Clear Sky Science · de
Pixelgenaues Verständnis einer sich bewegenden Welt im Rahmen einer neuronalen Kodierung
Die bewegte Welt betrachten — ein Pixel nach dem anderen
Jede Sekunde arbeiten Augen und Gehirn zusammen, um einen Strom sich verändernder Pixel in eine stabile, sinnvolle Welt aus Menschen, Objekten und Handlungen zu verwandeln. Gleichzeitig lernen künstliche Intelligenzsysteme, etwas Ähnliches zu tun, wenn sie Bilder und Videos verarbeiten. Dieses Papier stellt eine einfache, aber tiefgehende Frage: Wenn Computer Bewegung, Tiefe und Objekte in Videos analysieren, ähneln ihre internen Prozesse denen, wie das menschliche Gehirn auf dieselben Szenen reagiert?
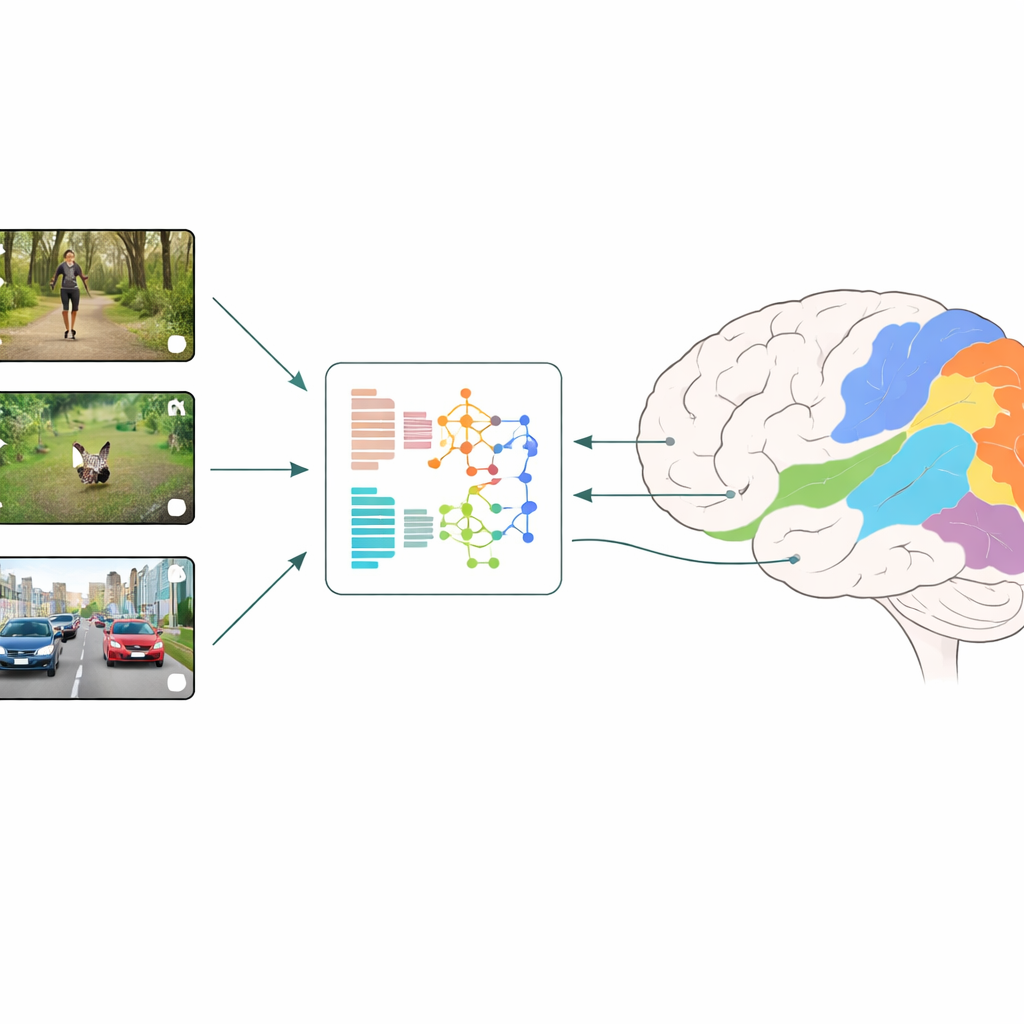
Wie Gehirne und Maschinen verglichen werden
Die Forschenden verwenden eine Strategie, die als neuronale Kodierung bezeichnet wird: Sie zeigen Probanden kurze, alltägliche Videoclips und messen gleichzeitig die Aktivität in vielen kleinen Bereichen des visuellen Kortex mit fMRT. Parallel dazu füttern sie genau dieselben Videos in verschiedene Deep-Learning-Modelle und extrahieren die internen Merkmale der Modelle in jeder Schicht. Ein Regressionsmodell lernt dann, wie diese künstlichen Merkmale kombiniert werden müssen, um die gemessenen Hirnreaktionen regionsspezifisch bestmöglich vorherzusagen. Durch den Vergleich, welche Modelle und welche Schichten die besten Vorhersagen liefern, lässt sich ableiten, welche Arten visueller Verarbeitung den frühen und späteren Stadien der menschlichen Wahrnehmung am ähnlichsten sind.
