Clear Sky Science · he
גישה כפולת-רמות מבוססת למידה עמוקה מחזקת-תגמול המודעות לניידות לביצוע ניתוב מטלות חסין-שגיאות במחשוב קצה-ענן רכבי
כבישים חכמים לרכבים זקוקים לנתונים
מכוניות מודרניות הופכות למחשבים ניידים, החושבים ללא הרף על זרמי מצלמות, נתוני חיישנים ומידע ניווט. רוב העיבוד הזה צריך להתבצע במילישניות כדי לשמור על בטיחות הנהגים ועל תגובתיות השירותים. מאמר זה בוחן כיצד להפוך חישוב בזמן-אמת למהימן ומהיר יותר על ידי תיאום היכן מבוצעות "המשימות" הדיגיטליות של הרכב — בתוך הרכב, במחשבים קטנים בצדי הדרך או בשרתי ענן מרוחקים — גם כאשר התנועה עסוקה, הקישורים הרדיו רעועים והמכשירים נכשלים מדי פעם.
למה רכבים צריכים עזרה מהדרך
רכבים מחוברים ומונעי-עצמיים של היום מריצים מטלות כגון גילוי עצמים, שמירה על נתיב והכוונה במציאות רבודה. ביצוע כל זה רק בתוך הרכב יחייב חומרה חזקה וצריכת אנרגיה משמעותית. מחשוב קצה-ענן רכבי (VECC) מתמודד עם הבעיה על ידי אפשור לנסיעות להוציא מטלות תובעניות ליחידות בצד הדרך (RSUs) — תחנות חישוב קטנות לאורך הכביש — שיכולות לשתף פעולה עם שרתי ענן גדולים יותר. אך הסדרה הזו מתמודדת עם קשיים מעשיים: רכבים נעים במהירות בין RSU-ים, קישורי אלחוט יכולים ליפול ולחזור, וגם מכונות קצה וענן עלולות להיות עמוסות או להיכשל. יחד, גורמים אלה עלולים לגרום לעיכובים ארוכים או לכשל מוחלט במטלות, מה שלא מתקבל על הדעת ליישומים קריטיים בזמן בנהיגה.
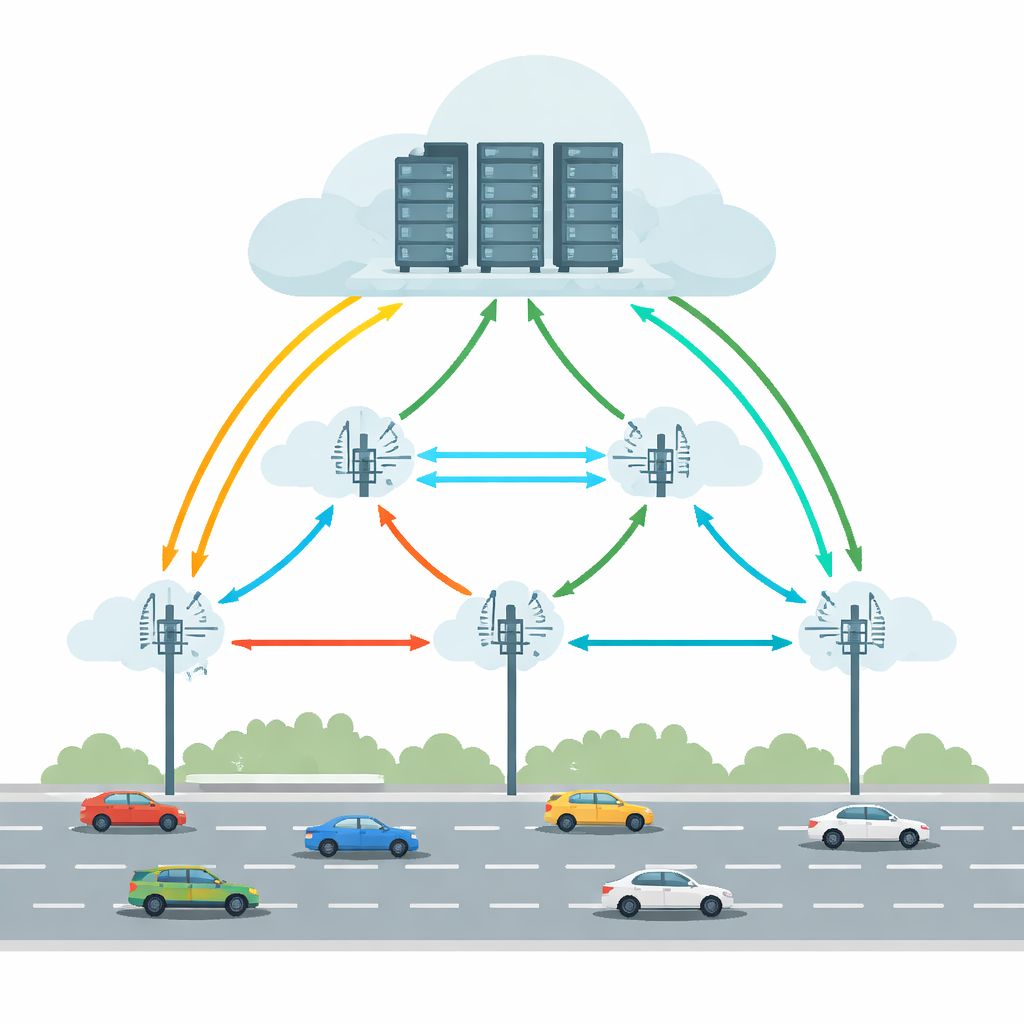
איזון תנועה, עיכובים ושגיאות
