Clear Sky Science · he
הבנה ברמת הפיקסל של עולם בתנועה במסגרת קידוד נוירלי
צפייה בעולם בתנועה, פיקסל אחד בכל פעם
כל שנייה עיניים ומוח פועלים יחד כדי להפוך שטף מתחלף של פיקסלים לעולם יציב ובעל משמעות של אנשים, חפצים ומעשים. בו־זמנית, מערכות בינה מלאכותית לומדות לעשות דבר דומה כאשר הן מעבדות תמונות וסרטונים. המאמר הזה שואל שאלה פשוטה אך עוצמתית: כשמחשב מנתח תנועה, עומק וחפצים בסרטון—האם הפעולות הפנימיות שלו דומות לאופן שבו המוח האנושי מגיב לאותם הסצנות?
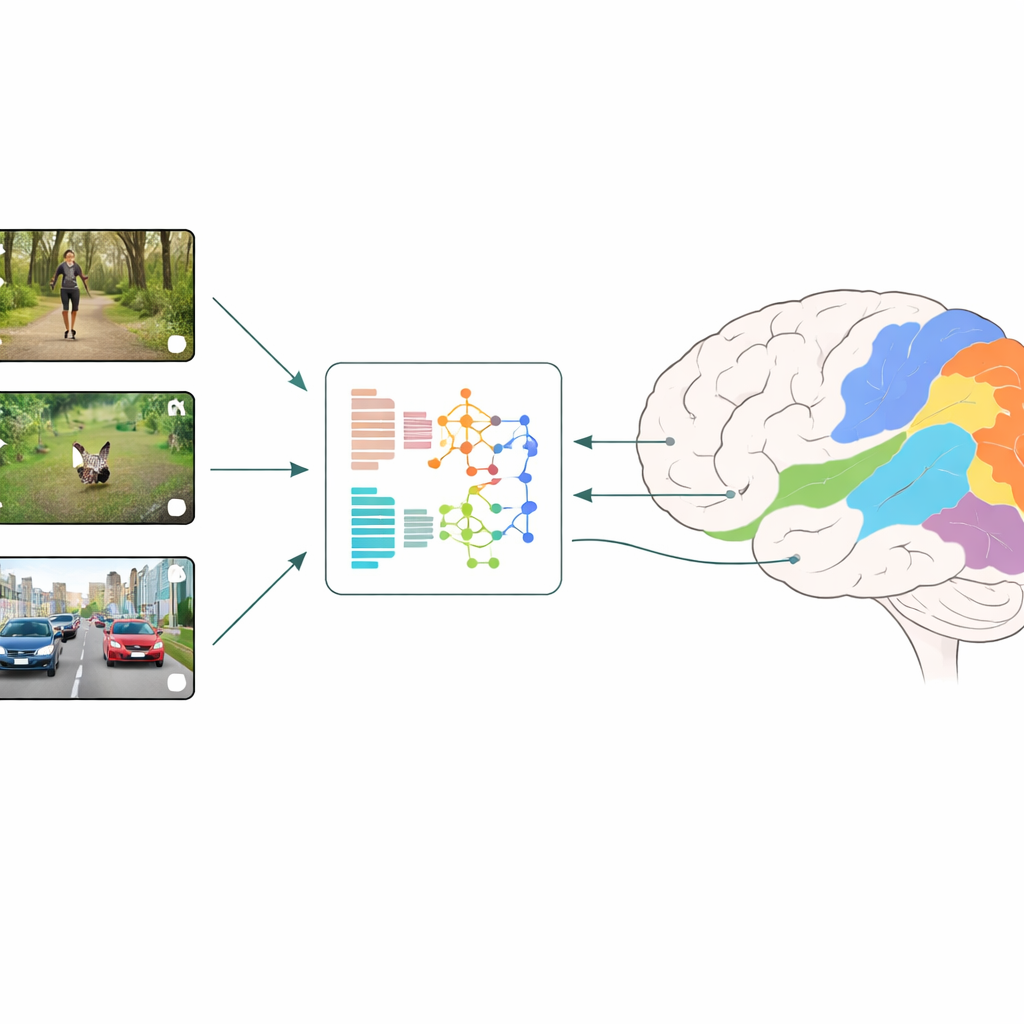
כיצד משווים בין המוח למכונה
החוקרים משתמשים באסטרטגיה שנקראת קידוד נוירלי: הם מציגים לאנשים קטעי וידאו יומיומיים קצרים ומודדים פעילות ברחבי פדחות קטנות של הקורטקס החזותי באמצעות fMRI. במקביל הם מכניסים את אותם סרטונים למודלים שונים של למידה עמוקה וקוראים את התכונות הפנימיות של המודלים בכל שכבה. מודל רגרסיה לומד לאחר מכן כיצד לשלב את התכונות המלאכותיות הללו כדי לחזות בצורה מיטבית את תגובות המוח המדודות, אזור אחר אזור. על ידי השוואה של אילו מודלים ואילו שכבות מספקים את התחזיות הטובות ביותר, הצוות יכול להסיק אילו סוגי חישוב חזותי מדמים מקרוב את מה שמתרחש בשלבים המוקדמים והמאוחרים של הראייה האנושית.
