Clear Sky Science · ar
نهج تعلم تعزيز عميق ثنائي المستويات واعٍ بالحركة لتحميل المهام بتحمل الأخطاء في الحوسبة الحافة-السحابة للمركبات
طرق أذكى للسيارات النهمة للبيانات
تتحول السيارات الحديثة إلى حواسيب متحركة، تعالج باستمرار لقطات الكاميرا وبيانات المستشعرات ومعلومات الملاحة. يجب أن يحدث الكثير من هذه المعالجة في غضون ميلي ثانية للحفاظ على سلامة السائقين واستجابة الخدمات. تستكشف هذه الورقة كيفية جعل الحوسبة الآنية أكثر موثوقية وسرعة عبر تنسيق مكان تنفيذ "المهام الرقمية" للمركبة — داخل السيارة أو على حواسب صغيرة بجانب الطريق أو على خوادم سحابية بعيدة — حتى عندما يزدحم الطريق، وتكون الاتصالات مضطربة، وتتعطل الأجهزة أحيانًا.
لماذا تحتاج السيارات مساعدة من الطريق
تشغل المركبات المتصلة والذاتية القيادة اليوم مهامًا مثل اكتشاف الأجسام، الحفاظ على المسار، والإرشاد المعزز بالواقع. تنفيذ كل ذلك داخل السيارة وحدها سيتطلب عتادًا قويًا واستهلاك طاقة كبيرًا. تعالج حوسبة الحافة السحابية للمركبات (VECC) هذا عن طريق السماح للسيارات بتحميل المهام المكثفة إلى وحدات جانبية على جانب الطريق (RSUs) — محطات حوسبة صغيرة على طول الطريق — والتي يمكنها بدورها التعاون مع خوادم سحابية أكبر. لكن هذا الترتيب يواجه صعوبات عملية: تنتقل السيارات بسرعة بين وحدات RSU، وتتقلب الروابط اللاسلكية، ويمكن أن تُثقل أو تتعطل وحدات الحافة والسحابة. معًا، يمكن أن تتسبب هذه العوامل في تأخيرات طويلة أو فشل تام للمهام، وهو أمر غير مقبول للتطبيقات الحرجة زمنياً في القيادة.
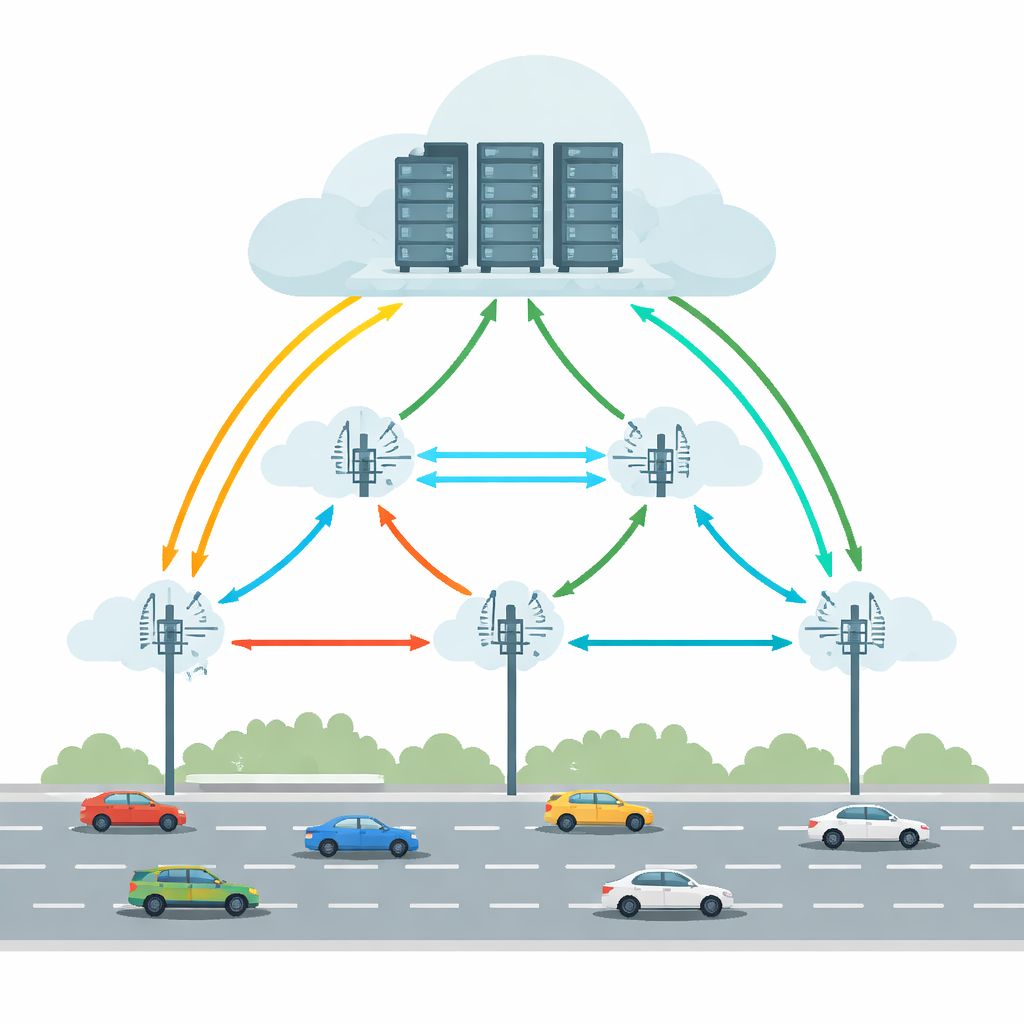
موازنة الحركة والتأخيرات والأخطاء
حاولت أنظمة سابقة تحسين التحميل عبر التنبؤ بمكان السيارة، تقليل التأخير، أو توفير الطاقة. ومع ذلك، كانت الموثوقية غالبًا تفصيلًا ثانويًا وكان الافتراض السائد ظروفًا مستقرة. الطرق الحقيقية أكثر فوضوية: قد تنقطع الروابط اللاسلكية، وقد تفشل الخوادم، وقد تتغير أنماط