Clear Sky Science · nl
Begrip op pixelniveau van een bewegende wereld binnen een neuraal coderingskader
De bewegende wereld bekijken, pixel voor pixel
Elke seconde werken uw ogen en hersenen samen om een stroom van veranderende pixels om te zetten in een stabiele, betekenisvolle wereld van mensen, objecten en handelingen. Tegelijkertijd leren kunstmatige intelligentiesystemen iets vergelijkbaars te doen wanneer ze beelden en video verwerken. Dit artikel stelt een eenvoudige maar krachtige vraag: wanneer computers beweging, diepte en objecten in video analyseren, lijken hun interne processen dan op hoe het menselijk brein reageert op dezelfde scènes?
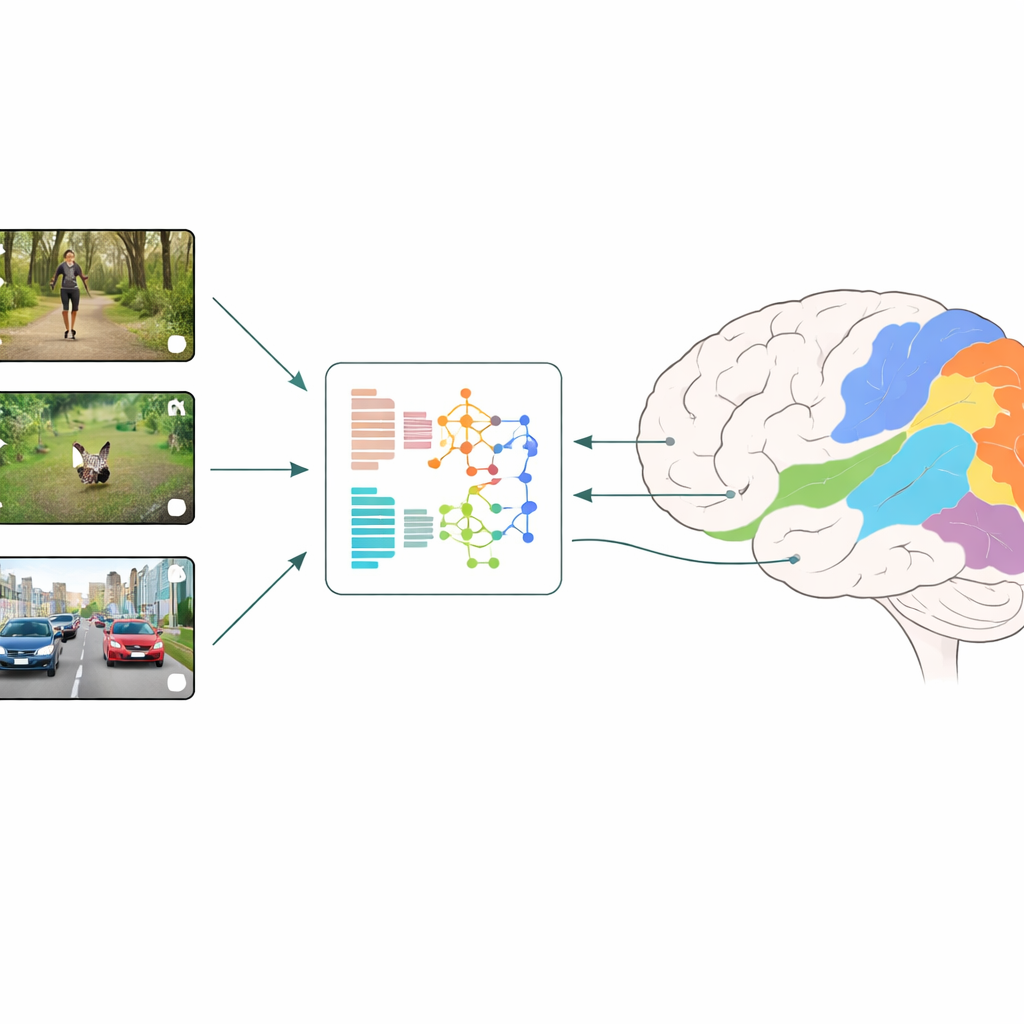
Hoe hersenen en machines worden vergeleken
De onderzoekers gebruiken een strategie die neurale codering wordt genoemd: zij tonen proefpersonen korte, alledaagse videoclips terwijl ze de activiteit meten over veel kleine stukjes van de visuele cortex met fMRI. Tegelijkertijd voeren ze precies dezelfde video’s in verschillende deep learning-modellen en lezen de interne kenmerken van de modellen op iedere laag uit. Een regressiemodel leert vervolgens hoe deze kunstmatige kenmerken het beste gecombineerd kunnen worden om per regio de gemeten hersenreacties te voorspellen. Door te vergelijken welke modellen en welke lagen de beste voorspellingen geven, kan het team afleiden welke typen visuele berekening het meest overeenkomen met wat er in vroege en latere stadia van menselijke visuele verwerking gebeurt.