מערכות קודמות ניסו לשפר את הניתוב על ידי חיזוי מיקום הרכב, מיזעור עיכוב או חיסכון באנרגיה. עם זאת, בדרך כלל הן נטו להתייחס לאמינות כהשלמה וידעו להניח תנאים יציבים. הכבישים האמיתיים יותר מבולגנים: קישורים אלחוטיים עלולים ליפול, שרתים עלולים להיכשל ותבניות תנועה יכולות להשתנות בפתאומיות. המאמר טוען שפתרון מעשי חייב להתחשב בניידות כלי הרכב, בעיכובי הרשת ובסיכון לכשלים במקביל, על פני מספר RSU-ים. הוא גם צריך להימנע מ"מוח" מרכזי יחיד שמייצר צוואר בקבוק ככל שהרשת גדלה. במקום זאת, קבלת ההחלטות צריכה להיות מבוזרת, עם יחידות מקומיות שיכולות להגיב במהירות ועדיין ללמוד מהמערכת הרחבה יותר.
מוחות למידה בשתי רמות לאורך הדרך
המחברים מציעים מסגרת קבלת החלטות דו-רמתית המונעת על ידי רשתות Q עמוקות (Deep Q-Networks), סוג של למידה עמוקה מחזקת-תגמול שלומדת בניסוי וטעייה. ברמה הראשונה, סוכן למידה — המשוכפל בכל RSU — בוחר איזה RSU מתאים ביותר לטפל בכל מטלה נכנסת. הוא לוקח בחשבון את העומס של כל RSU, כוח העיבוד שלו, נטייתו לכישלונות, והנתיב הצפוי של הרכב, וכן את הזמן שייקח להחזיר תוצאות לאורך נתיב זה. ברמה השנייה, לאחר בחירת RSU, סוכן מקומי מחליט בדיוק כיצד לבצע את המטלה: איזה שרת יהיה ראשי, איזה ישמש גיבוי, ואיזה דפוס התאוששות מתקלות יש להשתמש. נבחנות שלוש אסטרטגיות: ניסיון חוזר על אותו שרת, מעבר לשרת גיבוי לאחר כישלון, או הרצת ראשי וגיבוי במקביל ושימור התוצאה שמסתיימת ראשונה.
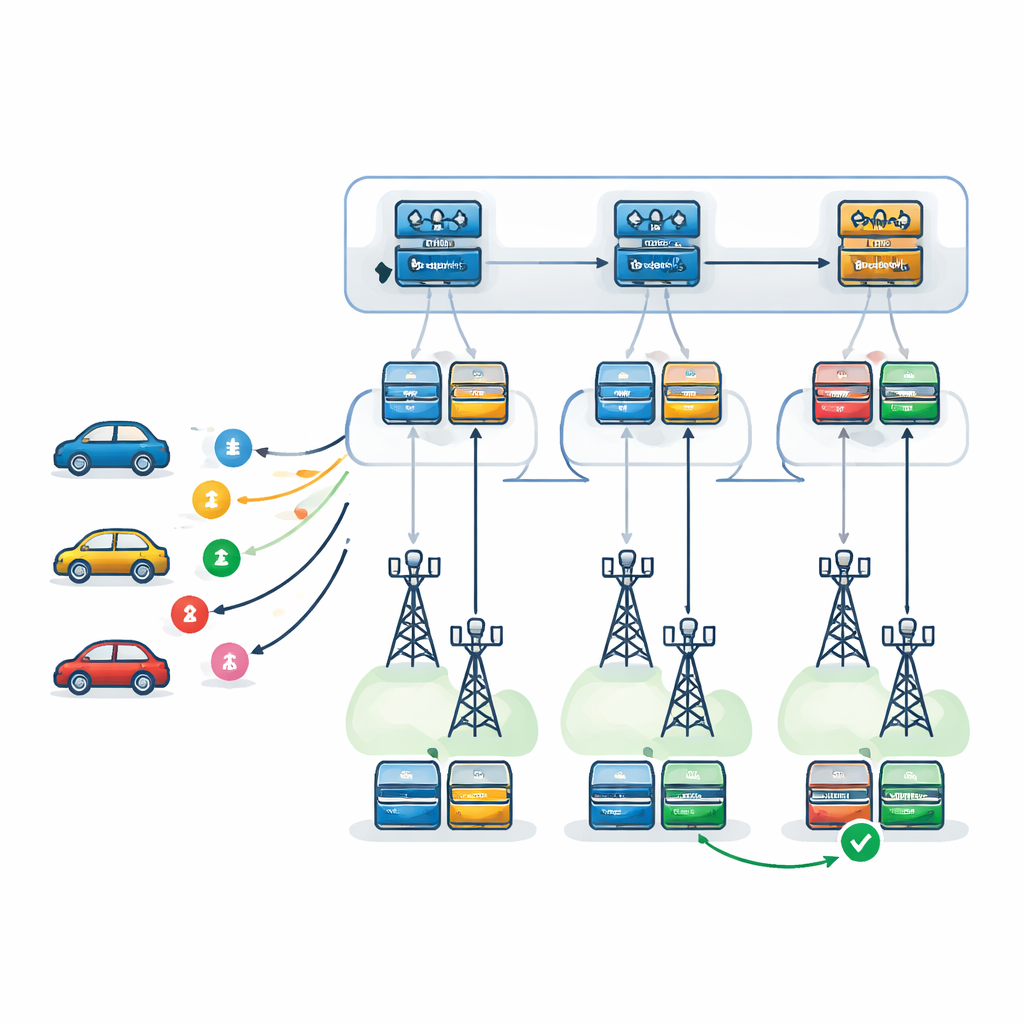
בדיקת המערכת בעיר וירטואלית
כדי לבדוק עד כמה הסידור הדו-רמתי הזה עובד, החוקרים בנו סימולטור מפורט שמקשר מערכת תנועה (SUMO) עם מנוע מבוסס-אירועים (SimPy). זה איפשר למודל רכבים נעים, תנאי אלחוט משתנים ותורי המתנה ריאליסטיים בשרתי קצה וענן. הם השוו את שיטתם בכמה חלופות: מערכת דו-רמתית דומה המשתמשת באלגוריתם למידה שונה (Proximal Policy Optimization), אסטרטגיית שלימות