
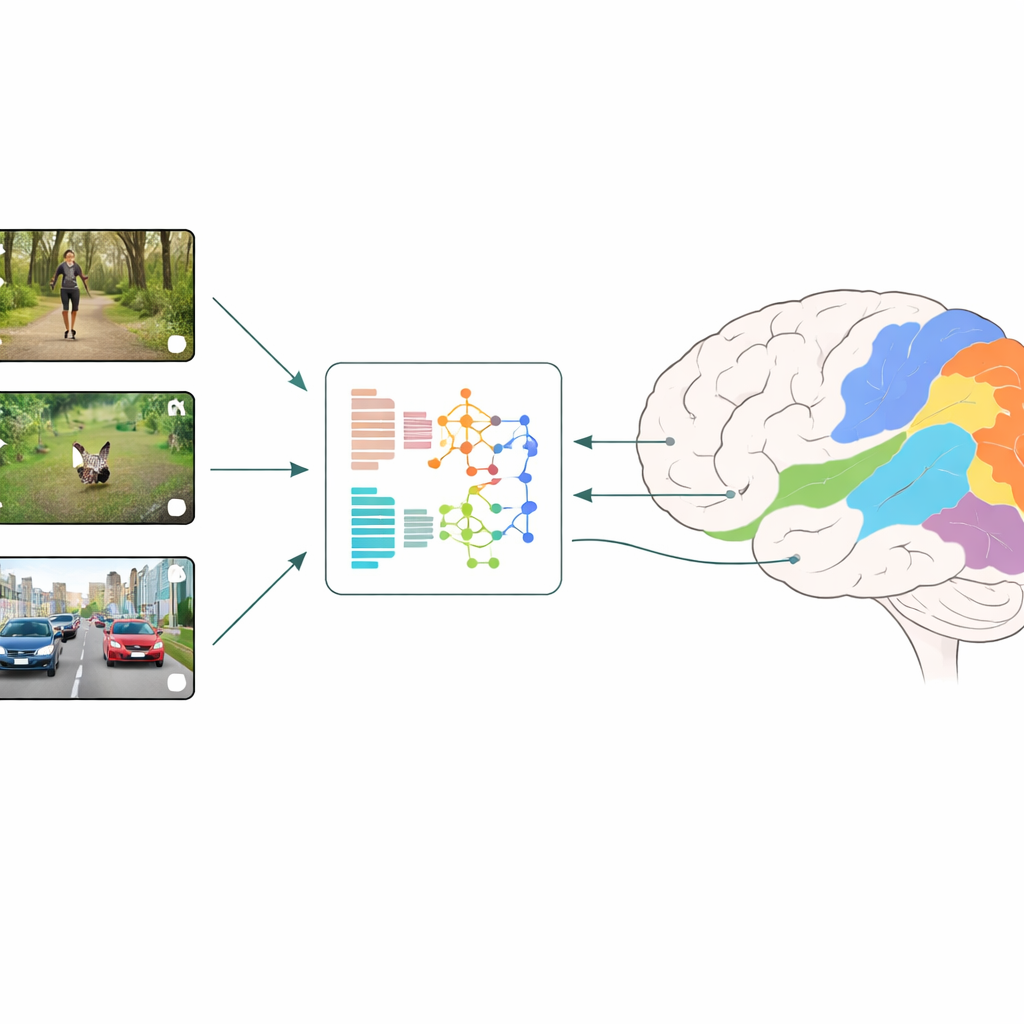
Hur hjärnor och maskiner jämförs
Forskarna använder en strategi som kallas neuralt kodning: de visar människor korta, vardagliga videoklipp samtidigt som de mäter aktiviteten över många små områden i visuell kortex med fMRI. Parallellt matar de in exakt samma videor i olika djuplärandemodeller och läser av modellernas interna funktioner i varje lager. En regressionsmodell lär sig sedan hur dessa artificiella funktioner bäst kan kombineras för att förutsäga hjärnans uppmätta responser, region för region. Genom att jämföra vilka modeller och vilka lager som ger de bästa prediktionerna kan teamet sluta sig till vilka typer av visuell beräkning som mest liknar vad som händer i tidiga respektive senare stadier av mänsklig syn.
Pixeluppgifter kontra helbildsförståelse
Studien fokuserar på tre "pixel‑nivå"‑uppgifter som gör en förutsägelse för varje pixel: optiskt flöde (hur varje pixel rör sig från bildruta till bildruta), djup (hur långt varje pixel är från betraktaren) och semantisk segmentering (vilket objekt eller kroppsdels varje pixel tillhör). Dessa ställs mot "grovare" uppgifter som bara ger en enda etikett per bild eller video, som objektigenkänning och handlingsigenkänning. Vissa av uppgifterna är klass‑agnostiska, som optiskt flöde och djup, som endast berör rörelse eller avstånd, inte objektkategorier. Andra är klassmedvetna, som objekt‑ och handlingsigenkänning samt semantisk segmentering, vilka direkt lär sig om objekt, scener, kroppar och handlingar.
Vad rörelse och djup avslöjar om synen
När författarna jämför modeller framträder ett tydligt mönster. Modeller för optiskt flöde är bäst på att förutsäga aktivitet i tidiga och mellersta visuella regioner, vilka är kända för att reagera starkt på kanter, lokal rörelse och enkla mönster. Däremot presterar dessa rörelsemodeller relativt dåligt i senare regioner som är mer inriktade på objekt, ansikten och scener. Djupskattningsmodeller berättar en annan historia: de förutsäger responser väl inte bara i tidiga regioner, utan även i högre nivåer längs både "var"‑ (dorsala) och "vad"‑ (ventrala) visuella banor. Det tyder på att djupmodeller, även utan explicit träning på objektkategorier, lär sig interna representationer som bär överraskande rik information om objekt och människor i scenen.
