Clear Sky Science · pl
Dwupoziomowe, uwzględniające mobilność podejście uczenia wzmacniającego do bezawaryjnego wyłączania zadań w obliczeniach brzeżno-chmurowych pojazdów
Inteligentniejsze drogi dla samochodów łaknących danych
Nowoczesne samochody stają się jeżdżącymi komputerami, nieustannie przetwarzającymi strumienie z kamer, dane z czujników i informacje nawigacyjne. Większość tych obliczeń musi odbywać się w milisekundach, by zapewnić bezpieczeństwo kierowców i płynność usług. Artykuł bada, jak uczynić to obliczanie w czasie rzeczywistym bardziej niezawodnym i szybszym poprzez koordynację miejsca wykonywania „cyfrowych obowiązków” pojazdu — w samochodzie, w małych komputerach przy drodze lub w odległych serwerach w chmurze — nawet gdy ruch jest duży, połączenia niestabilne, a urządzenia okazjonalnie zawodzą.
Dlaczego samochody potrzebują wsparcia od drogi
Współczesne pojazdy połączone i autonomiczne uruchamiają zadania takie jak wykrywanie obiektów, utrzymanie pasa ruchu czy wskazówki z rozszerzoną rzeczywistością. Wykonanie tego wszystkiego wyłącznie wewnątrz pojazdu wymagałoby wydajnego sprzętu i dużego zużycia energii. Vehicular Edge Cloud Computing (VECC) rozwiązuje ten problem, pozwalając samochodom przekazywać wymagające zadania do Roadside Units (RSU) — małych stacji obliczeniowych przy drodze — które mogą współpracować z większymi serwerami chmurowymi. Jednak takie rozwiązanie napotyka praktyczne trudności: pojazdy szybko przemieszczają się między RSU, łącza bezprzewodowe bywają przerywane, a zarówno urządzenia brzegowe, jak i chmurowe mogą zostać przeciążone lub ulec awarii. Te czynniki razem mogą powodować długie opóźnienia lub całkowite niepowodzenie zadań, co jest niedopuszczalne dla aplikacji krytycznych czasowo.
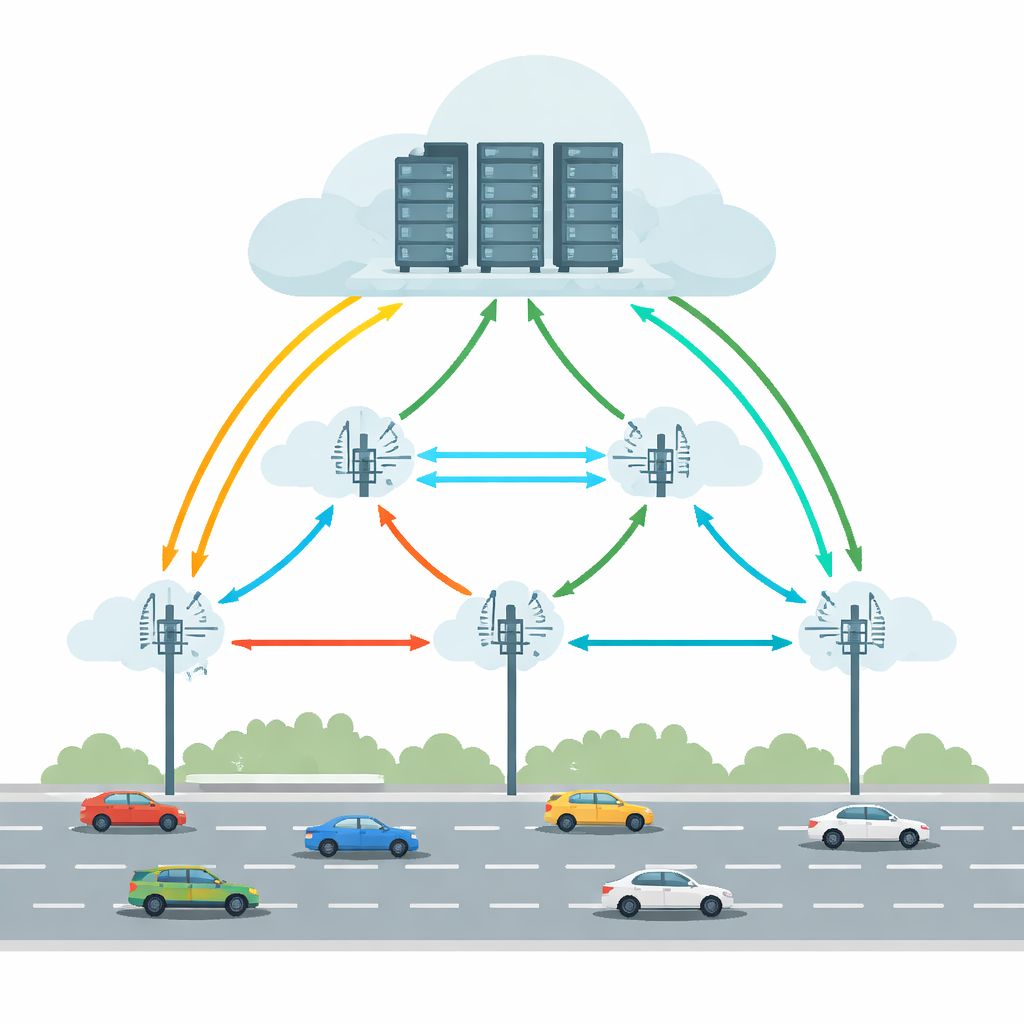
Równoważenie ruchu, opóźnień i awarii
