Clear Sky Science · tr
Taşıt kenarı-bulut bilişiminde hata toleranslı görev dışa aktarma için iki düzeyli, hareketlilik farkındalıklı derin pekiştirmeli öğrenme yaklaşımı
Veri İşleyen Araçlar için Daha Akıllı Yollar
Günümüz otomobilleri, kamera görüntülerini, sensör verilerini ve navigasyon bilgilerini sürekli işleyen hareketli bilgisayarlara dönüşüyor. Bu işlemlerin çoğunun sürücü güvenliğini sağlamak ve hizmetleri duyarlı tutmak için milisaniyeler içinde gerçekleşmesi gerekir. Bu makale, gerçek zamanlı hesaplamayı daha hızlı ve güvenilir hâle getirmeyi araştırıyor: bir aracın dijital “işlerini” aracın içinde mi, yol kenarındaki küçük bilgisayarlarda mı yoksa uzak bulut sunucularında mı yapılacağını koordine ederek—üstelik trafik yoğun, bağlantılar zayıf ve aygıtlar ara sıra arızalansa bile.
Neden Araçlar Yoldan Yardım Almalı
Günümüz bağlantılı ve kendi kendine giden araçları nesne algılama, şerit takip ve artırılmış gerçeklik rehberliği gibi görevleri yürütüyor. Bütün bunların yalnızca araç içinde yapılması güçlü donanım ve ciddi enerji gerektirir. Taşıt Kenarı Bulut Bilişim (VECC), araçların yoğun hesaplama gerektiren görevleri yol kenarı ünitelerine (RSU’lar)—yol boyunca yerleştirilmiş küçük hesaplama istasyonlarına—dışa aktarmasına izin vererek bu sorunu ele alır; bu üniteler daha büyük bulut sunucularla işbirliği yapabilir. Ancak bu düzen pratik zorluklarla karşılaşır: araçlar RSU’lar arasında hızla hareket eder, kablosuz bağlantılar kopup gelir ve hem kenar hem bulut makineleri aşırı yüklenebilir veya arızalanabilir. Bu etkenlerin birleşimi gecikmelere veya görevlerin tamamen başarısız olmasına yol açabilir; bu, zaman açısından kritik sürüş uygulamaları için kabul edilemez.
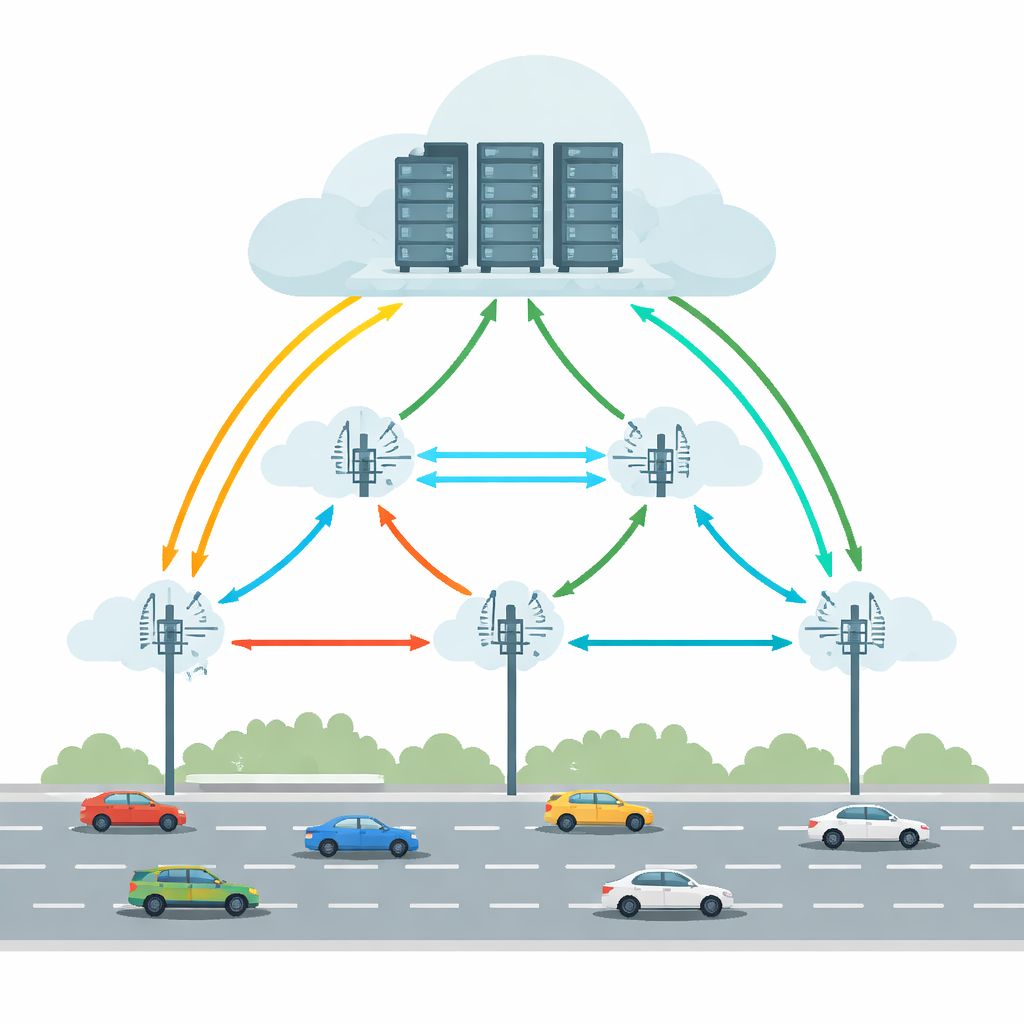
Hareket, Gecikmeler ve Arızalar Arasındaki Denge