Pixelaufgaben versus Bildübergreifendes Verständnis
Die Studie konzentriert sich auf drei „pixelbasierte“ Aufgaben, die für jedes Pixel eine Vorhersage liefern: optischer Fluss (wie sich jedes Pixel von Frame zu Frame bewegt), Tiefe (wie weit jedes Pixel vom Betrachter entfernt ist) und semantische Segmentierung (zu welchem Objekt oder Körperteil jedes Pixel gehört). Dem gegenüber stehen „grobe“ Aufgaben, die nur ein einzelnes Label pro Bild oder Video ausgeben, wie Objekterkennung und Handlungserkennung. Manche dieser Aufgaben sind klassenagnostisch, etwa optischer Fluss und Tiefe, die nur an Bewegung bzw. Entfernung interessiert sind, nicht an Objektkategorien. Andere sind klassenbewusst, wie Objekt- und Handlungserkennung sowie semantische Segmentierung, die direkt über Objekte, Szenen, Körper und Aktionen lernen.
Was Bewegung und Tiefe über das Sehen verraten
Beim Vergleich der Modelle zeichnet sich ein klares Muster ab. Modelle für optischen Fluss sagen die Aktivität in frühen und mittleren visuellen Regionen am besten vorher, die dafür bekannt sind, stark auf Kanten, lokale Bewegung und einfache Muster zu reagieren. Diese Bewegungsmodelle schneiden jedoch in späteren Regionen, die stärker auf Objekte, Gesichter und Szenen achten, relativ schlecht ab. Tiefe-Schätzungsmodelle erzählen eine andere Geschichte: Sie sagen die Reaktionen nicht nur in frühen Regionen gut voraus, sondern auch in höher gelegenen Arealen entlang sowohl der „wo“- (dorsalen) als auch der „was“- (ventralen) Sehbahnen. Das deutet darauf hin, dass Tiefenmodelle, selbst ohne explizites Training auf Objektkategorien, interne Repräsentationen erlernen, die überraschend reiche Informationen über Objekte und Personen in der Szene enthalten.
Schichten, Lernstile und Hirnregionen
Über viele Modellfamilien hinweg stimmen frühe Schichten tendenziell am besten mit frühen visuellen Regionen überein, während spätere Schichten besser zu höherstufigen Regionen passen — ein Echo der bekannten Hierarchie im Gehirn. Konvolutionale Netze übertreffen im Allgemeinen transformerbasierte Netze bei der Vorhersage des frühen und mittleren visuellen Kortex, vermutlich weil Faltungen feinere, hochfrequente Details erfassen, die in den ersten Stufen der Wahrnehmung wichtig sind. Eine wichtige Ergänzung ist, dass klassenbewusste Modelle — jene, die darauf trainiert sind, Objekte, Szenen oder Aktionen zu benennen — sehr informative Ausgabeschichten haben, die späte visuelle Areale stark vorhersagen. Im Gegensatz dazu spielen bei klassenagnostischen Aufgaben wie Bewegung und Tiefe die finalen Outputs eine geringere Rolle; stattdessen liefern Zwischenlagen die stärkste Übereinstimmung mit den Hirnantworten, insbesondere bei der Tiefe. Überraschenderweise erfassen Modelle zur Objektklassifikation ganzer Bilder bei gleicher Grundarchitektur die Hirnaktivität besser als pixelgenaue semantische Segmentierung, was darauf hindeutet, dass eine globale Sicht auf die Szene für gehirnähnliche Repräsentationen wichtig ist.
