Clear Sky Science · it
Un approccio di deep reinforcement learning a due livelli sensibile alla mobilità per l’offloading tollerante ai guasti nel vehicular edge-cloud computing
Strade più intelligenti per auto che consumano molti dati
Le auto moderne stanno diventando computer su ruote, continuamente impegnate nell’elaborazione di flussi video, dati dai sensori e informazioni di navigazione. Gran parte di questo lavoro deve svolgersi in millisecondi per garantire la sicurezza dei conducenti e la reattività dei servizi. Questo articolo esplora come rendere quel calcolo in tempo reale più affidabile e più veloce coordinando dove vengono eseguiti i “compiti” digitali di un veicolo—dentro l’auto, su piccoli computer lungo la strada o su server cloud remoti—even quando il traffico è intenso, le connessioni sono instabili e i dispositivi guastano occasionalmente.
Perché le auto hanno bisogno di aiuto dalla strada
I veicoli connessi e a guida autonoma di oggi eseguono attività come rilevamento degli oggetti, mantenimento della corsia e guida con realtà aumentata. Eseguire tutto ciò solo a bordo richiederebbe hardware molto potente e molta energia. Il Vehicular Edge Cloud Computing (VECC) affronta questo problema permettendo alle auto di scaricare compiti gravosi su Roadside Unit (RSU)—piccole postazioni di calcolo lungo la strada—that possono a loro volta cooperare con server cloud più grandi. Ma questa architettura incontra problemi pratici: le auto si spostano rapidamente tra le RSU, i collegamenti wireless possono interrompersi e sia le macchine di edge sia quelle cloud possono sovraccaricarsi o guastarsi. Questi fattori possono causare ritardi lunghi o il fallimento dei compiti, situazioni inaccettabili per applicazioni di guida critiche per il tempo.
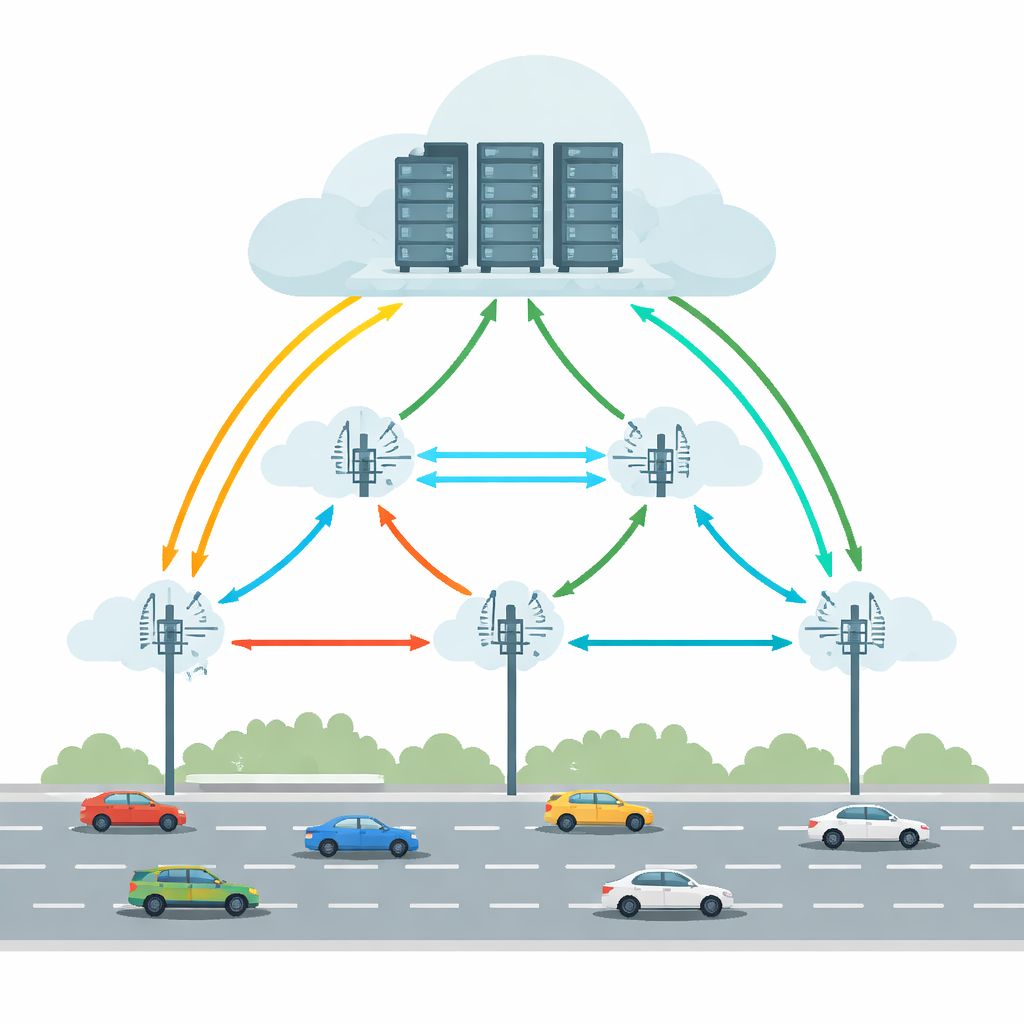
Bilanciare movimento, ritardi e guasti
Molti sistemi precedenti hanno cercato di migliorare l’offloading predicendo dove sarà un’auto, minimizzando i ritardi o risparmiando energia. Tuttavia, di solito la affidabilità è stata trattata come un ripensamento e spesso si sono assunte condizioni stabili. Le strade reali sono più disordinate: i collegamenti wireless possono