פשוטה שבוחרת תמיד את ה-RSU שנראה הכי טוב כרגע, סידור ללא העברה קדימה שבו מטלות מטופלות רק על ידי ה-RSU שקיבל אותן ראשונה, וסוכן למידה "שטוח" יחיד שמנסה לקבל את כל ההחלטות בבת אחת. על פני פרקים רבים ותחת עצימות תנועה שונה, הם מדדו פרסי ממוצע, עיכוב כולל וכמה פעמים מטלות נכשלו או החמיצו מועדים.
ממצאים בכבישים עמוסים
בתנועת קלות ותאריכי זמנים יחסית רפויים, רוב השיטות הופיעו זהות כי המשאבים לא נוצלו במלואם. ההבדלים הופיעו בתנועה כבדה, לא מאוזנת ובלחצי תזמון חדים — בדיוק המצבים המתוחים שהכי חשובים. בהגדרות אלו, רשת Q עמוקה דו-רמתית צמצמה כשלי מטלות בכ-29% עד 63% בהשוואה לגישות האחרות, ושיפרה את הפרס הכולל בכ-8% עד 38%. המבנה ההיררכי הוכח כסקלאבילי יותר מהסוכן השטוח ככל שמספר ה-RSU-ים והשרתים גדל, והוא נשאר חסין גם כאשר התקשורת בין RSU-ים הייתה לא אמינה במידה מסוימת או כאשר תחזיות על מסלול הרכב היו לא מדויקות.
מה זה אומר לנהגים בחיי היומיום
במלים פשוטות, המחקר מראה שלתת לרשת הכבישים "מוח" שכבותי יכול להפוך רכבים מחוברים ואוטונומיים ליותר תגובתיים ומהימנים. על ידי בחירה ראשונית של יחידת צד-דרך נכונה לכל מטלה ולאחר מכן תכנון איך המטלה תשרוד עיכובים וכשלים, המערכת שומרת על זמני תגובה נמוכים ומעלה את הסבירות שהתשובות יגיעו לפני שיהיה מאוחר מדי. בעוד שהפריסה בעולם האמיתי תצטרך עדיין להתמודד עם תנאים מבולגנים ושיקולי בטיחות, עבודה זו מציבה נתיב לתשתית דיגיטלית חכמה וחסינת-שגיאות שיכולה לעמוד בדרישות החישוביות הגוברות של רכבי העתיד.
ציטוט: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
מילות מפתח: מחשוב קצה רכבי, ניתוב מטלות, למידה עמוקה מחזקת-תגמול, חסינות לשגיאות, מ מערכות תחבורה חכמות