Çok sayıda önceki sistem, dışa aktarmayı araç konumunu tahmin ederek, gecikmeyi en aza indirerek veya enerji tasarrufu sağlayarak iyileştirmeyi denedi. Ancak genellikle güvenilirliği sonradan ele almışlar ve çoğunlukla istikrarlı koşullar varsaymışlardır. Gerçek yollar daha düzensizdir: kablosuz bağlantılar kopabilir, sunucular arızalanabilir ve trafik desenleri aniden değişebilir. Bu çalışma, pratik bir çözümün araç hareketliliğini, ağ gecikmelerini ve arıza riskini aynı anda, birden çok RSU genelinde ele alması gerektiğini savunuyor. Ayrıca merkezi tek bir “beyin”e dayanmaktan kaçınmalı; çünkü ağ büyüdükçe bu bir darboğaz haline gelir. Bunun yerine, yerel birimlerin hızlı tepki verebildiği ama yine de daha geniş sistemden öğrenebildiği dağıtık bir karar alma yapısı olmalı.
Yol Boyunca İki Düzeyli Öğrenen Beyinler
Yazarlar, deneme-yanılma ile öğrenen bir derin pekiştirmeli öğrenme türü olan Derin Q-Ağları (Deep Q-Networks) ile desteklenen iki düzeyli bir karar çerçevesi öneriyor. Birinci düzeyde, her RSU’da çoğaltılmış bir öğrenme ajanı gelen her görev için hangi RSU’nun en uygun olduğunu seçer. Bu seçim, her RSU’nun yükü, işlem gücü, arıza eğilimleri ve aracın beklenen seyahat yolu ile sonuçların o yol boyunca geri gönderilmesinin alacağı zamanı dikkate alır. İkinci düzeyde ise bir RSU seçildikten sonra yerel bir ajan görevi tam olarak nasıl yürüteceğine karar verir: hangi sunucunun birincil olacağı, hangisinin yedek olacağı ve hangi arıza-geri kazanım deseninin kullanılacağı belirlenir. Üç strateji değerlendirilir: aynı sunucuda yeniden deneme, arızadan sonra yedek sunucuya geçiş veya birincil ve yedeği paralel çalıştırıp ilk biteni tutma.
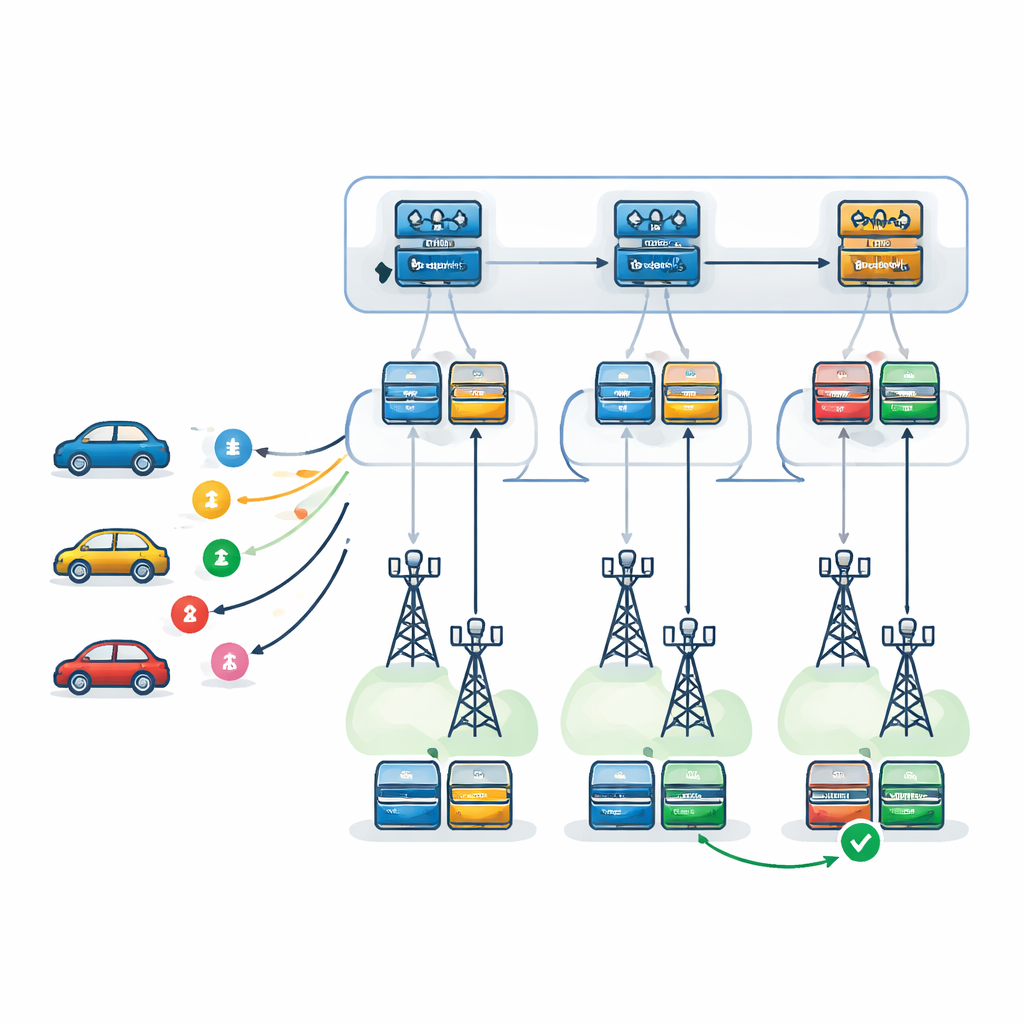
Sanal Bir Kentte Sistemi Test Etmek
Bu iki düzeyli öğrenme düzeninin ne kadar iyi çalıştığını görmek için araştırmacılar, bir trafik sistemi (SUMO) ile olay tabanlı bir motoru (SimPy) birleştiren ayrıntılı bir simülatör kurdular. Bu sayede hareket eden araçları, değişen kablosuz koşulları ve kenar ile bulut sunucularındaki gerçekçi kuyrukları modelleyebildiler. Yöntemlerini birkaç alternatife karşı karşılaştırdılar: farklı bir öğrenme algoritması (Proximal Policy Optimization) kullanan benzer