المرور فجأة. تؤكد هذه الورقة أن الحل العملي يجب أن ينظر إلى حركة المركبات، وتأخيرات الشبكة، ومخاطر الفشل معًا، عبر وحدات RSU متعددة. كما يحتاج أن يتجنب "مخ مركزية" واحدة تصبح عنق زجاجة مع نمو شبكة الطرق. بدلاً من ذلك، ينبغي أن تكون عملية اتخاذ القرار موزعة، مع وحدات محلية يمكنها الاستجابة بسرعة مع الاستفادة من التعلم من النظام الأوسع.
عقول تعلم ثنائية المستوى على طول الطريق
يقترح المؤلفون إطار قرار ثنائي المستوى مدفوعًا بشبكات Q العميقة، نوع من التعلم المعزز العميق الذي يتعلم بالتجربة والخطأ. على المستوى الأول، يختار وكيل متعلم — مكرر عند كل RSU — أي وحدة RSU هي الأنسب لمعالجة كل مهمة واردة. يأخذ ذلك في الحسبان حمل كل RSU، وقوة المعالجة، وميول الفشل، والمسار المتوقع للمركبة، فضلاً عن الوقت اللازم لإرجاع النتائج على طول ذلك المسار. على المستوى الثاني، بمجرد اختيار RSU، يقرر وكيل محلي كيفية تنفيذ المهمة بدقة: أي خادم يجب أن يكون رئيسيًا، وأي واحد كنسخة احتياطية، وأي نمط استعادة من الفشل يستخدم. تُدرس ثلاث استراتيجيات: إعادة المحاولة على نفس الخادم، التحول إلى خادم احتياطي بعد الفشل، أو تشغيل الأساسي والاحتياطي بالتوازي والاحتفاظ بالنتيجة التي تنتهي أولاً.
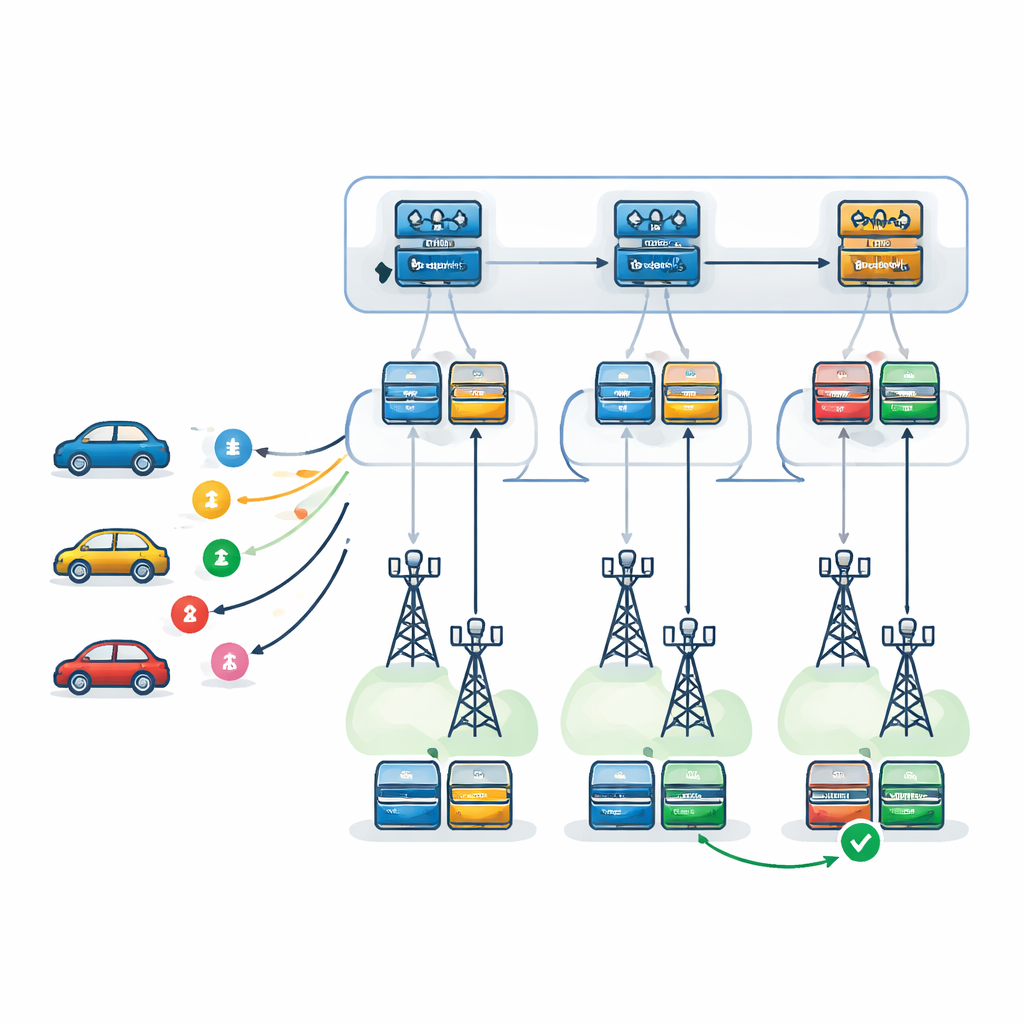
اختبار النظام في مدينة افتراضية
للاطلاع على أداء هذا الترتيب المتعلم ثنائي المستوى، بنى الباحثون محاكيًا مفصلاً يربط نظام حركة مرورية (SUMO) بمحرك أحداث مبني (SimPy). أتاح لهم ذلك نمذجة المركبات المتحركة، والظروف اللاسلكية المتغيرة، والطوابير الواقعية في خوادم الحافة والسحابة. قارنوا طريقتهم بعدة بدائل: نظام ثنائي المستوى مشابه يستخدم خوارزمية تعلم مختلفة (Proximal Policy Optimization)، واستراتيجية جشعة بسيطة تختار دائمًا RSU الأوضح في اللحظة، وترتيب عدم إعادة التوجيه حيث تُعالَج المهام فقط بواسطة RSU التي استقبلتها أولاً، ووكيل تعلم "مسطح" واحد يحاول اتخاذ كل القرارات دفعة واحدة. عبر حلقات كثيرة وتحت كثافات مرور مختلفة، قاسوا المكافآت المتوسطة، والتأخير الإجمالي، ومدى تكرار فشل المهام أو تفويت مواعيدها النهائية.
