Clear Sky Science · pl
Rozumienie świata w ruchu na poziomie piksela w ramach modelu kodowania neuronowego
Obserwowanie poruszającego się świata, piksel po pikselu
Każdej sekundy oczy i mózg współpracują, przekształcając potok zmieniających się pikseli w stabilny, znaczący obraz ludzi, przedmiotów i działań. W podobny sposób systemy sztucznej inteligencji uczą się przetwarzać obrazy i filmy. W artykule postawiono proste, lecz istotne pytanie: gdy komputery analizują ruch, głębię i obiekty w wideo, czy ich wewnętrzne reprezentacje przypominają to, jak ludzki mózg reaguje na te same sceny?
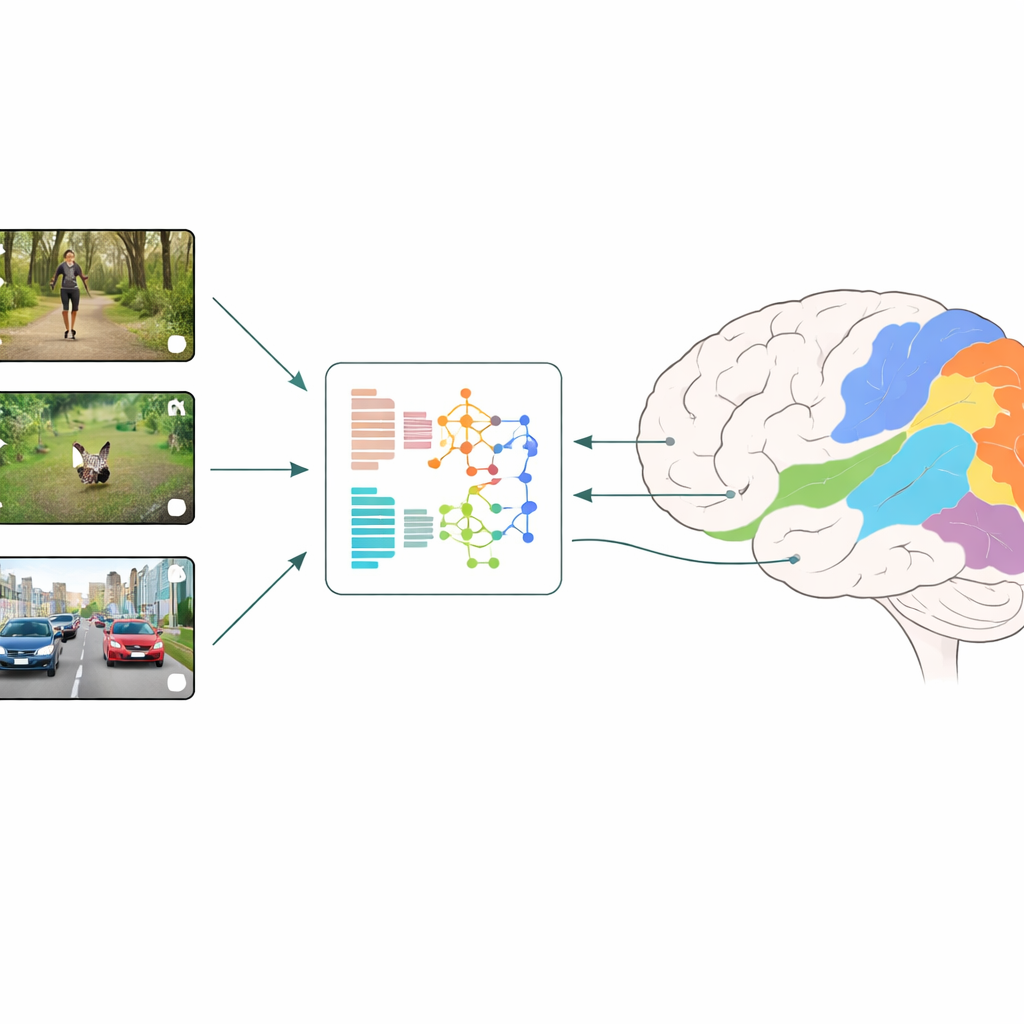
Jak porównuje się mózgi i maszyny
Naukowcy stosują strategię zwaną kodowaniem neuronowym: pokazują uczestnikom krótkie, codzienne klipy wideo, jednocześnie mierząc aktywność wielu małych obszarów kory wzrokowej za pomocą fMRI. Równolegle te same filmy są podawane różnym modelom głębokiego uczenia, a na każdej warstwie odczytywane są wewnętrzne cechy modeli. Model regresyjny uczy się następnie, jak łączyć te sztuczne cechy, aby jak najlepiej przewidzieć zmierzone odpowiedzi mózgu, region po regionie. Porównując, które modele i które warstwy dają najlepsze predykcje, zespół może wnioskować, jakie rodzaje obliczeń wzrokowych najbliżej odpowiadają temu, co dzieje się we wczesnych i późniejszych etapach ludzkiego widzenia.