iki düzeyli sistem, o an için görünürde en iyi RSU’yu seçen basit açgözlü strateji, görevlerin yalnızca onları ilk alan RSU tarafından işlendiği yönlendirme olmayan yapı ve tüm kararları tek seferde almaya çalışan tek katmanlı bir öğrenme ajanı. Birçok bölüm ve farklı trafik yoğunlukları altında ortalama ödüller, genel gecikme ve görevlerin ne sıklıkta başarısız olduğu ya da sürelerini kaçırdığı ölçüldü.
Sıkışık Yollarda Sonuçların Gösterdiği
Hafif trafik ve nispeten gevşek süre sınırları altında, kaynaklar az kullanıldığından çoğu yöntem benzer performans gösterdi. Farklar, ağır, dengesiz trafik ve daha sıkı zaman kısıtları altında—yani en kritik stresli durumlarda—görüldü. Bu koşullarda, iki düzeyli Derin Q-Ağı diğer yaklaşımlara kıyasla görev başarısızlıklarını yaklaşık %29 ila %63 oranında azalttı ve genel ödülü yaklaşık %8 ila %38 arasında iyileştirdi. Hiyerarşik yapı, RSU ve sunucu sayısı arttıkça tek katmanlı öğreniciden daha ölçeklenebilir olduğu kanıtlandı ve RSU’lar arasındaki iletişim bir miktar güvenilmez olduğunda veya aracın gelecekteki rotası hakkındaki tahminler kusurlu olduğunda bile sağlam kaldı.
Günlük Sürücüler İçin Anlamı
Basitçe söylemek gerekirse, çalışma yol ağına katmanlı bir “öğrenen beyin” vermenin bağlı ve otonom araçları daha duyarlı ve güvenilir kılabileceğini gösteriyor. Önce her görev için doğru yol kenarı birimini seçip sonra bu görevin gecikmeler ve arızalar karşısında nasıl ayakta kalacağını planlayarak sistem tepki sürelerini düşük tutuyor ve yanıtların zamanında gelme olasılığını artırıyor. Gerçek dünya dağıtımı hâlâ düzensiz koşullar ve güvenlik kaygularıyla başa çıkmayı gerektirecek olsa da, bu çalışma geleceğin araçlarının artan hesaplama taleplerine ayak uydurabilecek daha akıllı, hata toleranslı dijital altyapıya giden bir yol taslağı sunuyor.
Atıf: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Anahtar kelimeler: taşıt kenarı hesaplama, görev dışa aktarma, derin pekiştirmeli öğrenme, hata toleransı, akıllı ulaşım sistemleri