cadere, i server possono guastarsi e i flussi di traffico possono cambiare improvvisamente. Questo lavoro sostiene che una soluzione pratica deve considerare mobilità del veicolo, ritardi di rete e rischio di guasti contemporaneamente, su più RSU. Deve inoltre evitare un unico “cervello” centrale che diventi un collo di bottiglia con la crescita della rete stradale. Invece, il processo decisionale dovrebbe essere distribuito, con unità locali in grado di reagire rapidamente pur imparando dal sistema più ampio.
Cervelli di apprendimento a due livelli lungo la strada
Gli autori propongono un quadro decisionale a due livelli alimentato da Deep Q-Network, un tipo di deep reinforcement learning che apprende per tentativi ed errori. Al primo livello, un agente di apprendimento—replicato in ogni RSU—sceglie quale RSU è più adatta a gestire ciascun compito in arrivo. Tiene conto del carico di ciascuna RSU, della potenza di elaborazione, delle tendenze ai guasti e del percorso previsto del veicolo, così come del tempo necessario a restituire i risultati lungo quel percorso. Al secondo livello, una volta scelta un’RSU, un agente locale decide esattamente come eseguire il compito: quale server dovrebbe essere primario, quale servire da backup e quale schema di recupero dai guasti utilizzare. Sono considerate tre strategie: ritentare sullo stesso server, passare a un server di backup dopo un guasto, o eseguire primario e backup in parallelo mantenendo il risultato di chi termina per primo.
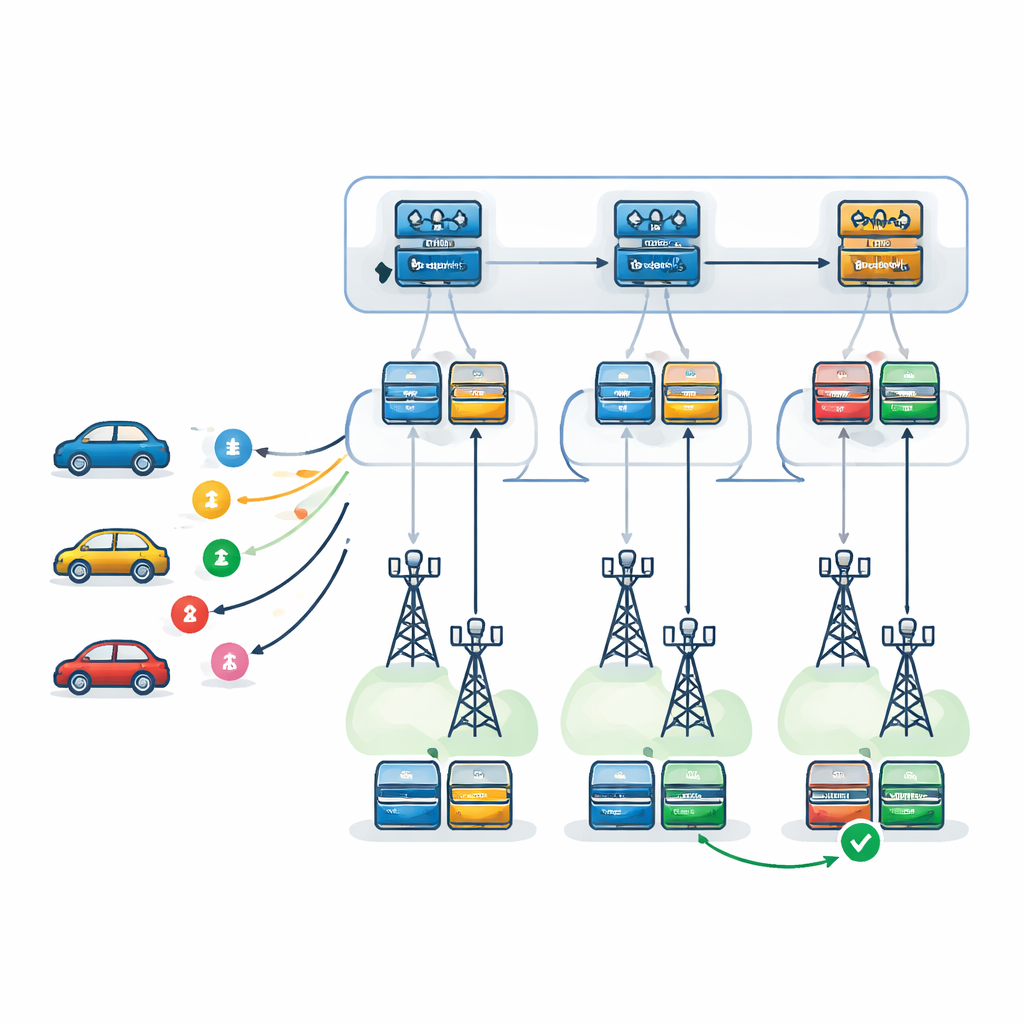
Testare il sistema in una città virtuale
Per valutare l’efficacia di questa architettura a due livelli, i ricercatori hanno costruito un simulatore dettagliato che accoppia un sistema di traffico (SUMO) con un motore basato su eventi (SimPy). Questo ha permesso di modellare veicoli in movimento, condizioni wireless variabili e code realistiche presso server di edge e cloud. Hanno confrontato il loro metodo con diverse alternative: un sistema a due livelli simile che usa un diverso algoritmo di apprendimento (Proximal Policy Optimization), una strategia greedy semplice che sceglie sempre l’RSU apparentemente migliore al momento, una configurazione