Lager, inlärningsstilar och hjärnregioner
Över många modellfamiljer matchar tidiga lager bäst mot tidiga visuella regioner, medan senare lager bättre matchar högre nivåregioner, vilket speglar den kända hierarkin i hjärnan. Konvolutionsnätverk presterar generellt bättre än transformer‑baserade nätverk när det gäller att förutsäga tidig och mittenlig visuell kortex, sannolikt eftersom konvolutioner naturligt fångar upp fina, högfrekventa detaljer liknande de som är viktiga i de första stadierna av synen. En viktig nyans är att klassmedvetna modeller—de som tränats för att namnge objekt, scener eller handlingar—har mycket informativa utgångslager som starkt förutsäger sena visuella områden. I kontrast spelar de slutliga utgångarna mindre roll för klass‑agnostiska uppgifter som rörelse och djup; istället ger mellanliggande lager den starkaste överensstämmelsen med hjärnans responser, särskilt för djup. Överraskande nog fångar helbildsmodeller för objektigenkänning, när de använder samma underliggande ryggrad, hjärnaktivitet bättre än pixel‑för‑pixel semantisk segmentering, vilket antyder att en global bild av scenen är avgörande för hjärnliknande representationer.
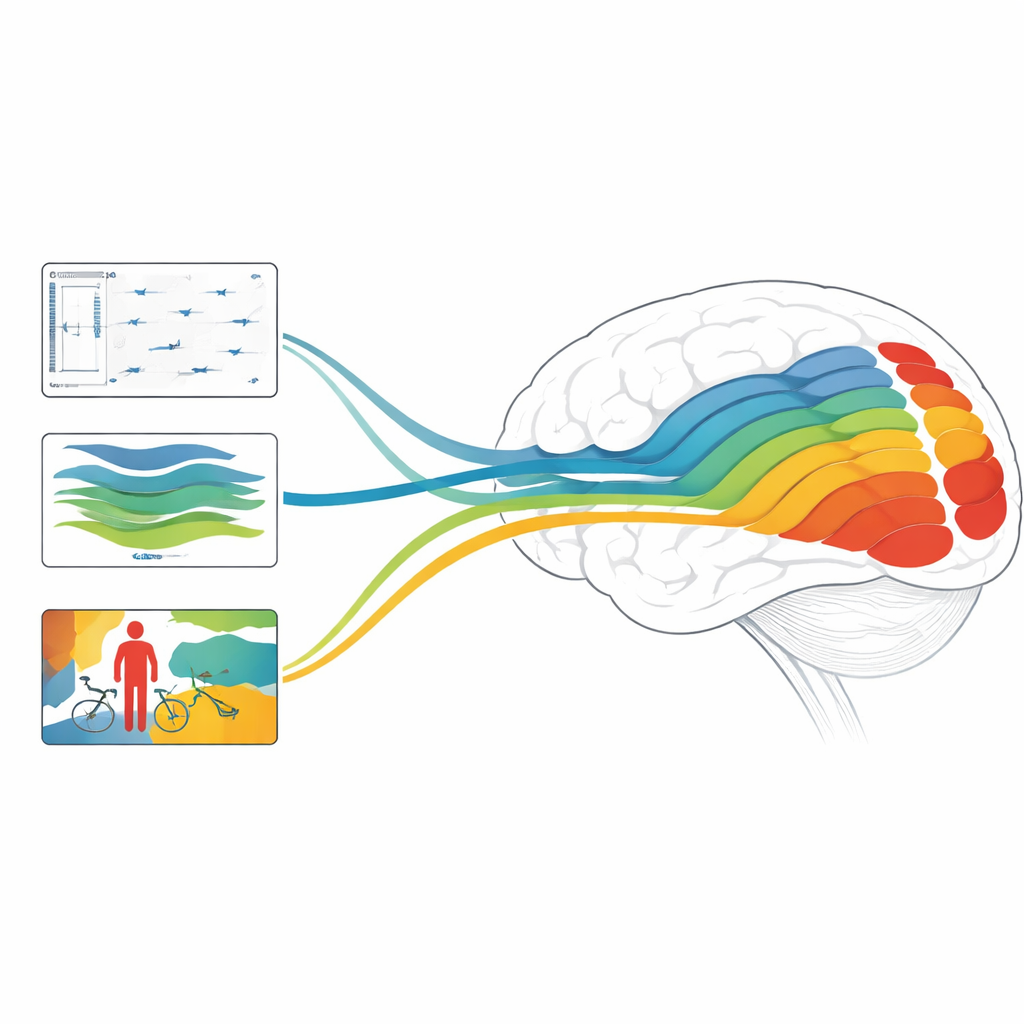
Varför detta är viktigt för hjärnor och maskiner
Sammanfattningsvis visar studien att modeller fokuserade på djup, rörelse och objekt var och en stämmer överens med olika stadier av det visuella systemet, och att kombinationer av modeller avsedda att hantera både statisk struktur och snabba dynamiker kan nå toppmodern noggrannhet i att förutsäga hjärnresponser. För en allmän läsare är huvudbudskapet att modern AI gör mer än att bara efterlikna vår förmåga att etikettera bilder: dess interna processer börjar spegla de flerskiktade beräkningarna i mänsklig syn. Genom att reda ut vilka uppgifter och arkitekturer som bäst återspeglar olika hjärnregioner, pekar detta arbete mot framtida AI‑system som ser världen mer som vi gör—och mot nya sätt att undersöka hur våra egna hjärnor förvandlar en surrande, rörlig pixelström till en rik, tredimensionell och meningsfull upplevelse.
Citering: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Nyckelord: neuralt kodning, visuell kortex, videoförståelse, djuplärande, rörelse och djup