Wiele wcześniejszych systemów starało się poprawić offloading poprzez przewidywanie pozycji pojazdu, minimalizowanie opóźnień lub oszczędzanie energii. Zwykle jednak traktowały niezawodność jako sprawę drugorzędną i często zakładały stabilne warunki. Rzeczywiste drogi są bardziej złożone: łącza bezprzewodowe mogą zanikać, serwery ulegać awarii, a wzorce ruchu zmieniać się nagle. Autorzy wskazują, że praktyczne rozwiązanie musi jednocześnie uwzględniać mobilność pojazdów, opóźnienia sieci i ryzyko awarii na wielu RSU. Powinno też unikać pojedynczego centralnego „mózgu”, który staje się wąskim gardłem wraz ze wzrostem sieci drogowej. Zamiast tego podejmowanie decyzji powinno być rozproszone, z jednostkami lokalnymi zdolnymi do szybkiej reakcji, uczącymi się jednocześnie na podstawie szerszego systemu.
Dwuwarstwowe „mózgi uczące” przy drodze
Autorzy proponują dwupoziomowe ramy decyzyjne oparte na Deep Q-Networks, rodzaju głębokiego uczenia ze wzmocnieniem uczącego się przez próbę i błąd. Na pierwszym poziomie agent uczący się — replikowany przy każdym RSU — wybiera, które RSU jest najbardziej odpowiednie do obsługi nadchodzącego zadania. Bierze pod uwagę obciążenie każdego RSU, jego moc obliczeniową, skłonność do awarii oraz przewidywaną trasę pojazdu, a także czas potrzebny na przesłanie wyników z powrotem wzdłuż tej trasy. Na drugim poziomie, po wybraniu RSU, agent lokalny decyduje, jak dokładnie wykonać zadanie: który serwer ma być podstawowy, który ma pełnić rolę zapasową i jaki wzorzec odzyskiwania po awarii zastosować. Rozważane są trzy strategie: ponawianie na tym samym serwerze, przełączenie na serwer zapasowy po awarii lub uruchomienie podstawowego i zapasowego równolegle i zaakceptowanie tego, który zakończy się pierwszy.
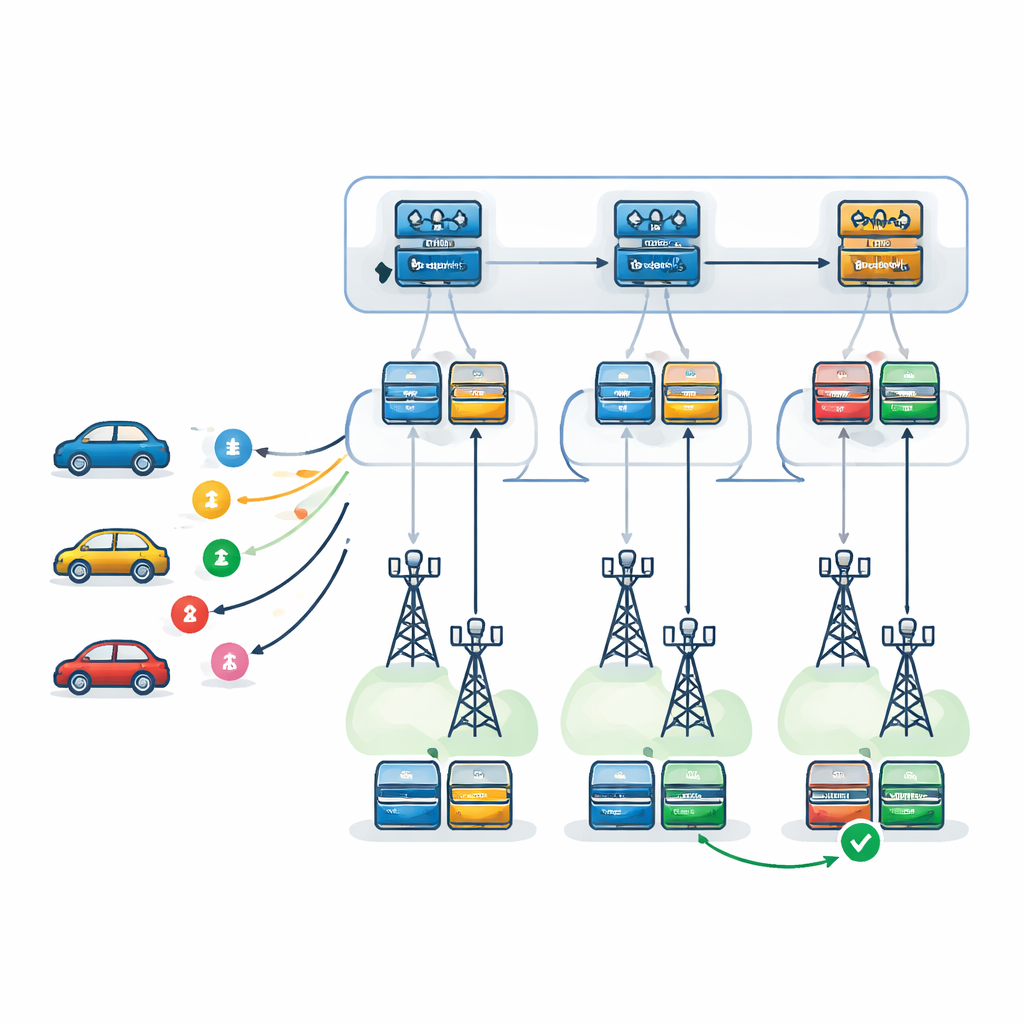
Testy systemu w wirtualnym mieście
Aby ocenić, jak działa to dwupoziomowe rozwiązanie, badacze zbudowali szczegółowy symulator łączący system ruchu (SUMO) z silnikiem zdarzeń (SimPy). Pozwoliło to modelować poruszające się pojazdy, zmieniające się warunki bezprzewodowe i realistyczne kolejki przy serwerach brzegowych i chmurowych. Porównali swoją metodę z kilkoma alternatywami: podobnym dwupoziomowym systemem używającym innego algorytmu uczenia (Proximal Policy Optimization), prostą zachłanną strategią zawsze wybierającą pozornie najlepsze RSU w danym momencie, konfiguracją