Pixeltaken versus begrip van het volledige beeld
De studie richt zich op drie "pixel-level" taken die voor elke pixel een voorspelling doen: optische stroming (hoe elke pixel zich van frame naar frame verplaatst), diepte (hoe ver elke pixel van de kijker verwijderd is) en semantische segmentatie (bij welk object of lichaamsdeel elke pixel hoort). Deze worden afgezet tegen "grove" taken die slechts één label per afbeelding of video opleveren, zoals objectherkenning en actieherkenning. Sommige van deze taken zijn klasse-agnostisch, zoals optische stroming en diepte, die alleen om beweging of afstand geven, niet om objectcategorieën. Andere zijn klassebewust, zoals object- en actieherkenning en semantische segmentatie, die direct leren over objecten, scènes, lichamen en handelingen.
Wat beweging en diepte onthullen over zien
Wanneer de auteurs modellen vergelijken, ontstaat een duidelijk patroon. Modellen voor optische stroming voorspellen het beste de activiteit in vroege en middense visuele regio’s, waarvan bekend is dat ze sterk reageren op randen, lokale beweging en eenvoudige patronen. Deze bewegingsmodellen presteren echter relatief slecht in latere regio’s die meer om objecten, gezichten en scènes geven. Diepte-schattingsmodellen vertellen een ander verhaal: zij voorspellen niet alleen goed in vroege regio’s, maar ook in hoger gelegen gebieden langs zowel de "waar" (dorsale) als de "wat" (ventrale) visuele routes. Dit suggereert dat dieptemodellen, zelfs zonder expliciete training op objectcategorieën, interne representaties leren die verrassend rijke informatie over objecten en mensen in de scène bevatten.
Lagen, leerstijlen en hersengebieden
Over veel modelfamilies heen komen vroege lagen doorgaans het beste overeen met vroege visuele regio’s, terwijl latere lagen beter overeenkomen met hoger gelegen regio’s, wat de bekende hiërarchie in de hersenen weerspiegelt. Convolutionele netwerken presteren over het algemeen beter dan op transformatoren gebaseerde netwerken bij het voorspellen van vroege en midden visuele cortex, waarschijnlijk omdat convoluties van nature fijne, hoogfrequente details oppikken die vergelijkbaar zijn met wat belangrijk is in de eerste stadia van het zien. Een belangrijke wending is dat klassebewuste modellen — die getraind zijn om objecten, scènes of acties te benoemen — zeer informatieve uitganslagen hebben die sterke voorspellingen doen voor late visuele gebieden. Daarentegen spelen voor klasse-agnostische taken zoals beweging en diepte de uiteindelijke outputs een minder grote rol; in plaats daarvan leveren tussenliggende lagen de sterkste overeenkomsten met hersenreacties, vooral voor diepte. Verrassend genoeg vangen modellen voor objectherkenning van het volledige beeld, met hetzelfde onderliggende backbone, hersenactiviteit beter dan pixel-voor-pixel semantische segmentatie, wat suggereert dat een globaal beeld van de scène cruciaal is voor breinachtige representaties.
