Clear Sky Science · es
Comprensión a nivel de píxel de un mundo en movimiento dentro de un marco de codificación neuronal
Observando el mundo en movimiento, un píxel a la vez
Cada segundo, tus ojos y tu cerebro colaboran para convertir un torrente de píxeles cambiantes en un mundo estable y con sentido, poblado de personas, objetos y acciones. Al mismo tiempo, los sistemas de inteligencia artificial aprenden a hacer algo similar cuando procesan imágenes y vídeos. Este artículo formula una pregunta sencilla pero potente: cuando los ordenadores analizan el movimiento, la profundidad y los objetos en vídeo, ¿sus procesos internos se parecen a cómo responde el cerebro humano ante las mismas escenas?
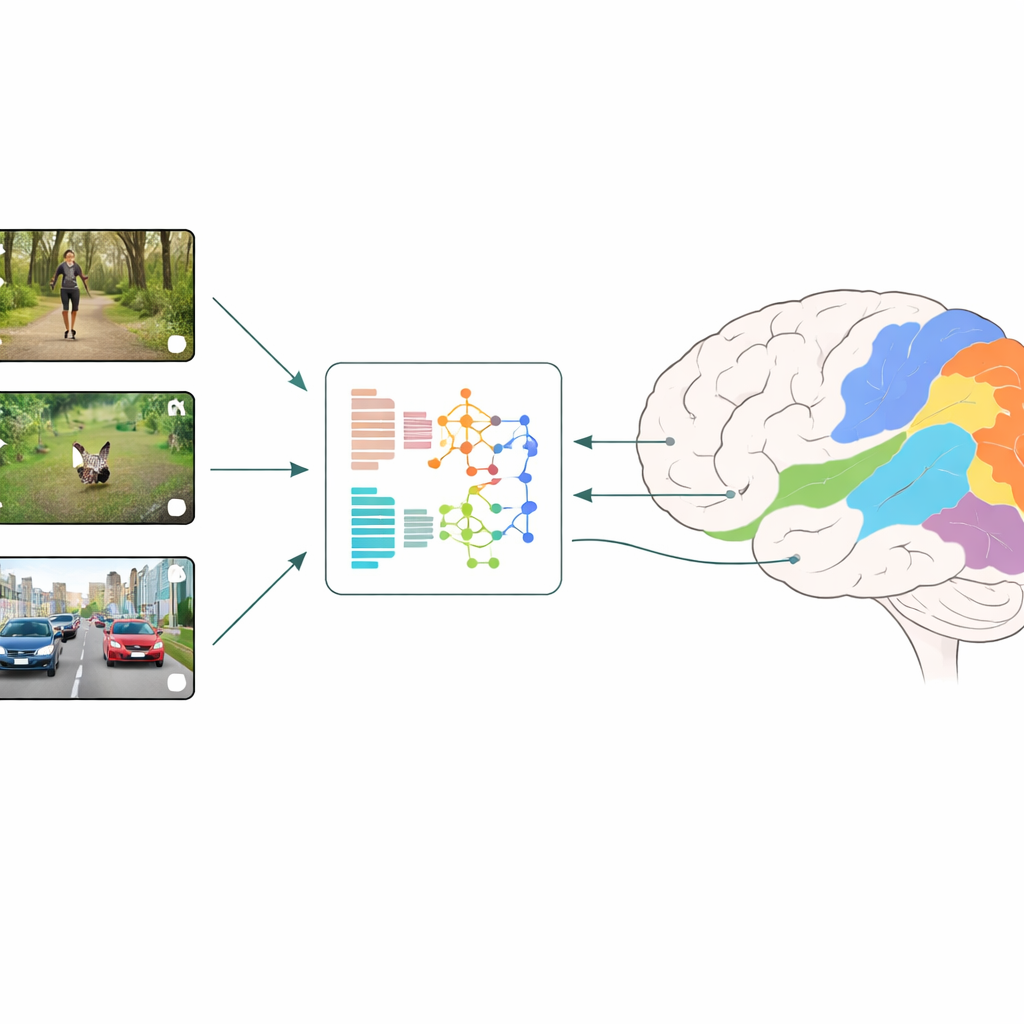
Cómo se comparan cerebros y máquinas
Los investigadores usan una estrategia llamada codificación neuronal: muestran a personas fragmentos breves de vídeo cotidianos mientras miden la actividad en muchos pequeños parches de la corteza visual con fMRI. En paralelo, introducen esos mismos vídeos en distintos modelos de aprendizaje profundo y extraen las características internas de los modelos en cada capa. Un modelo de regresión aprende entonces a combinar esas características artificiales para predecir, mejor que nada, las respuestas cerebrales medidas, región por región. Al comparar qué modelos y qué capas ofrecen las mejores predicciones, el equipo puede inferir qué tipos de cómputo visual reflejan más fielmente lo que ocurre en las etapas tempranas y tardías de la visión humana.