senza forwarding in cui i compiti sono gestiti solo dall’RSU che li riceve per prima, e un singolo agente di apprendimento “piatto” che cerca di prendere tutte le decisioni in una volta. Attraverso molti episodi e sotto diverse intensità di traffico, hanno misurato reward medi, ritardo complessivo e la frequenza con cui i compiti fallivano o mancavano le scadenze.
Cosa mostrano i risultati sulle strade affollate
Sotto traffico leggero e scadenze relativamente larghe, la maggior parte dei metodi ha prestazioni simili perché le risorse erano poco utilizzate. Le differenze sono emerse sotto traffico intenso e sbilanciato e vincoli temporali più stringenti—esattamente le situazioni stressanti che contano di più. In questi scenari, il Deep Q-Network a due livelli ha ridotto i fallimenti dei compiti di circa il 29%–63% rispetto agli altri approcci e ha migliorato il reward complessivo di circa l’8%–38%. La struttura gerarchica si è dimostrata più scalabile del modello piatto all’aumentare del numero di RSU e server, e ha mantenuto robustezza anche quando la comunicazione tra RSU era parzialmente inaffidabile o le previsioni sul percorso futuro di un veicolo erano imperfette.
Cosa significa questo per gli automobilisti di tutti i giorni
In termini semplici, lo studio mostra che dotare la rete stradale di un “cervello” di apprendimento stratificato può rendere i veicoli connessi e autonomi più reattivi e affidabili. Scegliendo prima l’unità roadside giusta per ogni compito e poi pianificando come quel compito dovrebbe sopravvivere a ritardi e guasti, il sistema mantiene bassi i tempi di risposta e aumenta la probabilità che le risposte arrivino in tempo. Sebbene la distribuzione nel mondo reale dovrà ancora affrontare condizioni complesse e questioni di sicurezza, questo lavoro delinea una strada verso un’infrastruttura digitale più intelligente e tollerante ai guasti in grado di sostenere le crescenti esigenze computazionali delle auto del futuro.
Citazione: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Parole chiave: vehicular edge computing, offloading dei compiti, deep reinforcement learning, tolleranza ai guasti, sistemi di trasporto intelligenti