משימות ברמת הפיקסל לעומת הבנה של תמונה שלמה
המחקר מתמקד בשלוש משימות "ברמת הפיקסל" שמנבאות עבור כל פיקסל: optical flow (איך כל פיקסל זז ממסגרת למסגרת), עומק (כמה כל פיקסל רחוק מן הצופה), וסגמנטציה סמנטית (לאיזה חפץ או חלק גוף כל פיקסל שייך). אלה מונחים מול משימות "גסות" שמפיקות רק תווית אחת לתמונה או לסרטון, כגון זיהוי חפצים וזיהוי פעולות. חלק מהמשימות חסרות-קטגוריה, כמו optical flow ועומק, שמתמקדות רק בתנועה או במרחק ולא בקטגוריות של אובייקטים. אחרות מודעות-קטגוריה, כמו זיהוי חפצים ופעולות וסגמנטציה סמנטית, שלומדות באופן ישיר על חפצים, סצנות, גופים ופעולות.
מה שתנועה ועומק חושפים על הראייה
כאשר המחברים משווים מודלים, נראית דפוס ברור. מודלים של optical flow הם הטובים ביותר בחיזוי פעילות באזורים חזותיים מוקדמים ובינוניים, הידועים בכך שהם מגיבים חזק לקצוות, לתנועה מקומית ולתבניות פשוטות. עם זאת, מודלים אלה ביצועים יחסית גרועים באזורים מאוחרים שמתמקדים יותר בחפצים, בפנים ובסצנות. מודלים להערכת עומק מציגים תמונה שונה: הם חוזים תגובות היטב לא רק באזורים מוקדמים, אלא גם באזורים בעל־רמה גבוהה לאורך שני המסלולים החזותיים של "איפה" (דורסלי) ו"מה" (ונטראלי). הדבר מרמז שגם בלי אימון מפורש על קטגוריות חפצים, מודלים לעומק לומדים ייצוגים פנימיים שנושאים מידע עשיר ומפתיע על חפצים ואנשים בסצנה.
שכבות, סגנונות למידה ואזורים מוחיים
בעשרות משפחות מודלים, שכבות מוקדמות נוטות להתאים ביותר לאזורים חזותיים מוקדמים, בעוד ששכבות מאוחרות יותר מתאימות יותר לאזורים ברמת‑על, מה שמשקף את ההיררכיה הידועה במוח. רשתות קונבולוציה בדרך כלל מנצחות רשתות מבוססות טרנספורמר בתחזית הקורטקס החזותי המוקדם והאמצעי, כנראה כי הקונבולוציות קולּטות לפרטי־גזירה עדינים בתדירות גבוהה הדומים לפרטים החשובים בשלבים הראשונים של הראייה. טוויסט חשוב הוא שמודלים מודעים-קטגוריה — אלה שאומנו לקרוא שמות של חפצים, סצנות או פעולות — בעלי שכבות פלט עשירות במידע שמנבאות בעוצמה אזורים חזותיים מאוחרים. לעומת זאת, במשימות חסרות-קטגוריה כמו תנועה ועומק, לפלט הסופי יש פחות חשיבות; במקום זאת, שכבות ביניים נותנות את ההתאמה החזקה ביותר לתגובות המוח, במיוחד בעומק. מפתיע לגלות שבשימוש באותו גב בסיסי, מודלים לזיהוי חפצים של תמונה שלמה תופסים טוב יותר את פעילות המוח מהסגמנטציה הסמנטית פיקסל-אחר-פיקסל, מה שמרמז שראייה גלובלית של הסצנה חשובה לייצוגים דמויי‑מוח.