Tareas a nivel de píxel frente a comprensión de la imagen completa
El estudio se centra en tres tareas “a nivel de píxel” que generan una predicción para cada píxel: flujo óptico (cómo se mueve cada píxel de un fotograma a otro), profundidad (a qué distancia está cada píxel del observador) y segmentación semántica (a qué objeto o parte del cuerpo pertenece cada píxel). Estas se contraponen a tareas “grosas” que ofrecen solo una etiqueta por imagen o vídeo, como el reconocimiento de objetos y el reconocimiento de acciones. Algunas de estas tareas son independientes de la clase, como el flujo óptico y la profundidad, que solo se preocupan por el movimiento o la distancia, no por categorías de objetos. Otras son conscientes de la clase, como el reconocimiento de objetos y acciones y la segmentación semántica, que aprenden directamente sobre objetos, escenas, cuerpos y acciones.
Lo que el movimiento y la profundidad revelan sobre la visión
Al comparar modelos surge un patrón claro. Los modelos de flujo óptico son los mejores para predecir la actividad en regiones visuales tempranas y medias, que se sabe que responden con fuerza a bordes, movimiento local y patrones simples. Sin embargo, estos modelos de movimiento rinden relativamente mal en regiones posteriores que se ocupan más de objetos, rostros y escenas. Los modelos de estimación de profundidad cuentan otra historia: predicen bien las respuestas no solo en regiones tempranas, sino también en áreas de nivel superior a lo largo de las vías visuales tanto del “dónde” (dorsal) como del “qué” (ventral). Esto sugiere que, aun sin entrenarse explícitamente en categorías de objetos, los modelos de profundidad aprenden representaciones internas que portan información sorprendentemente rica sobre objetos y personas en la escena.
Capas, estilos de aprendizaje y regiones cerebrales
En muchas familias de modelos, las capas tempranas tienden a coincidir mejor con las regiones visuales tempranas, mientras que las capas tardías encajan mejor con las regiones de nivel superior, haciendo eco de la jerarquía conocida en el cerebro. Las redes convolucionales superan en general a las basadas en transformadores al predecir la corteza visual temprana y media, probablemente porque las convoluciones captan de forma natural detalles finos y de alta frecuencia similares a los importantes en las primeras etapas de la visión. Una diferencia importante es que los modelos conscientes de la clase —los entrenados para nombrar objetos, escenas o acciones— tienen capas de salida muy informativas que predicen con fuerza las áreas visuales tardías. En contraste, para tareas independientes de la clase como movimiento y profundidad, las salidas finales importan menos; en su lugar, las capas intermedias ofrecen la mejor coincidencia con las respuestas cerebrales, especialmente en el caso de la profundidad. Sorprendentemente, usando el mismo esqueleto subyacente, los modelos de reconocimiento de objetos de la imagen completa capturan mejor la actividad cerebral que la segmentación semántica píxel a píxel, lo que sugiere que una visión global de la escena es crucial para representaciones más parecidas a las cerebrales.