ماذا تُظهر النتائج على الطرق المزدحمة
في ظل حركة خفيفة ومواعيد نهائية متساهلة إلى حد ما، أدت معظم الطرق أداءً متقاربًا لأن الموارد كانت غير مستغلة. ظهرت الفروقات في ظل حركة كثيفة وغير متوازنة وقيود زمنية أشد — بالضبط الحالات المجهدة والمهمة. في تلك الإعدادات، خفّضت شبكة Q العميقة ثنائية المستوى فشل المهام بنحو 29٪ إلى 63٪ مقارنة بالنهج الأخرى، وحسّنت المكافأة الإجمالية بحوالي 8٪ إلى 38٪. أثبت الهيكل الهرمي أنه أكثر قابلية للتوسع من المتعلم المسطح مع زيادة عدد وحدات RSU والخوادم، وبقي قويًا حتى عندما كانت الاتصالات بين RSU غير موثوقة إلى حد ما أو عندما كانت التنبؤات بمسار المركبة المستقبلية غير دقيقة.
ماذا يعني هذا للسائقين في الحياة اليومية
بعبارة بسيطة، تظهر الدراسة أن منح شبكة الطريق "عقلًا" طبقيًا متعلمًا يمكن أن يجعل المركبات المتصلة والذاتية أكثر استجابة واعتمادية. عبر اختيار وحدة الطريق المناسبة لكل مهمة ثم التخطيط لكيفية تمكن تلك المهمة من مقاومة التأخير والأخطاء، يحافظ النظام على أوقات استجابة منخفضة ويزيد فرصة وصول الإجابات قبل فوات الأوان. بينما سيظل النشر الحقيقي بحاجة للتعامل مع ظروف فوضوية ومخاوف السلامة، يرسم هذا العمل مسارًا نحو بنية تحتية رقمية أذكى ومتسامحة مع الأخطاء يمكنها مواكبة الطلب الحوسبي المتنامي للسيارات المستقبلية.
الاستشهاد: Babaiyan, V., Bushehrian, O. & Javidan, R. A bi-level mobility-aware deep reinforcement learning approach for fault-tolerant task offloading in vehicular edge-cloud computing. Sci Rep 16, 11703 (2026). https://doi.org/10.1038/s41598-026-45763-z
الكلمات المفتاحية: الحوسبة الحافة للمركبات, تحميل المهام, التعلم المعزز العميق, تحمل الأخطاء, أنظمة النقل الذكية