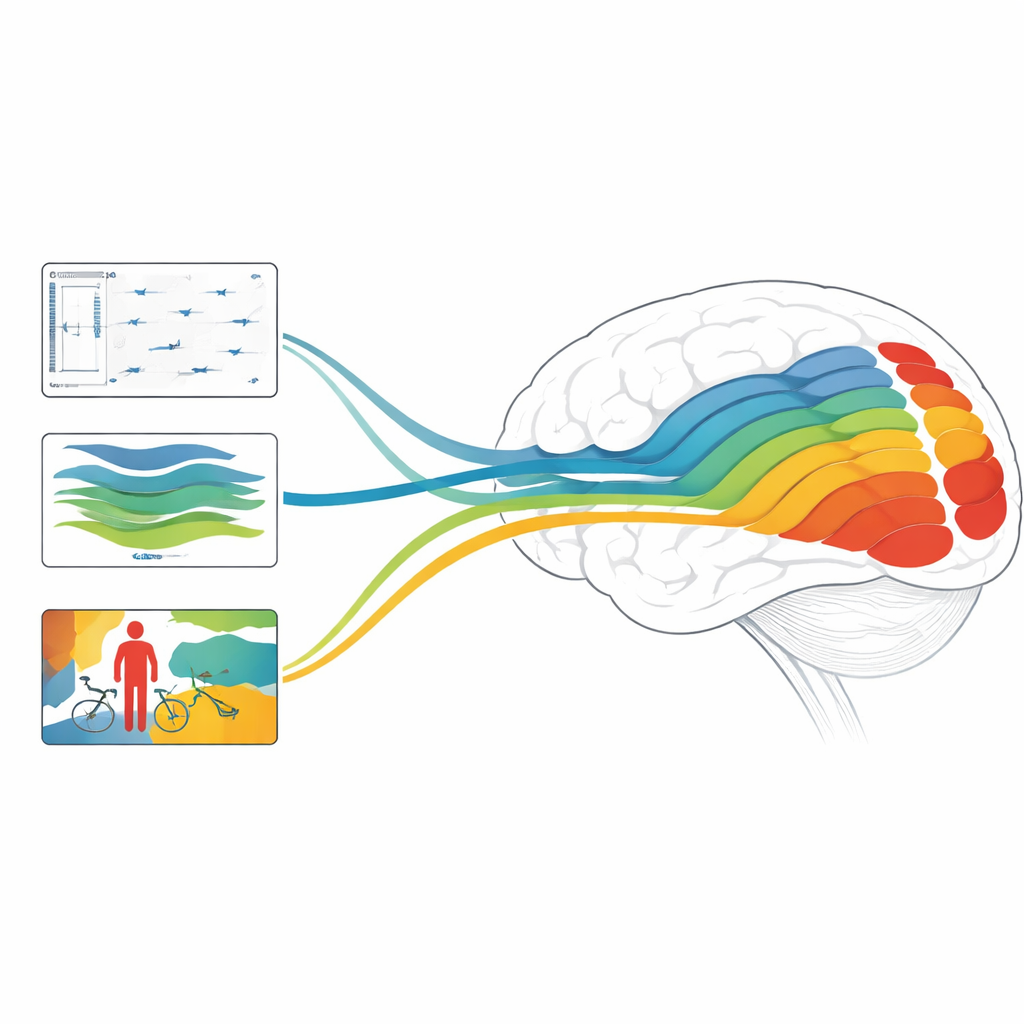
מדוע זה חשוב למוח ולמכונות
בסך הכול, המחקר מגלה שעומק, תנועה ומודלים ממוקדי חפצים כל אחד מתיישר עם שלבים שונים במערכת הראייה, ושהרכבות של מודלים שמתוכננים לטפל גם במבנה סטטי וגם בדינמיקה מהירה יכולות להגיע לדיוק המוביל בחיזוי תגובות מוחיות. לקורא שאינו מומחה, המסר המרכזי הוא שבינה מלאכותית מודרנית עושה יותר מאשר לחקות את יכולתנו לתייג תמונות: הפעולות הפנימיות שלה מתחילות להדהד את החישובים השכבתיים של הראייה האנושית. על ידי בדיקה אילו משימות ואילו ארכיטקטורות מדמות בצורה הטובה ביותר אזורים מוחיים שונים, עבודה זו מצביעה לכיוון מערכות AI עתידיות שיראו את העולם יותר כמו שאנחנו רואים — ולכיוון דרכים חדשות לבחון כיצד המוחות שלנו הופכים זרם פיקסלים רוטט ונע לחוויה תלת‑ממדית, עשירה ובעלת משמעות.
ציטוט: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
מילות מפתח: קידוד נוירלי, קורטקס חזותי, הבנת וידאו, למידה עמוקה, תנועה ועומק