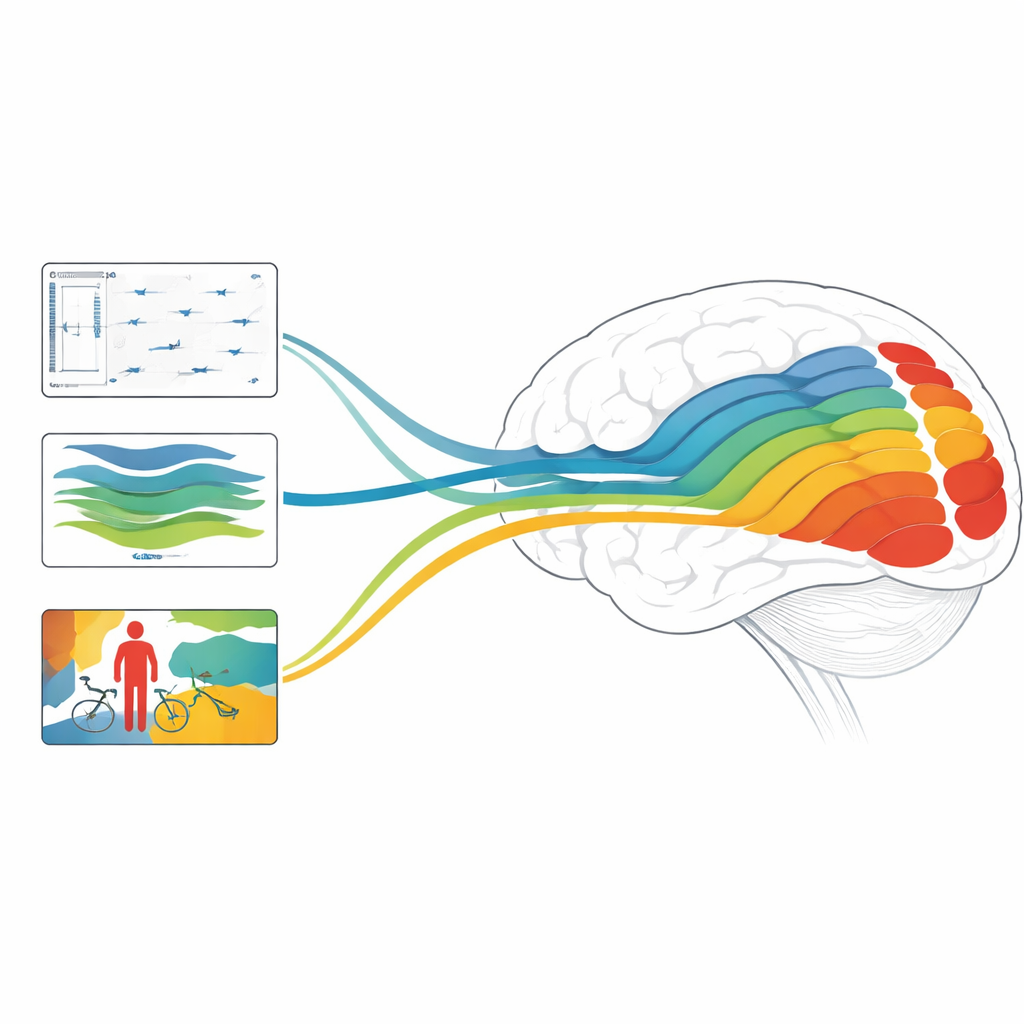
Warum das für Gehirne und Maschinen wichtig ist
Insgesamt zeigt die Studie, dass Tiefen-, Bewegungs- und objektzentrierte Modelle jeweils mit unterschiedlichen Stadien des visuellen Systems übereinstimmen und dass Kombinationen von Modellen, die sowohl statische Struktur als auch schnelle Dynamik berücksichtigen, Spitzenleistungen bei der Vorhersage von Hirnantworten erreichen können. Für eine breite Leserschaft lautet die Kernbotschaft: Moderne KI imitiert nicht nur unsere Fähigkeit, Bilder zu beschriften — ihre internen Prozesse beginnen, die geschichteten Berechnungen der menschlichen Sicht nachzuahmen. Indem aufgezeigt wird, welche Aufgaben und Architekturen am besten zu welchen Hirnregionen passen, weist diese Arbeit den Weg zu künftigen KI-Systemen, die die Welt ähnlicher sehen wie wir — und zu neuen Methoden, zu erforschen, wie unser eigenes Gehirn einen summenden, bewegten Pixelstrom in eine reichhaltige, dreidimensionale und sinnvolle Erfahrung verwandelt.
Zitation: Gamal, M., Rashad, M., Ehab, E. et al. Pixel-level understanding of a world in motion within a neural encoding framework. Sci Rep 16, 12188 (2026). https://doi.org/10.1038/s41598-025-34141-w
Schlüsselwörter: neuronale Kodierung, visueller Kortex, Videoverstehen, Deep Learning, Bewegung und Tiefe