Zadania pikselowe kontra rozumienie całego obrazu
Badanie koncentruje się na trzech zadaniach „na poziomie piksela”, które przewidują wartość dla każdego piksela: optical flow (jak każdy piksel przemieszcza się między klatkami), głębia (jak daleko każdy piksel jest od obserwatora) oraz segmentacja semantyczna (do którego obiektu lub części ciała należy dany piksel). Są one skontrastowane z zadaniami „grubymi”, które zwracają tylko pojedynczą etykietę dla obrazu lub wideo, jak rozpoznawanie obiektów czy rozpoznawanie akcji. Niektóre z tych zadań są niezależne od klas, jak optical flow i głębia, które interesują się tylko ruchem lub odległością, nie kategoriami obiektów. Inne są zależne od klas, jak rozpoznawanie obiektów i akcji oraz segmentacja semantyczna, które bezpośrednio uczą się o obiektach, scenach, ciałach i działaniach.
Co ruch i głębia mówią o widzeniu
Gdy autorzy porównują modele, wyłania się wyraźny wzorzec. Modele optical flow najlepiej przewidują aktywność we wczesnych i środkowych obszarach wzrokowych, które są znane z silnej reakcji na krawędzie, lokalny ruch i proste wzory. Jednak te modele ruchu radzą sobie stosunkowo słabo w późniejszych obszarach, które bardziej interesują się obiektami, twarzami i scenami. Modele estymacji głębi opowiadają inną historię: dobrze przewidują odpowiedzi nie tylko we wczesnych regionach, ale także w obszarach wyższego poziomu wzdłuż zarówno drogi „gdzie” (grzbietowej), jak i „co” (brzusznej). To sugeruje, że nawet bez eksplicytnego szkolenia na kategorie obiektów modele głębi uczą się wewnętrznych reprezentacji niosących zaskakująco bogate informacje o obiektach i ludziach w scenie.
Warstwy, style uczenia i obszary mózgu
Wśród wielu rodzin modeli wczesne warstwy zwykle najlepiej odpowiadają wczesnym regionom wzrokowym, podczas gdy późniejsze warstwy lepiej dopasowują się do obszarów wyższego poziomu, co odzwierciedla znaną hierarchię w mózgu. Sieci konwolucyjne generalnie przewyższają modele oparte na transformatorach w przewidywaniu aktywności wczesnej i środkowej kory wzrokowej, prawdopodobnie dlatego, że konwolucje naturalnie wychwytują drobne, wysokoczęstotliwościowe detale podobne do tych istotnych w pierwszych etapach widzenia. Istotnym zaskoczeniem jest to, że modele zależne od klas — te trenowane do nazywania obiektów, scen czy akcji — mają bardzo informacyjne warstwy wyjściowe, które silnie przewidują późne obszary wzrokowe. W przeciwieństwie do tego, w zadaniach niezależnych od klas, takich jak ruch i głębia, końcowe wyjścia mają mniejsze znaczenie; zamiast tego warstwy pośrednie dają najsilniejsze dopasowanie do odpowiedzi mózgu, szczególnie w przypadku głębi. Co zaskakujące, przy użyciu tej samej podstawowej architektury, modele rozpoznawania obiektów obrazów w całości lepiej odwzorowują aktywność mózgu niż semantyczna segmentacja piksel-po-pikselu, co sugeruje, że globalny ogląd sceny jest kluczowy dla reprezentacji podobnych do mózgu.