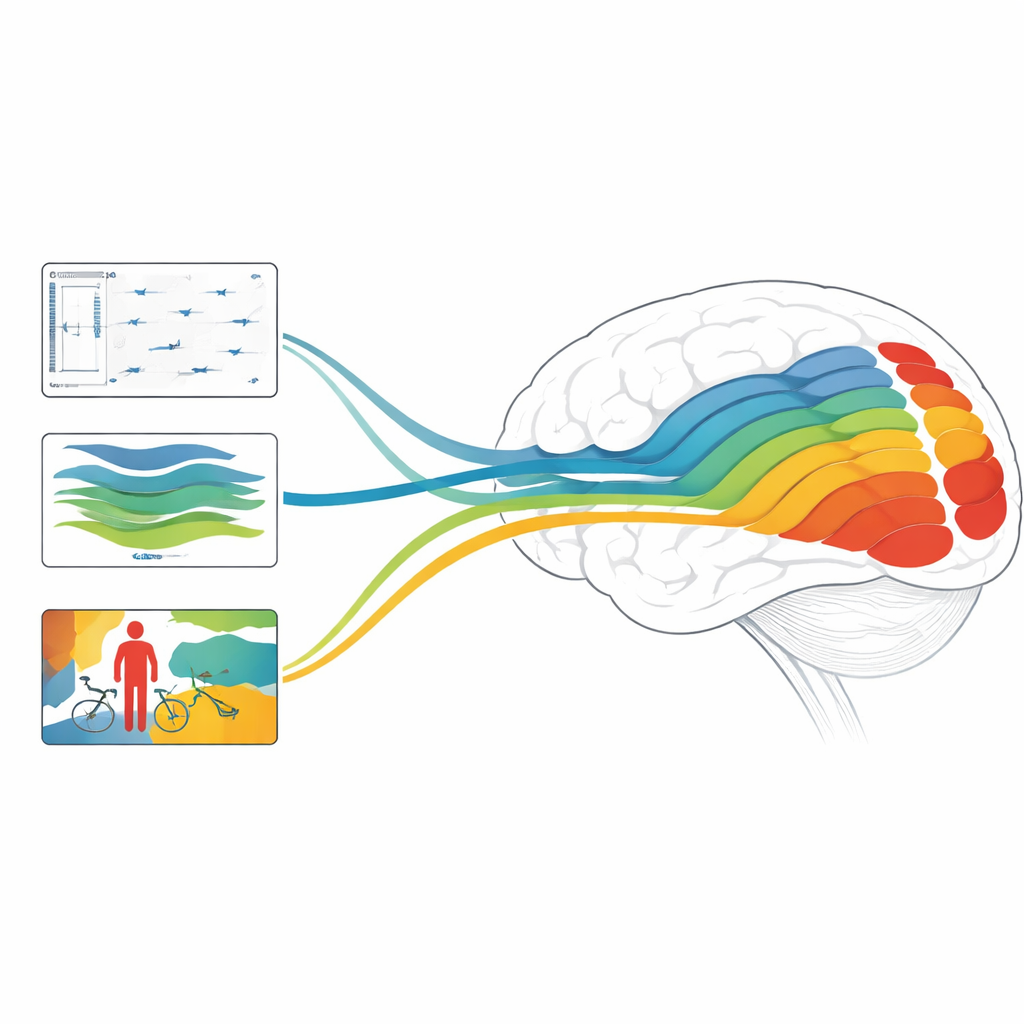
Waarom dit ertoe doet voor hersenen en machines
Samenvattend vindt de studie dat diepte-, beweging- en objectgerichte modellen elk overeenkomen met verschillende stadia van het visuele systeem, en dat combinaties van modellen die zowel statische structuur als snelle dynamiek verwerken, de huidige staat van de kunst kunnen bereiken in het voorspellen van hersenreacties. Voor een lekenlezer is de belangrijkste boodschap dat moderne AI meer doet dan alleen onze vaardigheid om afbeeldingen te labelen imiteren: de interne werking begint de gelaagde berekeningen van menselijke visie te weerspiegelen. Door uit te pluizen welke taken en architecturen het beste verschillende hersengebieden nabootsen, wijst dit werk de weg naar toekomstige AI-systemen die de wereld meer zoals wij zien — en naar nieuwe manieren om te onderzoeken hoe onze eigen hersenen een zoemende, bewegende stroom van pixels omzetten in een rijke, driedimensionale en betekenisvolle ervaring.
Bronvermelding: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Trefwoorden: neurale codering, visuele cortex, videoverstaan, deep learning, beweging en diepte