bez przekazywania zadań, gdzie zadania obsługuje tylko RSU, które je jako pierwsze otrzymało, oraz płaskim agentem uczącym się próbującym podejmować wszystkie decyzje naraz. W wielu epizodach i przy różnych natężeniach ruchu mierzyli średnie nagrody, całkowite opóźnienia oraz częstość występowania awarii zadań lub niezdążenia przed upływem terminu.
Co pokazują wyniki na zatłoczonych drogach
Przy małym natężeniu ruchu i dość luźnych terminach większość metod działała podobnie, ponieważ zasoby były niewystarczająco wykorzystane. Różnice pojawiły się przy silnym, niezrównoważonym ruchu i ostrzejszych ograniczeniach czasowych — właśnie w tych stresujących sytuacjach, które są najważniejsze. W takich warunkach dwupoziomowy Deep Q-Network zmniejszył liczbę niepowodzeń zadań o około 29%–63% w porównaniu z innymi podejściami i poprawił ogólną nagrodę o około 8%–38%. Struktura hierarchiczna okazała się bardziej skalowalna niż płaski agent w miarę wzrostu liczby RSU i serwerów, i pozostała odporna nawet wtedy, gdy komunikacja między RSU była częściowo zawodna lub gdy przewidywania dotyczące przyszłej trasy pojazdu były niedokładne.
Co to oznacza dla codziennych kierowców
Mówiąc prościej, badanie pokazuje, że nadanie sieci drogowej wielowarstwowego „mózgu uczącego się” może uczynić pojazdy połączone i autonomiczne bardziej responsywnymi i niezawodnymi. Poprzez najpierw wybór odpowiedniej jednostki przydrożnej dla każdego zadania, a następnie zaplanowanie, jak zadanie powinno przetrwać opóźnienia i awarie, system utrzymuje niskie czasy reakcji i zwiększa szansę, że odpowiedzi dotrą na czas. Chociaż wdrożenie w świecie rzeczywistym nadal będzie wymagać radzenia sobie z chaotycznymi warunkami i kwestiami bezpieczeństwa, ta praca wskazuje drogę ku inteligentniejszej, odporniejszej infrastrukturze cyfrowej, która będzie nadążać za rosnącymi potrzebami obliczeniowymi przyszłych samochodów.
Cytowanie: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
Słowa kluczowe: vehicular edge computing, task offloading, deep reinforcement learning, fault tolerance, intelligent transportation systems