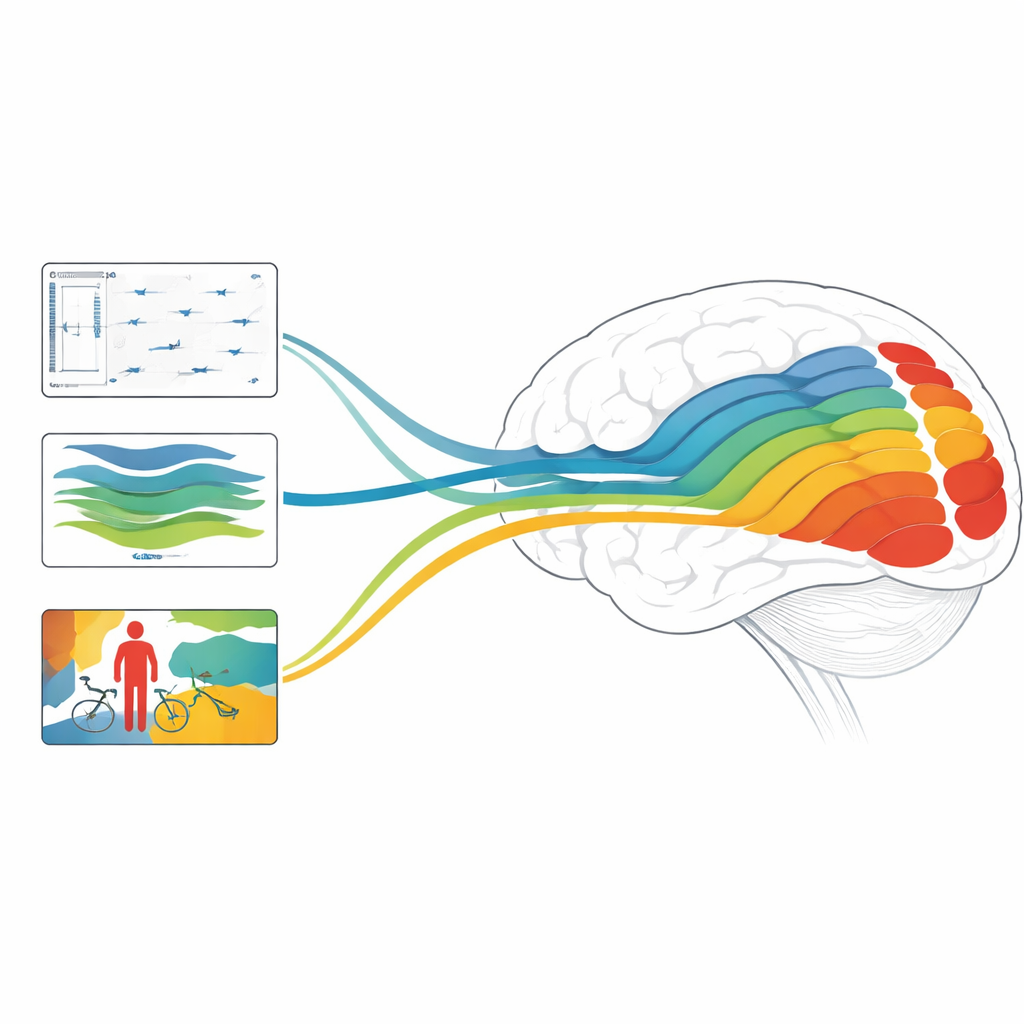
Dlaczego to ma znaczenie dla mózgów i maszyn
Ogólnie badanie wykazuje, że modele skupione na głębi, ruchu i obiektach korelują z różnymi etapami systemu wzrokowego, oraz że połączenia modeli zaprojektowanych do radzenia sobie zarówno ze statyczną strukturą, jak i szybką dynamiką mogą osiągać najlepszą jak dotąd dokładność w przewidywaniu odpowiedzi mózgu. Dla czytelnika niebędącego specjalistą kluczowy przekaz jest taki, że nowoczesna sztuczna inteligencja robi więcej niż tylko naśladować naszą zdolność etykietowania obrazów: jej wewnętrzne mechanizmy zaczynają odzwierciedlać warstwowe obliczenia widzenia ludzkiego. Rozróżniając, które zadania i architektury najlepiej odwzorowują konkretne regiony mózgu, praca ta wskazuje kierunki dla przyszłych systemów AI, które będą postrzegać świat bardziej podobnie do nas — oraz dla nowych sposobów badania, jak nasze własne mózgi przekształcają szum ruchomych pikseli w bogate, trójwymiarowe i znaczące doświadczenie.
Cytowanie: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Słowa kluczowe: kodowanie neuronowe, kora wzrokowa, analiza wideo, uczenie głębokie, ruch i głębia