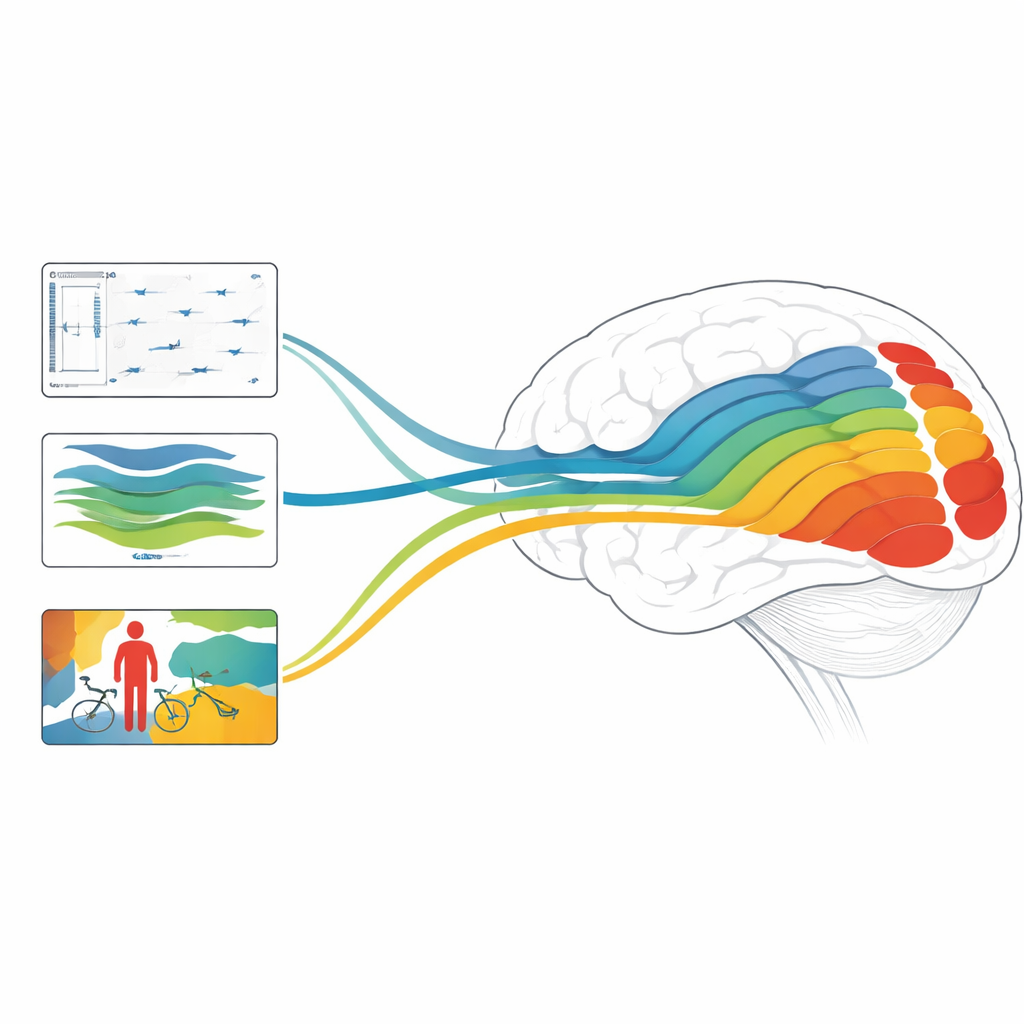
Por qué esto importa para cerebros y máquinas
En conjunto, el estudio demuestra que los modelos centrados en la profundidad, el movimiento y los objetos se alinean cada uno con distintas etapas del sistema visual, y que combinaciones de modelos diseñadas para manejar tanto la estructura estática como la dinámica rápida pueden alcanzar una precisión de vanguardia al predecir respuestas cerebrales. Para un lector no especializado, el mensaje clave es que la IA moderna hace más que imitar nuestra capacidad de etiquetar imágenes: sus procesos internos empiezan a reflejar los cálculos en capas de la visión humana. Al desentrañar qué tareas y arquitecturas mejor imitan distintas regiones cerebrales, este trabajo señala el camino hacia futuros sistemas de IA que «vean» el mundo más como nosotros —y hacia nuevas formas de sondear cómo nuestros propios cerebros transforman un flujo vibrante y en movimiento de píxeles en una experiencia rica, tridimensional y con significado.
Cita: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Palabras clave: codificación neuronal, corteza visual, comprensión de vídeo, aprendizaje profundo, movimiento y profundidad